前端也能做AI
殷圣魁 58架构师 7月16日
前言
相信不少人看过一篇人工智能已经能实现自动编写HTML,CSS的文章,人工智能开始取代前端的一部分工作。前端开发行业真的被人工智能取代吗?
1、人工智能发展确实速度惊人,但是前端开发行业技能繁杂,要完全取代还为时过早。
2、然而人工智能和前端开发行业却能达到双赢!人工智能帮助前端工程师完成了大量枯燥和固化的工作,工程师们将有更多时间,在人工智能还不能做到的交互等领域钻研,提升自己的技能。就是说,人工智能加速了前端开发的发展,将成就技术更加精湛的程序员们。
AI在前端领域的发展

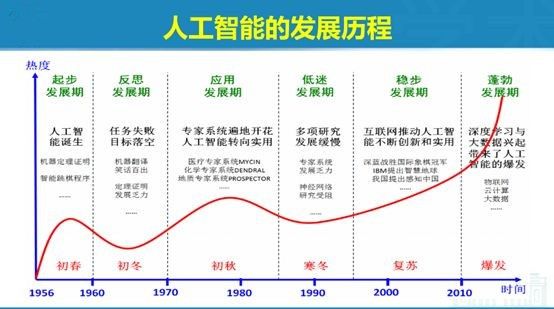
人工智能也可以称其为机器智能,其概念最初是在20世纪50年代中期Dartmouth学会上提出的。人工智能在近几年的突破巨大,主要体现在几个方面:
第一个是硬件的突破
第二个是算法的突破
第三个是大数据的存储
这三件事促使了现在机器学习的领域一次又一次大的爆炸。硬件最大的变化就是对GPU的使用越来越频繁。人工智能深度学习的函数、公式内部涉及的是大量的浮点运算。这些函数在GPU出现之后,有大量的浮点运算就交给GPU。事实上,深度学习在GPU上的执行效率可能是在CPU上的30~50倍。GPU也给机器学习带来了巨大的促进作用。
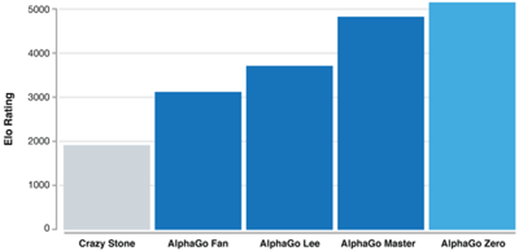
(http://www.sohu.com/a/199792158_170823)
2016年3月阿尔法狗战胜李世石。
2017年10月最新版本的阿尔法围棋名叫AlphaGo Zero,它以89:11的战绩打败了AlphaGo Master;在2017年5月刚刚战胜了柯洁。
AlphaGoZero用的是无监督学习,而Master用的则是监督学习的方法。
那么近年来同样火热的前端开发,在人工智能时代能做些什么呢?
比如我们现在要纯前端做人脸识别,trackingjs(前端人脸识别框架,是使用js封装的一个框架,非机器学习);识别的好坏完全依赖库本身的性能;最好的方案就是引入机器学习。
AI在前端领域的发展
在2017年,一个叫做DeepLearning.js的工程诞生了,旨在没有API的干扰下在JavaScript中推动ML/DL的发展;但是又出现了速度的问题。都知道JS代码不能运行在GPU上。为了解决这个问题,引进WebGL。
2018年3月,TensorFlow.js发布!前端也可以进行机器学习啦!Google的TensorFlow团队发布等待多时的JavaScript框架,TensorFlow.js(之前也叫做DeepLearn.js);TensorFlow.js提供两样东西:CoreAPI,来处理底层代码,在CoreAPI之上编写的LayerAPI,通过增加层级的抽象性使coding更容易。用户可以完全在浏览器定义、训练和运行机器学习模型。
目前AI在前端领域的一些应用案例有:
-
人脸识别
-
人脸比对
-
物体检测
-
手势检测
-
视频跟踪
-
图像美化
-
人工智能已经能实现自动编写 HTML 和 CSS
https://blog.csdn.net/csdnnews/article/details/79372975
……
基于 JavaScript 的机器学习实例
实例1:(利用TensorFlow.js部署简单的AI版「你画我猜」)
一个简单的工具来识别手绘图像,并且输出当前图像的名称。该应用无需安装任何额外的插件,可直接在浏览器上运行。作者使用谷歌 Colab 来训练模型,并使用 TensorFlow.js 将它部署到浏览器上。

实例2:(浏览器中实时人体姿势估计)
TensorFlow.js版本的PoseNet,这是一种机器学习模型,允许在浏览器中进行实时人体姿势估计。PoseNet运行在TensorFlow.js上,任何拥有摄像头的PC或手机的人都可以在网络浏览器中体验这种技术。而且由于已经开源了这个模型,JavaScript开发人员可以用几行代码来使用这个技术。更重要的是,这实际上可以帮助保护用户隐私。由于TensorFlow.js上的PoseNet在浏览器中运行,因此任何姿态数据都不会留在用户的计算机上。

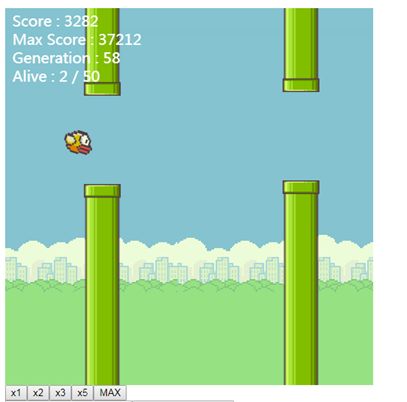
实例3:(Flappy-bird )
FlappyLearning 是一个仅用800 行代码创建的 JavaScript 机器学习库,它让你可以像行家一样玩转 Flappy Bird 游戏。在这个库中所使用的 AI 技术被称为“ Neuroevolution” 神经进化,而它所应用算法的灵感则源于自然界生物神经系统的进化,并且它可以从每次成功或失败的迭代中进行动态的学习。另外,你只需要在浏览器中打开 index.html 就可以运行它了,非常简单。
前端机器学习框架
使用JavaScript 可以运行在浏览器和服务器端、甚至是桌面程序上。目前已经有不少简洁的库,可以将JavaScript、机器学习、DNN 甚至 NLP结合在一起,而且在浏览器端大多库会调用 WebGL 来做机器学习的计算。
(https://baijiahao.baidu.com、https://www.colabug.com/4857625.html)
**1.TensorFlow.js **(https://js.tensorflow.org/)
TensorFlow.js 是一个开源的基于硬件加速的 JavaScript 的库,支持在浏览器或者 NodeJs 中来运行深度学习,并且能支持现有的 Tensorflow 模型,由Google出品。可以说是前端深度学习框架 Deeplearn.js 的继任者。它提供一系列简洁和通俗易懂的API,用于训练、部署模型。而且因为可以运行在浏览器,所以可以直接通过URL就能分享你的程序:

通过摄像头来控制的吃豆人游戏
2. Brain.js (https://brain.js.org/)
Brain.js 是同样可以运行在浏览器和 NodeJs 服务器端、能为不同的任务提供不同类型的训练网络。特点是让定义、训练以及执行神经网络变得特别简单。个人觉得这个库比较适合入门。比如以下短短几行代码已涵盖创建、训练和执行神经网络,一目了然:
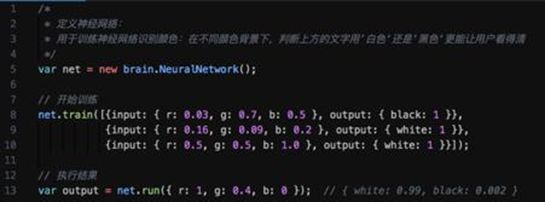

Brain.js 的色彩识别器
**3. Synaptic.js **(http://caza.la/synaptic)
Synaptic 可以运行在浏览器和 NodeJs 服务器端的神经网络库,你能够用它训练一层甚至是二层神经网络结构。该库包括一些内置的体系结构,如多层感知机(MLP)、长短时记忆网络、液体状态机和能够训练真实网络的训练器。

Synaptic image-filter perceptron
4. Machine learning tools (https://github.com/mljs/ml)
Machine Learning tools 是由 mljs组织开发的一组库,可以为 JavaScript 提供机器学习工具,包括监督和非监督学习、人工神经网络 (ANN)、回归算法,用于统计、数学等的支持库,类似于 Python 中的 scikit-learn。

**5. compromise **(http://compromise.cool/)
基本上是NLP自然语言处理库 - 前端 JavaScript 实现的首选,这个库加上自己的资料库压缩成min.js后文件大小可达到300k以下,这样运行在浏览器和 NodeJs 服务器端都问题不大,具体可以做的东西是训练自定义语义库:划分出分词,获取句子的各个词性,可以把句子变积极消极、分词等,比如以下例子:
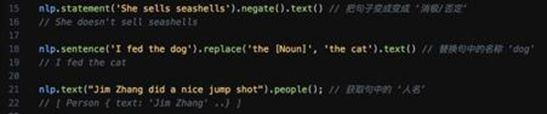
JavaScript 虽然不是机器学习的最佳编程语言,不过随着 Web生态 和 人工智能技术近年来的不断发展完善,越来越多这样的机器学习工具库被研发和发布。对于一名Web的前端开发者而言,用 JavaScript 作为入门机器学习的桥梁是个不错的选择,它同样能帮助你开启机器学习之旅。
前端在机器学习方面的优缺点
优势:
① 从用户的角度来看,在浏览器中运行的ML意味着不需要安装任何库或驱动程序。只需打开网页,你的程序就可以运行了。
② 此外,基于框架TensorFlow.js,它已准备好使用GPU加速运行。TensorFlow.js自动支持WebGL,并在GPU可用时会加速代码。用户也可以通过移动设备打开你的网页,在这种情况下,模型可以利用传感器数据,例如陀螺仪或加速度传感器。一般来说,深层神经网络计算在GPU上运行的速度要比CPU快一个数量级。
③ 所有数据都保留在客户端上,可以实现低延迟推理以及隐私保护程序。
④ 在浏览器中完全由客户端运行的机器学习程序将会解锁新的机会,如交互式机器学习:https://github.com/tensorflow/tfjs-examples。
⑤ 离线学习,用浏览器中收集的少量数据进行离线训练。这是快速训练精确模型的一种方法,只需使用少量数据。
障碍:
① 模型学习时前端计算能力障碍
浏览器及移动端有限的资源计算能力:由于模型的深度学习很难直接在浏览器中运行,因为这些模型不是专为在浏览器中运行而设计的,更不用说在移动端了。以现有的物体探测器为例:它们通常需要大量的计算资源才能以合理的fps运行,更不用说以实时速度运行了。
② 预训练模型加载到前端时等待时间较长障碍
在简单的Web应用程序中将几十兆至上百兆预训练模型权重加载到客户端浏览器是非常耗时的。这对于用户是无法接受的。
但是,随着JS引擎的计算能力不断增强,人工智能领域的不断发展,可以预见的是,在不久的将来,肯定能有一些简单的算法可以被移植到用户前端执行,这样既能减少请求,又能分担后端压力,。这一切并不是无稽之谈,为什么tensorflow.js会应运而生,正是因为JS的社区在不断壮大,JS这款便捷的语言也在得到更为普遍的使用。
这些问题正在得到解决和改善:
针对计算能力问题:(https://www.jianshu.com/p/e5f997713a4b)
前端做算法能落实到生产环境吗?能真正地给业务带来价值吗?答案是:可以!首先先说一下前端目前可以进行高性能计算的三种方法:
-
asm.js
-
WebAssembly
-
GPU
所以,opencv就有了asm.js和WebAssembly版本的,我们可以在前端做cv算法。什么物体跟踪、图像处理、特征检测等等等,在前端做ok的,并且阿里也落地到了生产环境中。以及谷歌去年推出tensorflow.js支持利用gpu计算。
针对模型大小问题:
模型压缩,以及为Web训练高效的深度学习模型
(1)2018年09月;腾讯 AI Lab 开源世界首款自动化模型压缩框架PocketFlow
(http://www.elecfans.com/d/778282.html)
这是一款面向移动端AI开发者的自动模型压缩框架,集成了当前主流的模型压缩与训练算法,结合自研超参数优化组件实现了全程自动化托管式的模型压缩与加速。开发者无需了解具体算法细节,即可快速地将AI技术部署到移动端产品上,实现用户数据的本地高效处理。
(2)模型压缩开源库整理:
(https://blog.csdn.net/daniaokuye/article/details/82746661?utm_source=blogxgwz9)

(3)谷歌MobileNet
一般的tensorflow模型动辄几百兆,在前端怎么跑呢?没关系,我们有MobileNet啊,MobileNet是针对于移动端模型提出的神经网络架构,能极大地减少模型参数量,同理也能用到浏览器端上。
(4)为Web训练高效的深度学习模型(https://www.jianshu.com/p/ef7e1c3f5aea)
这些模型通过设计一些基本原则可以在Web环境中运行进行。我们可以训练相当不错的图像分类-甚至物体检测模型,最终只有几兆字节大小甚至只有几千字节:

如通过增加每层卷积滤波器的数量或堆叠更多层简单地使你的网络更深入。
前端基于现有框架进行模型训练
用TensorFlow.js我们可以做什么?
TensorFlow 是GitHub 上的第一个机器学习平台,也是 GitHub 上的五大软件库之一,被许多公司和组织所使用,包括 GitHub 上与 TensorFlow 相关的超过 24,500 个不同的软件仓库。预编译的 TensorFlow 二进制文件已经在 180 多个国家被下载了超过 1000 万次,GitHub 上的源代码现在已经有超过 1200 个贡献者。
2018年3月31日TensorFlow 开发者峰会上,TensorFlow宣布重大更新:增加支持Java,并推出开源库TensorFlow.js,
如果你使用TensorFlow.js进行开发,可以考虑以下三种workflow:
· 你可以导入现有的预训练的模型进行推理。如果你有一个以前脱机训练好的现成的TensorFlow或Keras模型,就可以将其转换为TensorFlow.js格式,并加载到浏览器中进行推理。
· 你可以重新训练导入的模型。正如在上面的Pac-Man演示中,你可以使用迁移学习来增强现有模型,使用“ImageRetraining”技术,用浏览器中收集的少量数据进行离线训练。这是快速训练精确模型的一种方法,只需使用少量数据。
· 直接在浏览器中创建模型。你还可以使用TensorFlow.js,完全在浏览器中使用Java和high-level layers API进行定义、训练和运行模型。如果你熟悉Keras,那么应该会很熟悉high-level layers API。
1.tensorflow在发布了JS版本的工具库后,官网在线测试:
2.Tensorflow.js 图片训练(mnist )
(https://storage.googleapis.com/tfjs-examples/mnist/dist/index.html)

3.如何利用TensorFlow.js部署简单的AI版「你画我猜」图像识别应用
在线测试地址:(https://zaidalyafeai.github.io/sketcher/)
4.交互式机器学习:
结合我们自身业务,对落地场景进行初探:AI美图

通过Tensorflowjs及converter工具将Tensorflow模型或Keras模型转换为web_model模型;可以看到生成浏览器可以加载并读取的模型参数和权重文件。从用户的角度来看,在浏览器中运行的ML意味着不需要安装任何库或驱动程序。只需打开网页,程序就可以运行了。对于图片处理来说,不需要网络开销来传输和接受图片资源,实现了低延迟,弱网或断网情况下的离线运行。
在实现过程我们也遇到了一些问题,比如由于Tensorflowjs-converter支持有限,我们训练模型时用到encode和decode;由于不在Supported Tensorflow Ops列表,我们通过调整模型训练Ops来兼容。同时也付出了一些代价,模型从44K增加到几百K。
另外,将Tensorflow模型或Keras模型转换为web_model模型之后,会生成很多小的权重文件,在实际应用时,通过懒加载和预加载策略,可以在不影响首屏加载情况下,优化模型加载时间。
总结
本篇属于调研实践型文章,旨在证明AI与前端融合的可行性及优势;通过分析业界面临障碍的探索及解决思路,给我们在前端具体业务场景中,如何结合AI优势,解决弱计算能力、模型较大等焦点难题,提供一些可行思路。也期待大家的共同参与和优秀实践。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号