


简介
Elasticsearch是一个基于Lucene库的开源搜索引擎,它提供分布式的实时文件存储和搜索,可扩展性好,并且支持通过HTTP网络接口交互,数据以JSON格式展示。
Elasticsearch因为其极快的搜索和聚合速度通常被应用在各种搜索应用中,比如在自己的app里面加一个搜索框或者分析实时日志(ELK系统)。
Elasticsearch会对所有输入的文本进行处理,建立索引放入内存中,从而提高搜索效率。在这一点上ES要优于MySQL的B+树的结构,MySQL需要将索引放入磁盘,每次读取需要先从磁盘读取索引然后寻找对应的数据节点,但是ES能够直接在内存中就找到目标文档对应的大致位置,最大化提高效率。并且在进行组合查询的时候MySQL的劣势更加明显,它不支持复杂的组合查询比如聚合操作,即使要组合查询也要事先建好索引,但是ES就可以完成这种复杂的操作,默认每个字段都是有索引的,在查询的时候可以各种互相组合。
为了省事,以下统一用ES来代替Elasticsearch,其实我们在公司里面也基本都说ES,全称比较难读。还有一点,因为ES使用了Lucene的库,下面说的很多优化思路都是Lucene里面的,但是为了讲解方便,我就用ES来代替Lucene。
索引
首先需要申明的是在ES中索引的概念和MySQL里面的概念不太一样,这里列出一下ES和MySQL的对应的概念,方便大家理解。
| MySQL | ES |
|---|---|
| 库(database) | 索引(index) |
| 表(table) | 类型(type) |
| 行(row) | 文档(doc) |
| 列(column) | 字段(field) |
在ES中每个字段都是被索引的,所以不会像MySQL中那样需要对字段进行手动的建立索引。
ES在建立索引的时候采用了一种叫做倒排索引的机制,保证每次在搜索关键词的时候能够快速定位到这个关键词所属的文档。
Inverted Index
比如有三句话在数据库中:
- Winter is coming
- Ours is fury
- Ths choice is yours
如果没有倒排索引(Inverted Index),想要去找其中的choice,需要遍历整个文档,才能找到对应的文档的id,这样做效率是十分低的,所以为了提高效率,我们就给输入的所有数据的都建立索引,并且把这样的索引和对应的文档建立一个关联关系,相当于一个词典。当我们在寻找choice的时候就可以直接像查字典一样,直接找到所有包含这个数据的文档的id,然后找到数据。
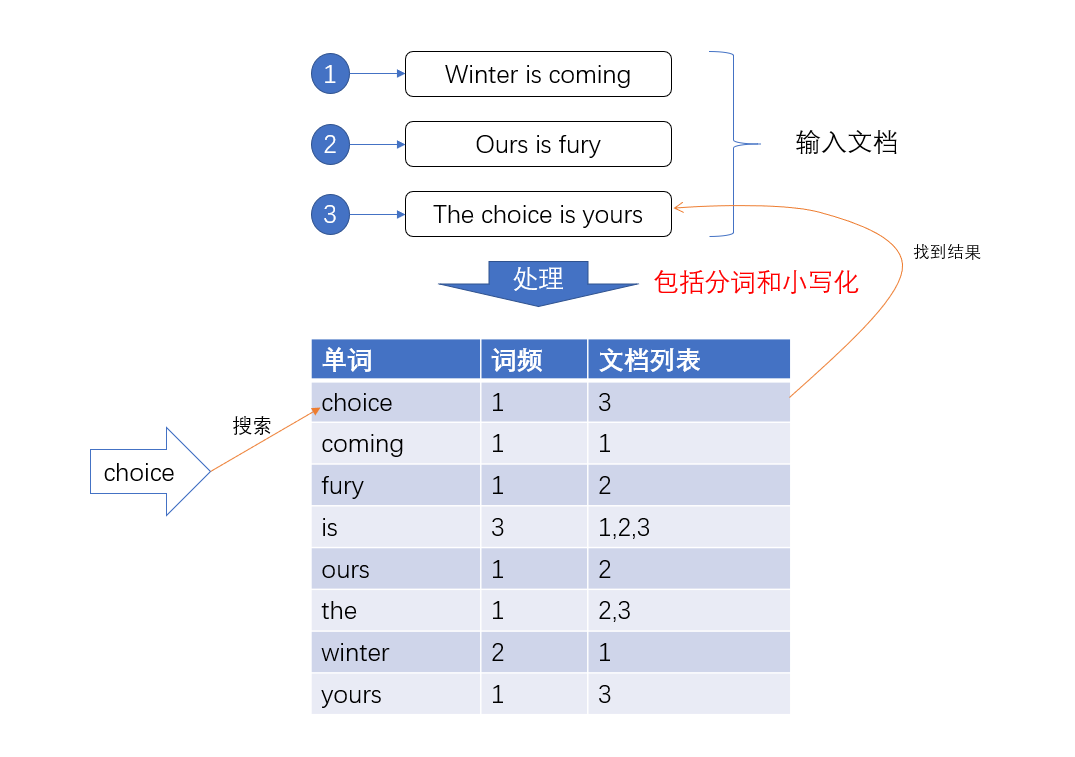
Lucene在对文档建立索引的时候,会给词典的所有的元素排好序,在搜索的时候直接根据二分查找的方法进行筛选就能够快速找到数据。不过是不是感觉有点眼熟,这不就是MySQL的索引方式的,直接用B+树建立索引词典指向被索引的文档。
ES做的要更深一点,ES希望把这个词典“搬进”内存,直接从内存读取数据不就比从磁盘读数据要快很多吗!问题在于对于海量的数据,索引的空间消耗十分巨大,直接搬进来肯定不合适,所以需要进一步的处理,建立词典索引(term index)。通过词典索引可以直接找到搜索词在词典中的大致位置,然后从磁盘中取出词典数据再进行查找。所以大致的结构图就变成了这样:
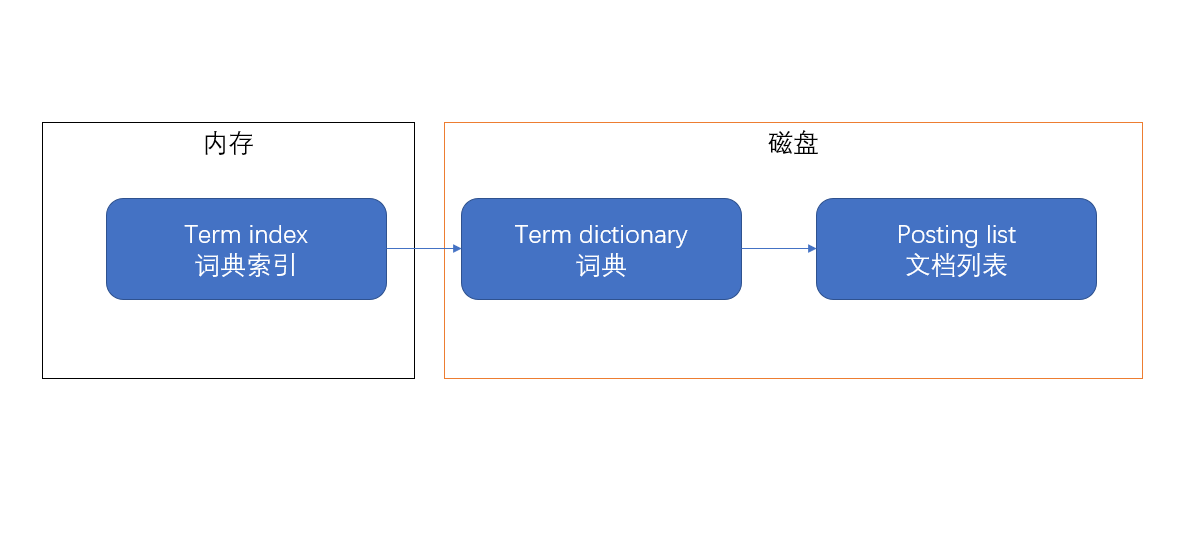
ES通过有限状态转化器,把term dictionary变成了term index,放进了内存,所以这个term index到底长什么样呢?
Finite State Transducers
有限状态转换器(Finite State Transducers)相当于是一个Trie前缀树,可以直接根据前缀就找到对应的term在词典中的位置。
比如我们现在有已经排序好的单词mop、moth、pop、star、stop和top以及他们的顺序编号0..5,可以生成一个下面的状态转换图
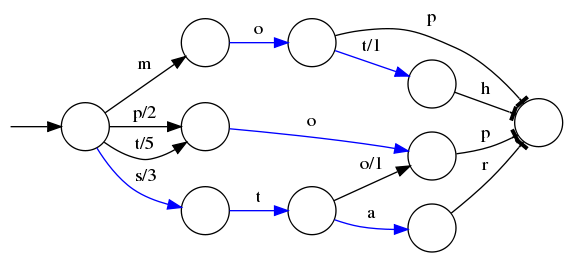
当遍历上面的每一条边的时候,都会加上这条边的输出,比如当输入是stop的时候会经过s/3和o/1,相加得到的排序的顺序是4;而对于mop,得到的排序的结果是0
但是这个树并不会包含所有的term,而是很多term的前缀,通过这些前缀快速定位到这个前缀所属的磁盘的block,再从这个block去找文档列表。为了压缩词典的空间,实际上每个block都只会保存block内不同的部分,比如mop和moth在同一个以mo开头的block,那么在对应的词典里面只会保存p和th,这样空间利用率提高了一倍。
使用有限状态转换器在内存消耗上面要比远比SortedMap要少,但是在查询的时候需要更多的CPU资源。维基百科的索引就是使用的FST,只使用了69MB的空间,花了大约8秒钟,就为接近一千万个词条建立了索引,使用的堆空间不到256MB。
顺带提一句,在ES中有一种查询叫模糊查询(fuzzy query),根据搜索词和字段之间的编辑距离来判断是否匹配。在ES4.0之前,模糊查询会先让检索词和所有的term计算编辑距离筛选出所有编辑距离内的字段;在ES4.0之后,采用了由Robert开发的,直接通过有限状态转换器就可以搜索指定编辑距离内的单词的方法,将模糊查询的效率提高了超过100倍。
现在已经把词典压缩成了词条索引,尺寸已经足够小到放入内存,通过索引能够快速找到文档列表。现在又有另外一个问题,把所有的文档的id放入磁盘中会不会占用了太多空间?如果有一亿个文档,每个文档有10个字段,为了保存这个posting list就需要消耗十亿个integer的空间,磁盘空间的消耗也是巨大的,ES采用了一个更加巧妙的方式来保存所有的id。
Posting Lists
所谓的posting list,就是所有包含特定term文档的id的集合,需要从词典映射到这个集合。由于整型数字integer可以被高效压缩的特质,integer是最适合放在posting list作为文档的唯一标识的,ES会对这些存入的文档进行处理,转化成一个唯一的整型id
在存储数据的时候,在每一个shard里面,ES会将数据存入不同的segment,这是一个比shard更小的分片单位,这些segment会定期合并。在每一个segment里面都会保存最多231231个文档,每个文档被分配一个唯一的id,从00到231−1231−1。
Frame of Reference
在进行查询的时候经常会进行组合查询,比如查询同时包含choice和the的文档,那么就需要分别查出包含这两个单词的文档的id,然后取这两个id列表的交集;如果是查包含choice或者the的文档,那么就需要分别查出posting list然后取并集。为了能够高效的进行交集和并集的操作,posting list里面的id都是有序的。同时为了减小存储空间,所有的id都会进行delta编码(delta-encoding,我觉得可以翻译成增量编码)
比如现在有id列表[73, 300, 302, 332, 343, 372],转化成每一个id相对于前一个id的增量值(第一个id的前一个id默认是0,增量就是它自己)列表是[73, 227, 2, 30, 11, 29]。在这个新的列表里面,所有的id都是小于255的,所以每个id只需要一个字节存储。
实际上ES会做的更加精细,它会把所有的文档分成很多个block,每个block正好包含256个文档,然后单独对每个文档进行增量编码,计算出存储这个block里面所有文档最多需要多少位来保存每个id,并且把这个位数作为头信息(header)放在每个block 的前面。这个技术叫Frame of Reference,我翻译成索引帧。
比如对上面的数据进行压缩(假设每个block只有3个文件而不是256),压缩过程如下
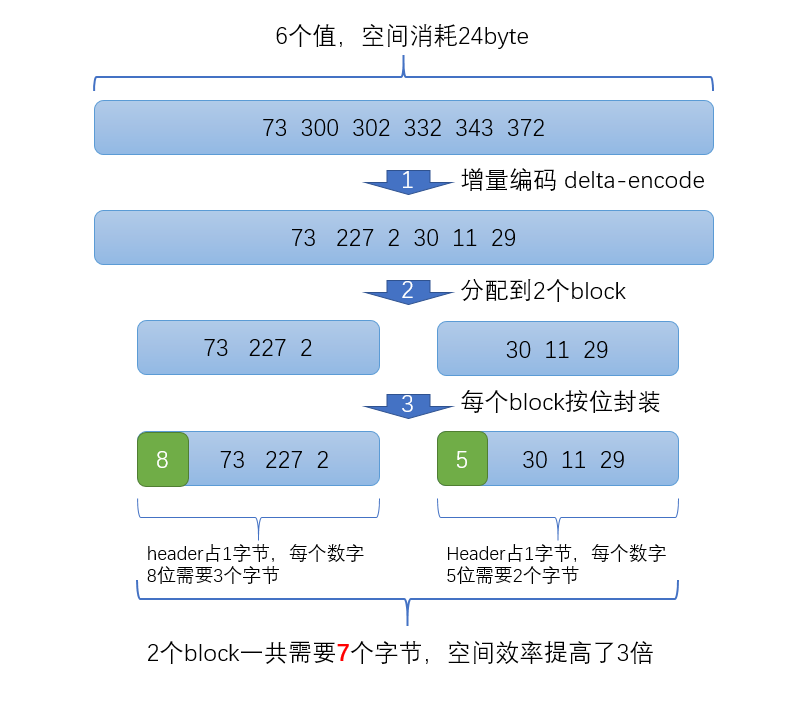
在返回结果的时候,其实也并不需要把所有的数据直接解压然后一股脑全部返回,可以直接返回一个迭代器iterator,直接通过迭代器的next方法逐一取出压缩的id,这样也可以极大的节省计算和内存开销。
通过以上的方式可以极大的节省posting list的空间消耗,提高查询性能。不过ES为了提高filter过滤器查询的性能,还做了更多的工作,那就是缓存。
Roaring Bitmaps
ES会缓存频率比较高的filter查询,其中的原理也比较简单,即生成(fitler, segment)和id列表的映射,但是和倒排索引不同,我们只把常用的filter缓存下来而倒排索引是保存所有的,并且filter缓存应该足够快,不然直接查询不就可以了。ES直接把缓存的filter放到内存里面,映射的posting list放入磁盘中。
ES在filter缓存使用的压缩方式和倒排索引的压缩方式并不相同,filter缓存使用了roaring bitmap的数据结构,在查询的时候相对于上面的Frame of Reference方式CPU消耗要小,查询效率更高,代价就是需要的存储空间(磁盘)更多。
Roaring Bitmap是由int数组和bitmap这两个数据结构改良过的成果——int数组速度快但是空间消耗大,bitmap相对来说空间消耗小但是不管包含多少文档都需要12.5MB的空间,即使只有一个文件也要12.5MB的空间,这样实在不划算,所以权衡之后就有了下面的Roaring Bitmap。
- Roaring Bitmap首先会根据每个id的高16位分配id到对应的block里面,比如第一个block里面id应该都是在0到65535之间,第二个block的id在65536和131071之间
- 对于每一个block里面的数据,根据id数量分成两类
- 如果数量小于4096,就是用short数组保存
- 数量大于等于4096,就使用bitmap保存
在每一个block里面,一个数字实际上只需要2个字节来保存就行了,因为高16位在这个block里面都是相同的,高16位就是block的id,block id和文档的id都用short保存。
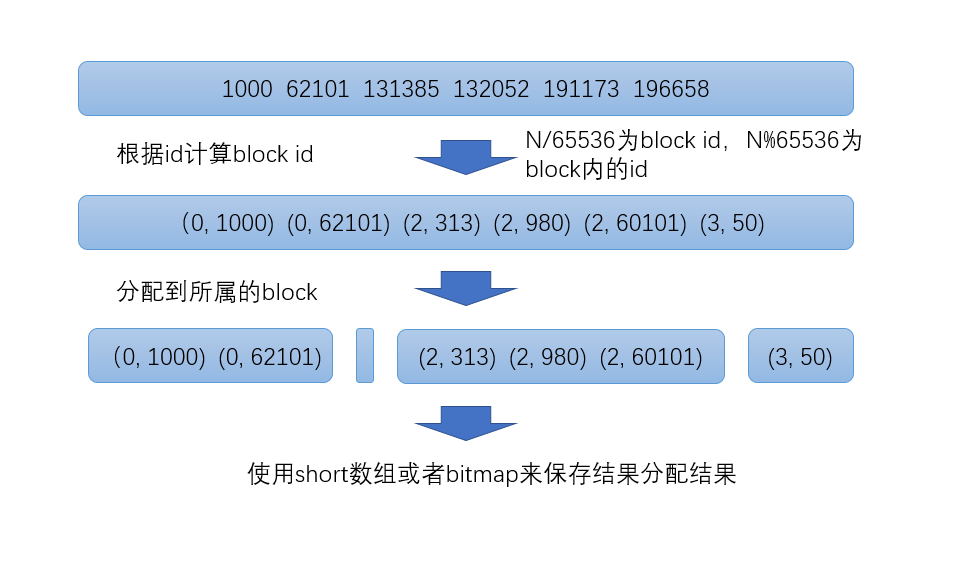
至于4096这个分界线,因为当数量小于4096的时候,如果用bitmap就需要8kB的空间,而使用2个字节的数组空间消耗就要少一点。比如只有2048个值,每个值2字节,一共只需要4kB就能保存,但是bitmap需要8kB。
总结
ES为了提高搜索效率、优化存储空间做了很多工作。
为了能够快速定位到目标文档,ES使用倒排索引技术来优化搜索速度,虽然空间消耗比较大,但是搜索性能提高十分显著。
由于索引数量巨大,ES无法直接把全部索引放入内存,转而建立词典索引,构建有限状态转换器(FST)放入内存,进一步提高搜索效率。
数据文档的id在词典内的空间消耗也是巨大的,ES使用了索引帧(Frame of Reference)技术压缩posting list,带来的压缩效果十分明显。
ES的filter语句采用了Roaring Bitmap技术来缓存搜索结果,保证高频filter查询速度的同时降低存储空间消耗。

