sklearn--模型的评价
sklearn.metrics
1.MSE(均方误差)和RMSE(均方根误差),以及score()
lr.score(test_x,test_y)#越接近1越好,负的很差 from sklearn.metrics import mean_squared_error mean_squared_error(test_y,lr.predict(test_x))#mse np.sqrt(mean_squared_error(test_y,lr.predict(test_x)))
from sklearn.metrics import accuracy_score print(accuracy_score(predict_results, target_test))
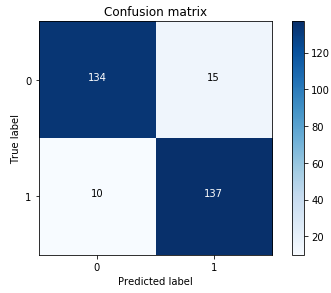
2.混淆矩阵
混淆矩阵的每一列代表了预测类别 ,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目:如下图,第一行第一列中的43表示有43个实际归属第一类的实例被预测为第一类,同理,第二行第一列的2表示有2个实际归属为第二类的实例被错误预测为第一类。
cnf_matrix = confusion_matrix(y_test_undersample,y_pred_undersample)
import seaborn as sns
sns.heatmap(cnf_matrix,cmap="Blues",annot=True,fmt='d',square=True)
plt.ylabel('True Label')
plt.xlabel('pre Label')
plt.title('Confusion matrix')
学习曲线
通过观察训练集和测试集的得分来看两个曲线的靠近程度,如果是两个曲线的方差太大,测试集差训练集好,则说明是过拟合,如果两个曲线方差不太大,两个的训练的效果都不好,这就说明是欠拟合
from sklearn.model_selection import learning_curve #绘制学习曲线,以确定模型的状况
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
train_sizes=np.linspace(.1, 1.0, 5)):
"""
画出data在某模型上的learning curve.
参数解释
----------
estimator : 你用的分类器。
title : 表格的标题。
X : 输入的feature,numpy类型
y : 输入的target vector
ylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点
cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
"""
plt.figure()
train_sizes, train_scores, test_scores = learning_curve( estimator, X, y, cv=5, n_jobs=1, train_sizes=train_sizes,scoring='neg_mean_squared_error')
train_scores=np.sqrt(-train_scores)
test_scores=np.sqrt(-test_scores)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score")
plt.xlabel("Training examples")
plt.ylabel("Score")
plt.legend(loc="best")
plt.grid("on")
if ylim:
plt.ylim(ylim)
plt.title(title)
plt.show() #少样本的情况情况下绘出学习曲线

 浙公网安备 33010602011771号
浙公网安备 33010602011771号