Day 70 应用工具_中间件_Redis
Redis
Reids安装
yum install -y gcc-c++ wget wget http://download.redis.io/releases/redis-4.0.8.tar.gz tar xzvf redis-4.0.8.tar.gz cd redis-4.0.8 make cd src make install PREFIX=/usr/local/redis cd ../ mkdir /usr/local/redis/etc mv redis.conf /usr/local/redis/etc # 配置后台启动 sed -i 's#daemonize no#daemonize yes#g' /usr/local/redis/etc/redis.conf # 将redis加入到开机启动 # 在里面添加内容:/usr/local/redis/bin/redis-server,意思就是开机调用这段开启redis的命令 vim /etc/rc.local /usr/local/redis/etc/redis.conf # 启动 /usr/local/redis/bin/redis-server /usr/local/redis/etc/redis.conf # 测试是否启动成功 ps -aux|grep redis # 停止 pkill redis
卸载
# 删除安装目录 rm -rf /usr/local/redis # 删除所有redis相关命令脚本 rm -rf /usr/bin/redis-* # 删除redis解压文件夹 rm -rf /root/download/redis-4.0.4
python连接Redis
报错处理
报错:redis.exceptions.ConnectionError: Error 10061 connecting to 192.168.214.14:6379. 由于目标计算机积极拒绝,无法连接。
解决:下载并安装Redis-x64-3.2.100.msi,安装地址:https://github.com/MicrosoftArchive/redis/releases
 安
安
装完成之后,双击redis-cli启动服务
基本链接方式
1、操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
import redis r = redis.Redis(host='127.0.0.1',port=6379) r.set("age",23) print(r.get('name'))
2、连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接
poor = redis.ConnectionPool(host='127.0.0.1',port=6379) r = redis.Redis(connection_pool=poor) r.set('school','ysg学院') print(r.get('school'),type(r.get('school'))) # b'ysg\xe5\xad\xa6\xe9\x99\xa2' <class 'bytes'>
redis操作
操作
1. string类型: 字符串类型是 Redis 中最为基础的数据存储类型,它在 Redis 中是二进制安全的,也就是byte类型 最大容量是512M。 2. hash类型: hash用于存储对象,对象的结构为属性、值,值的类型为string。 key:{ 域:值[这里的值只能是字符串], 域:值, 域:值, 域:值, ... } 3. list类型: 列表的元素类型为string。 key:[ 值1,值2,值3..... ] 4. set类型: 无序集合,元素为string类型,元素唯一不重复,没有修改操作。 {值1,值4,值3,值5} 5. zset类型: 有序集合,元素为string类型,元素唯一不重复,没有修改操作。
字符串操作
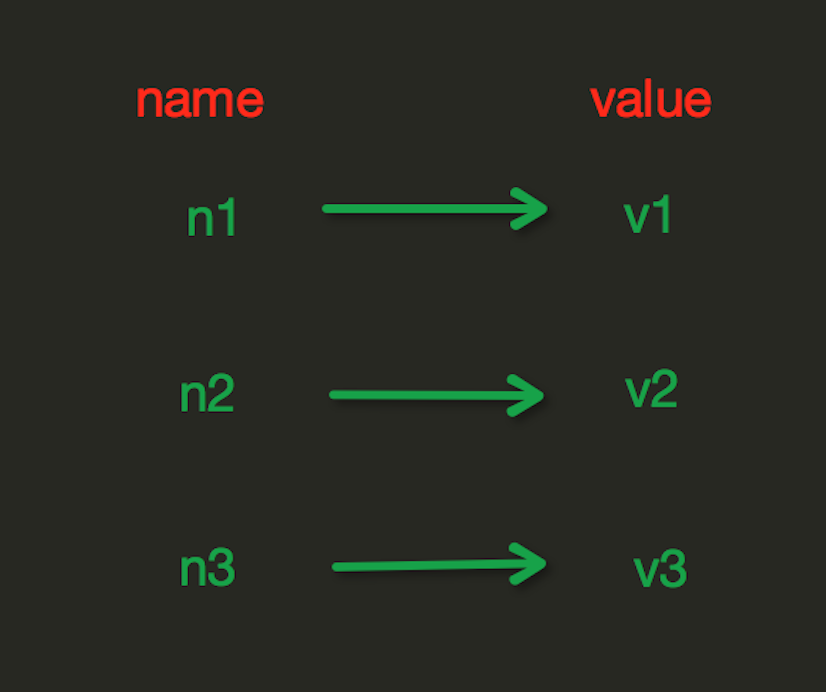
redis中的String在在内存中按照一个name对应一个value来存储。如图:
set(name, value, ex=None, px=None, nx=False, xx=False) #在Redis中设置值,默认,不存在则创建,存在则修改 #参数: # ex,过期时间(秒) # px,过期时间(毫秒) # nx,如果设置为True,则只有name不存在时,当前set操作才执行 # xx,如果设置为True,则只有name存在时,岗前set操作才执行 get(name) # 获取值
setnx(name, value)
# 设置值,只有name不存在时,执行设置操作(添加)
setex(name, time, value)
# 设置值 # 参数: # time,过期时间(数字秒 或 timedelta对象)
psetex(name, time_ms, value)
# 设置值 # 参数: # time_ms,过期时间(数字毫秒 或 timedelta对象)
mset(*args, **kwargs)
# 批量设置值 # 如: # mset(k1='v1', k2='v2') # 或 # mget({'k1': 'v1', 'k2': 'v2'})
r.mset({'k1':'v1','k2':'v2',})
print(r.mget(['k1','k2']))
# 结果
[b'v1', b'v2']
mget(keys, *args)
# 批量获取 # 如: # mget('k1', 'k2') # 或 # r.mget(['k1', 'k2'])
getset(name, value)
# 设置新值并获取原来的值
getrange(key, start, end)
# 获取子序列(根据字节获取,非字符) # 参数: # name,Redis 的 name # start,起始位置(字节) # end,结束位置(字节)
r.set('name','ysging') print(r.getrange('name',0,3)) # 结果 b'ysgi'
setrange(name, offset, value)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加) # 参数: # offset,字符串的索引,字节(一个汉字三个字节) # value,要设置的值
print(r.get('name')) r.setrange('name',2,'!!!') # 结果 b'y!!!ng'
strlen(name)
# 返回name对应值的字节长度(一个汉字3个字节)
incr(self, name, amount=1)
# 自增 name 对应的值,当 name 不存在时,则创建 name=amount,否则,则自增。 # 参数: # name,Redis 的 name # amount,自增数(必须是整数) # 注:同incrby
print(r.get('age')) r.incr('age',amount=3) print(r.get('age')) # 结果 b'24' b'27'
incrbyfloat(self, name, amount=1.0)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 # 参数: # name,Redis的name # amount,自增数(浮点型)
decr(self, name, amount=1)
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。 # 参数: # name,Redis的name # amount,自减数(整数)
append(key, value)
# 在redis name对应的值后面追加内容 # 参数: # key, redis的name # value, 要追加的字符串
print(r.get('name')) r.append('name',123) print(r.get('name')) # 结果 b'y!!!!g' b'y!!!!g123'
Hash 操作
hash表现形式上有些像pyhton中的dict,可以存储一组关联性较强的数据 , redis中Hash在内存中的存储格式如下图:

hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改) # 参数: # name,redis的name # key,name对应的hash中的key # value,name对应的hash中的value # 注: # hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
r.hset('infos', 'name', 'alex') print(r.hgetall('infos')) # 结果 {b'name': b'alex'}
hmset(name, mapping)
# 在name对应的hash中批量设置键值对 # 参数: # name,redis的name # mapping,字典,如:{'k1':'v1', 'k2': 'v2'} # 如: # r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
r.hmset('infos',{'age':'100','a2':'b2','a3':'b3','k1':'v1'}) print(r.hgetall('infos')) # 结果 {b'name': b'alex', b'age': b'100', b'a2': b'b2', b'a3': b'b3', b'k1': b'v1'}
hget(name,key)
# 在name对应的hash中获取根据key获取value
print(r.hgetall('infos')) r.hmset('infos',{'age':'100','a2':'b2','a3':'b3','k1':'v1'}) print(r.hget('infos','name')) # 结果 {b'name': b'ysg', b'age': b'100', b'a2': b'b2', b'a3': b'b3', b'k1': b'v1'} b'ysg'
hmget(name, keys, *args)
# 在name对应的hash中获取多个key的值 # 参数: # name,reids对应的name # keys,要获取key集合,如:['k1', 'k2', 'k3'] # *args,要获取的key,如:k1,k2,k3 # 如: # r.mget('xx', ['k1', 'k2']) # 或 # print r.hmget('xx', 'k1', 'k2')
print(r.hgetall('infos')) r.hmset('infos',{'age':'100','a2':'b2','a3':'b3','k1':'v1'}) print(r.hmget('infos','name','age')) # 结果 {b'name': b'ysg', b'age': b'100', b'a2': b'b2', b'a3': b'b3', b'k1': b'v1'} [b'ysg', b'100']
hgetall(name)
# 获取name对应hash的所有键值
hlen(name)
# 获取name对应的hash中键值对的个数
print(r.hlen('infos')) # 结果 5
hkeys(name)
# 获取name对应的hash中所有的key的值
print(r.hkeys('infos')) # 结果 [b'name', b'age', b'a2', b'a3', b'k1']
hvals(name)
# 获取name对应的hash中所有的value的值
print(r.hvals('infos')) # 结果 [b'ysg', b'100', b'b2', b'b3', b'v1']
hexists(name, key)
# 检查name对应的hash是否存在当前传入的key
print(r.hexists('infos','name')) print(r.hexists('infos','names')) # 结果 True False
hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
print(r.hgetall('infos')) r.hdel('infos','age') print(r.hgetall('infos')) # 结果 {b'name': b'ysg', b'age': b'100', b'a2': b'b2', b'a3': b'b3', b'k1': b'v1'} {b'name': b'ysg', b'a2': b'b2', b'a3': b'b3', b'k1': b'v1'}
hincrby(name, key, amount=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount # 参数: # name,redis中的name # key, hash对应的key # amount,自增数(整数)
print(r.hgetall('infos')) r.hincrby('infos','age',amount=3) print(r.hget('infos','age')) # 结果 {b'name': b'ysg', b'a2': b'b2', b'a3': b'b3', b'k1': b'v1', b'age': b'100'} b'103'
hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount # 参数: # name,redis中的name # key, hash对应的key # amount,自增数(浮点数) # 自增name对应的hash中的指定key的值,不存在则创建key=amount
hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据 # 参数: # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如: # for item in r.hscan_iter('xx'): # print item
print(r.hgetall('infos')) # 结果 {b'name': b'ysg', b'a2': b'b2', b'a3': b'b3', b'k1': b'v1', b'age': b'103'} for i in r.hscan_iter('infos'): print(i) # 结果 (b'name', b'ysg') (b'a2', b'b2') (b'a3', b'b3') (b'k1', b'v1') (b'age', b'103') for i in r.hscan_iter('infos',match='a*'): print(i) # 结果 (b'a2', b'b2') (b'a3', b'b3') (b'age', b'103')
redis的链表操作
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:

lpush(name,values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边 # 如: # r.lpush('oo', 11,22,33) # 保存顺序为: 33,22,11 # 扩展: # rpush(name, values) 表示从右向左操作
lrange(name, start, end)
# 在name对应的列表分片获取数据 # 参数: # name,redis的name # start,索引的起始位置 # end,索引结束位置
r.lpush('count',56,25,78,93,11) r.rpush('new_count',56,25,78,93,11) print(r.lrange('count',0,-1)) print(r.lrange('new_count',0,-1)) #结果 [b'11', b'93', b'78', b'25', b'56'] [b'56', b'25', b'78', b'93', b'11']
lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边 # 更多: # rpushx(name, value) 表示从右向左操作
print(r.lrange('count',0,-1)) r.lpushx('count',100) print(r.lrange('count',0,-1)) # 结果 [b'11', b'93', b'78', b'25', b'56'] [b'100', b'11', b'93', b'78', b'25', b'56']
llen(name)
# name对应的list元素的个数
linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值 # 参数: # name,redis的name # where,BEFORE或AFTER # refvalue,标杆值,即:在它前后插入数据 # value,要插入的数据
print(r.lrange('count',0,-1)) r.linsert('count','AFTER',93,100) print(r.lrange('count',0,-1)) # 结果 [b'100', b'11', b'93', b'78', b'25', b'56'] [b'100', b'11', b'93', b'100', b'78', b'25', b'56']
r.lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值 # 参数: # name,redis的name # index,list的索引位置 # value,要设置的值
print(r.lrange('count',0,-1)) r.lset('count',3,105) print(r.lrange('count',0,-1)) # 结果 [b'100', b'11', b'93', b'100', b'78', b'25', b'56'] [b'100', b'11', b'93', b'105', b'78', b'25', b'56']
r.lrem(name, value, num)
# 在name对应的list中删除指定的值 # 参数: # name,redis的name # value,要删除的值 # num, num=0,删除列表中所有的指定值; # num=2,从前到后,删除2个; # num=-2,从后向前,删除2个
print(r.lrange('sum',0,-1)) r.lrem('sum',count=2,value=93) print(r.lrange('sum',0,-1)) # 结果 [b'11', b'93', b'78', b'25', b'56', b'11', b'93', b'78', b'56.25'] [b'11', b'78', b'25', b'56', b'11', b'78', b'56.25']
lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素 # 更多: # rpop(name) 表示从右向左操作
print(r.lrange('sum',0,-1)) r.lpop('sum') print(r.lrange('sum',0,-1)) # 结果 [b'11', b'78', b'25', b'56', b'11', b'78', b'56.25'] [b'78', b'25', b'56', b'11', b'78', b'56.25']
lindex(name, index)
# 在name对应的列表中根据索引获取列表元素
ltrim(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值 # 参数: # name,redis的name # start,索引的起始位置 # end,索引结束位置
print(r.lrange('sum',0,-1)) r.ltrim('sum',1,4) print(r.lrange('sum',0,-1)) # 结果 [b'78', b'25', b'56', b'11', b'78', b'56.25'] [b'25', b'56', b'11', b'78']
redis的集合操作
Set操作,Set集合就是不允许重复的列表
sadd(name,values)
# name对应的集合中添加元素
smembers(name)
# 获取name对应的集合的所有成员
r.sadd('set_num',1,2,3,4,5,5) r.sadd('set_num2',1,2,3,) print(r.smembers('set_num')) print(r.smembers('set_num2')) # 结果 {b'5', b'2', b'4', b'1', b'3'} {b'2', b'1', b'3'}
scard(name)
# 获取name对应的集合中元素个数
sinter(keys, *args)
# 交集,获取多一个name对应集合的交集
print(r.sinter('set_num','set_num2')) # 结果 {b'1', b'2', b'3'}
sunion(keys, *args)
# 并集,获取多一个name对应的集合的并集
print(r.sunion('set_num','set_num2')) # 结果 {b'2', b'1', b'4', b'5', b'3'}
sdiff(keys, *args)
# 差集,在第一个name对应的集合中且不在其他name对应的集合的元素集合
print(r.sdiff('set_num','set_num2')) # 结果 {b'4', b'5'}
sismember(name, value)
# 检查value是否是name对应的集合的成员
print(r.sismember('set_num',5)) print(r.sismember('set_num',52)) #结果 True False
spop(name)
# 从集合中随机移除一个成员,并将其返回
print(r.smembers('set_num')) print(r.spop('set_num')) print(r.smembers('set_num')) # 结果 {b'5', b'2', b'3', b'1', b'4'} b'5' {b'1', b'3', b'2', b'4'}
srandmember(name, numbers)
# 从name对应的集合中随机获取 numbers 个元素
print(r.smembers('set_num')) print(r.srandmember('set_num',2)) # 结果 {b'1', b'4', b'2', b'3'} [b'4', b'3']
srem(name, values)
# 在name对应的集合中删除某些值
print(r.smembers('set_num')) r.srem("set_num",1) print(r.smembers('set_num')) # 结果 {b'1', b'4', b'3', b'2'} {b'4', b'3', b'2'}
sscan_iter(name, match=None, count=None)
# 同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
print(r.sscan_iter('set_num')) for i in r.sscan_iter('set_num'): print(i) # 结果 <generator object Redis.sscan_iter at 0x00000253D7C895C8> b'2' b'3' b'4'
Sort Set 操作
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(name, *args, **kwargs)
# 在name对应的有序集合中添加元素 # 如:print(r.zadd("zz",{"n1":1,"n2":2,"n3":3,"n4":4}))<br><br># 查看:print(r.zscan("zz"))
r.zadd('z',{"p2":2,"p1":1,"p4":4,"p5":5,"p3":3,}) print(r.zscan('z')) # 结果 (0, [(b'p1', 1.0), (b'p2', 2.0), (b'p3', 3.0), (b'p4', 4.0), (b'p5', 5.0)])
zcard(name)
# 获取name对应的有序集合元素的数量
zcount(name, min, max)
# 获取name对应的有序集合中分数 在 [min,max] 之间的个数
print(r.zscan('z')) print(r.zcount('z',1,3)) print(r.zcount('z',1,4)) # 结果 (0, [(b'p1', 1.0), (b'p2', 2.0), (b'p3', 3.0), (b'p4', 4.0), (b'p5', 5.0)]) 3 4
zincrby(name, amount, value)
# 自增name对应的有序集合的 name 对应的分数
print(r.zscan('z')) r.zincrby('z','10','p1') print(r.zscan('z')) # 结果 (0, [(b'p1', 1.0), (b'p2', 2.0), (b'p3', 3.0), (b'p4', 4.0), (b'p5', 5.0)]) (0, [(b'p2', 2.0), (b'p3', 3.0), (b'p4', 4.0), (b'p5', 5.0), (b'p1', 11.0)])
zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素 aa=r.zrange("zset_name",0,1,desc=False,withscores=True,score_cast_func=int) print(aa) ''' 参数: name redis的name start 有序集合索引起始位置 end 有序集合索引结束位置 desc 排序规则,默认按照分数从小到大排序 withscores 是否获取元素的分数,默认只获取元素的值 score_cast_func 对分数进行数据转换的函数 '''
print(r.zrange('z',0,2)) print(r.zrange('z',0,4)) # 结果 [b'p2', b'p3', b'p4'] [b'p2', b'p3', b'p4', b'p5', b'p1']
zscore(name, value)
#获取name对应有序集合中 value 对应的分数
zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始) # 更多: # zrevrank(name, value),从大到小排序
print(r.zscan('z')) print(r.zrank('z','p5')) # 结果 (0, [(b'p2', 2.0), (b'p3', 3.0), (b'p4', 4.0), (b'p5', 5.0), (b'p1', 11.0)]) 3
zrem(name, values)
# 删除name对应的有序集合中值是values的成员 # 如:zrem('zz', ['s1', 's2'])
zremrangebyrank(name, min, max)
# 根据排行范围删除
zremrangebyscore(name, min, max)
# 根据分数范围删除
zinterstore(dest, keys, aggregate=None)
# 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作 # aggregate的值为: SUM MIN MAX
r.zadd('ysg', {'n1': 1, 'n2': 1, 'x': 100}) r.zadd('ysg2', {'n3': 1, 'n4': 1, 'x': 100}) r.zinterstore('ysg4',('ysg','ysg2')) # 结果 (0, [(b'x', 200.0)])
zunionstore(dest, keys, aggregate=None)
# 获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作 # aggregate的值为: SUM MIN MAX
r.zadd('ysg', {'n1': 1, 'n2': 1, 'x': 100}) r.zadd('ysg2', {'n3': 1, 'n4': 1, 'x': 100}) r.zunionstore('ysg3', ('ysg', 'ysg2')) print(r.zscan('ysg3')) # 结果 (0, [(b'n1', 1.0), (b'n2', 1.0), (b'n3', 1.0), (b'n4', 1.0), (b'x', 200.0)])
其他常用操作
delete(*names)
# 根据删除redis中的任意数据类型
exists(name)
# 检测redis的name是否存在,返回值(0,1)
keys(pattern='*')
# 根据模型获取redis的name # 更多: # KEYS * 匹配数据库中所有 key 。 # KEYS h?llo 匹配 hello , hallo 和 hxllo 等。 # KEYS h*llo 匹配 hllo 和 heeeeello 等。 # KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
print(r.keys()) # 获取所有的键值 print(r.keys(pattern='ysg*')) # 获取 ysg 开头的键值
expire(name ,time)
# 为某个redis的某个name设置超时时间
rename(src, dst)
# 对redis的name重命名为
randomkey()
# 随机获取一个redis的name(不删除)
type(name)
# 获取name对应值的类型
scan_iter(match=None, count=None)
# 同字符串操作,用于增量迭代获取key
for i in r.scan_iter(match='ysg*'): print(i) # 结果 b'ysg2' b'ysg' b'ysg3'
使用场景
(一)String 这个其实没啥好说的,最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计数功能的缓存,比如减少库存。 (二)hash 这里value存放的是结构化的对象,比较方便的就是操作其中的某个字段。博主在做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。 (三)list 使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。本人还用一个场景,很合适---取行情信息。就也是个生产者和消费者的场景。LIST可以很好的完成排队,先进先出的原则。 (四)set 因为set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。 另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。 (五)sorted set sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。
管道
相当于数据库中的事务处理。
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
import redis pool = redis.ConnectionPool(host='10.211.55.4', port=6379) r = redis.Redis(connection_pool=pool) # pipe = r.pipeline(transaction=False) pipe = r.pipeline(transaction=True) pipe.set('name', 'alex') pipe.set('role', 'sb') pipe.execute()
发布订阅
订阅者:
import redis r=redis.Redis(host='127.0.0.1') pub=r.pubsub() pub.subscribe("fm104.5") pub.parse_response() while 1: msg = pub.parse_response() print(msg)
发布者:
import redis r=redis.Redis(host='127.0.0.1') r.publish("fm104.5", "Hi,yuan!")
发布订阅的特性用来做一个简单的实时聊天系统再适合不过了,当然这样的东西开发中很少涉及到。再比如在分布式架构中,常常会遇到读写分离的场景,在写入的过程中,就可以使用redis发布订阅,使得写入值及时发布到各个读的程序中,就保证数据的完整一致性。再比如,在一个博客网站中,有100个粉丝订阅了你,当你发布新文章,就可以推送消息给粉丝们拉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号