
python 爬取豆瓣top250电影图片
import urllib.request import requests from lxml import html headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0' } def get_html(url): response = requests.get(url, headers=headers).text element = html.etree.HTML(response) lis = element.xpath('//ol[@class="grid_view"]')[0] return lis def get_img(lis): for li in lis: global num # 计数变量 title = li.xpath('.//span[@class="title"]/text()')[0] # 获取影片标题 img_url = li.xpath('.//img/@src')[0] # 获取封面地址 file_name = 'D:/Python/pythonProject/Spider/images' + title + str(num) + '.jpg' urllib.request.urlretrieve(img_url, filename=file_name) # 保存到本地文件中 num += 1 def main(): global num num = 1 for i in range(10): url = 'https://movie.douban.com/top250?start=' + str(25 * i) ht = get_html(url) get_img(ht) i += 1 main()
运行结果:
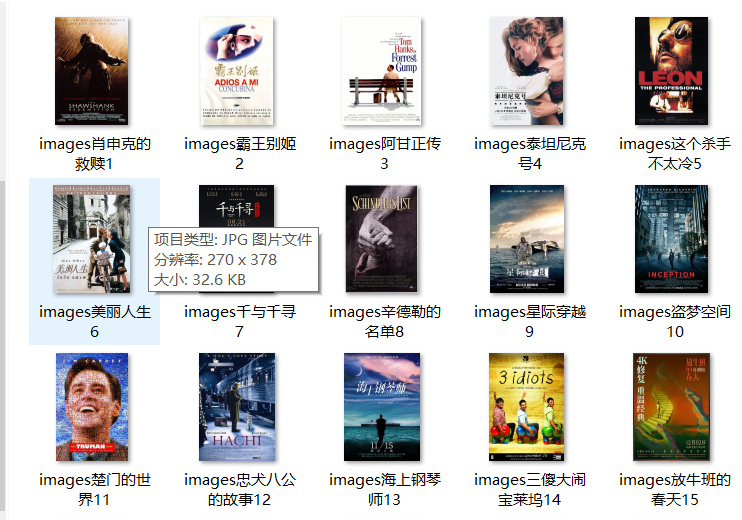
本文作者:万事胜意k
本文链接:https://www.cnblogs.com/ysk0904/p/17330075.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步