吴恩达《深度学习》第四门课(3)目标检测(Object detection)
3.1目标定位
(1)案例1:在构建自动驾驶时,需要定位出照片中的行人、汽车、摩托车和背景,即四个类别。可以设置这样的输出,首先第一个元素pc=1表示有要定位的物体,那么用另外四个输出元素表示定位框的中心坐标和宽高,再用3个输出元素one-hot表示是三个类别中的哪一类。当第一个元素pc=0时表示是背景,然后就不需要考虑其他输出了,如下图所示(需要注意的是是根据图片的标签y来决定使用几个元素的):
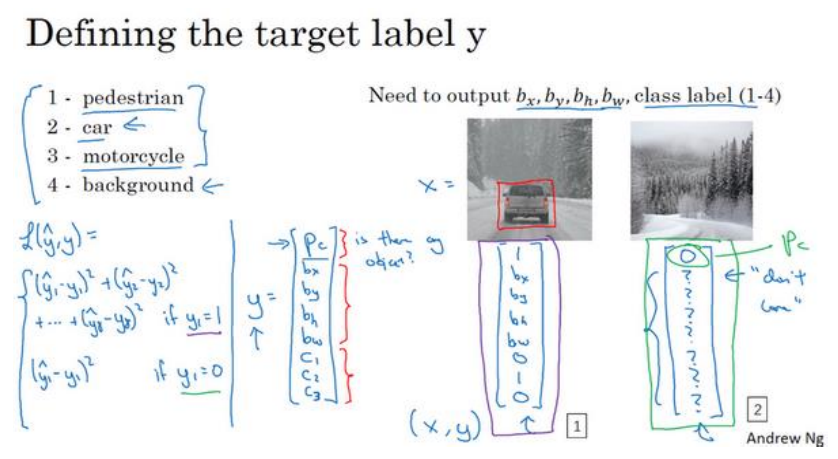
(2)损失函数:上图中左下角是使用了平方误差损失函数这是为了方便解释方便而使用的。实际使用中pc使用逻辑回归,c1,c2,c3是用softmax激活然后然后用对数损失函数,位置信息是使用平方误差损失函数,然后将这些损失函数相加起来得到最终的代价函数。当标签y=0时,只考虑pc即可。
3.2特征点检测
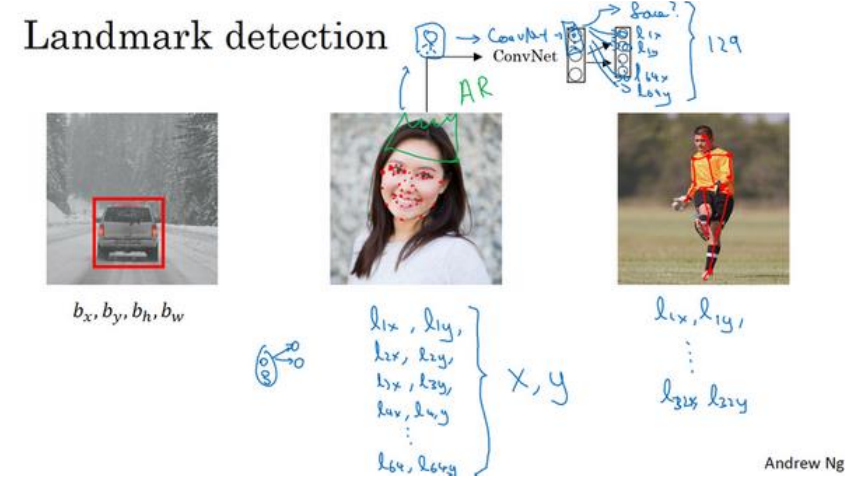
(1)特征点检测就是第一个单元输出1,表示有这个对象(如人脸),然后如果在人脸上定义了64个特征点(如下图所示),每个特征点用(x,y)表示,那么网络将会有1+2*68=129个单元输出。需要注意的一点是在标注样本时,所有标签在所有图片中务必保持一致,比如说,第5个特征点表示左眼的外眼角,那么所有图片的第五个特征点都应该是这个。
3.3目标检测
(1)案例是检测图片中的汽车,首先是有裁剪合适的照片(裁剪合适是指照片中如果有汽车那么汽车将占满整张图),进行训练一个可以分类汽车的网络,即输出是否有汽车。如下图所示:

(2)滑动窗口目标检测是用一个滑动窗口从图片的最左上角从做到右(设定一定步长)从上到下去滑动,分别将窗口内的图片裁剪下来送入到之间训练好的网络中,判断有无汽车,然后改变窗口大小,以及步长等,重复上面步骤,如下图所示:


(3)滑动窗口的问题就是计算量非常的大,因为要保证精确度化不能用太大的步长,这样滑动窗口很多,而且很多地方是属于重复计算了。
3.4卷积的滑动窗口实现
(1)将全连接层转换为卷积层,如下图所示5*5*16与400个单元进行全连接可以转换为用400个5*5*16的卷积核来卷积5*5*16,这样每一个卷积核其实就相当与都是全连接的结果,唯一的区别就是之前全连接输出是400个单元,现在输出是1*1*400,维度不同,下一层全连接转卷积同样操作,最后一层原来是输出4个单元,现在变成了1*1*4,维度不同,仅此而已。
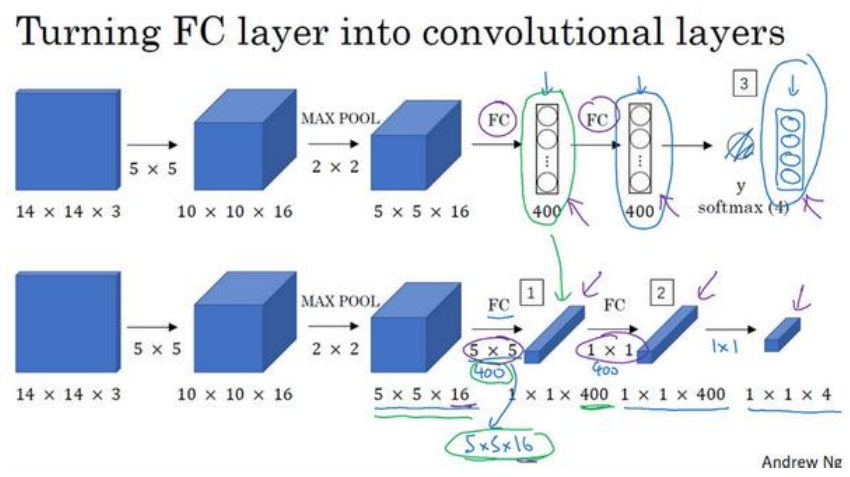
(2)上一节中一个一个滑动框输入网络中,有许多计算是重叠的,即多次计算,所以可以将原图直接输入到网络中,这样避免了重复计算。之所以将前面的全连接层变成卷积层,是因为只有都是卷积层的时候才可以输入任意尺寸的图片,更具体的说是参数不随图片尺寸变化,而全连接层参数w时固定的意味着图片输入尺寸要固定。
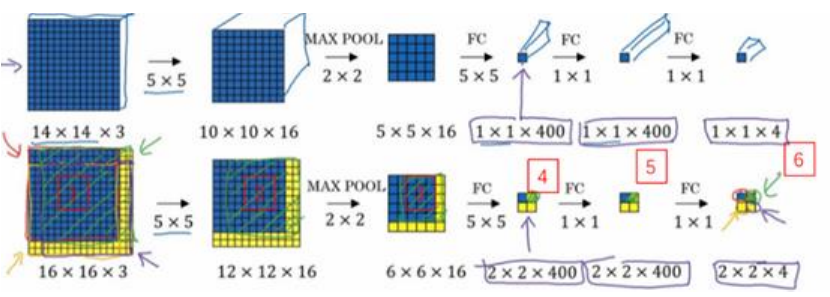
(3)该方法还存在的一个问题就是边界框位置不够准确。
3.5Bounding Box预测(YOLO算法)
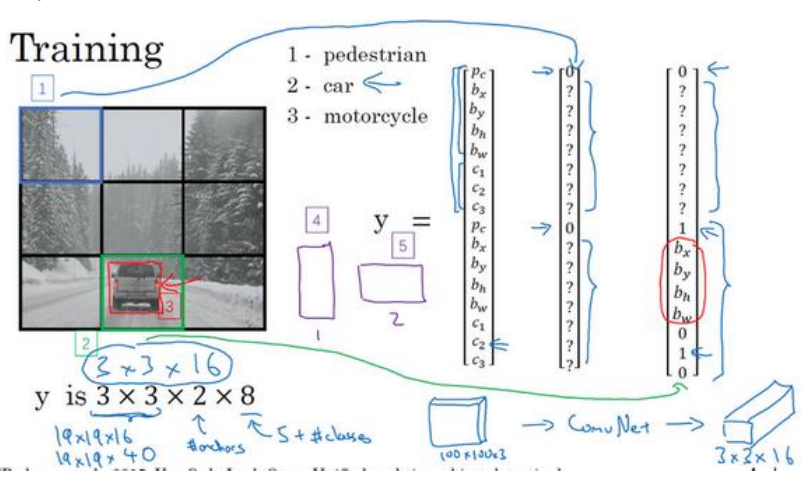
(1)将一张图3*3共9个单元(在论文中是分成19*19,论文默认前提是一个单元里只有一个对象),每个单元都有上面提到的1+4+3=8个输出(还是用上面无人驾驶的例子,3个类别加一个背景)所以整个网络输出为3*3*8。换言之就是输入一张图片,然后网络最终输出的维度为3*3*8,3*3是指有图片分成这么多格子,然后每个格子需要用到8个参数。如下图所示:
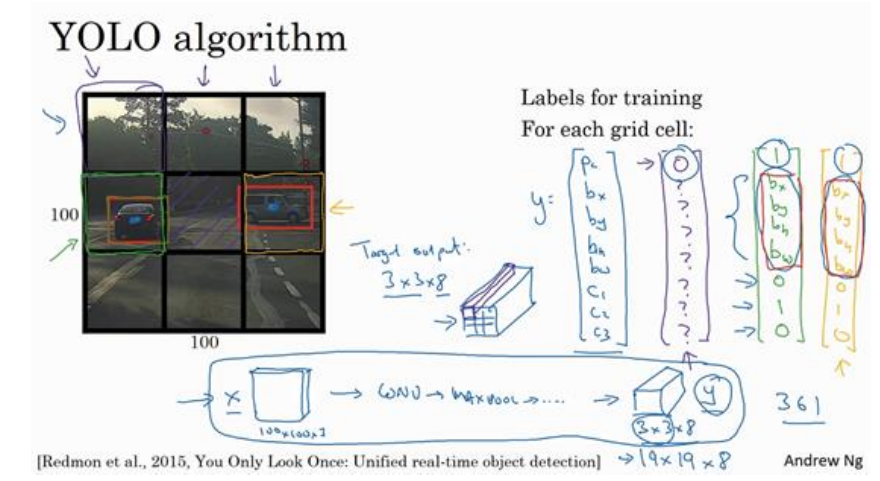
(2)YOLO中将对象(即识别的物体)的中心点落在哪一个网格中就,它就属于哪个网格,一个对象只能属于一个网络,即使这个目标可能横跨了好多个网格。
(3)bx,by,bw,bh一种表示方法:将网格(注意不是整张图)的左上角记做(0,0),网格右下角为(1,1),所以bx,by的值都在0到1之间,反证法如果超过1说明它不应该划分到这个网格中。bw,bh也是相对于网格的比例,所以其值可能大于1.如下图所示:
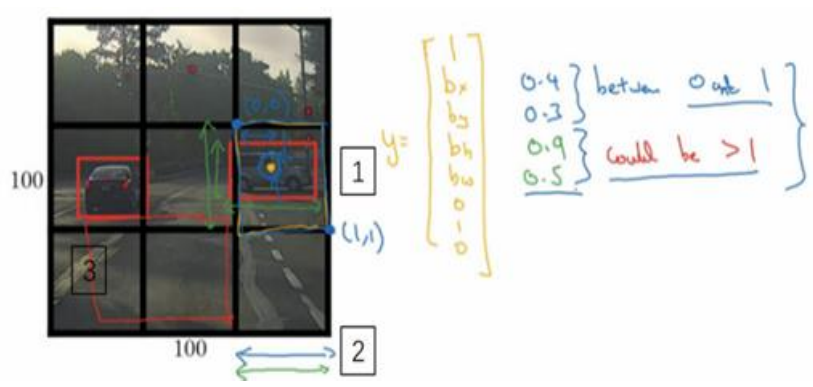
3.6交并比
(1)IoU=(A∩B)/(A∪B),一般将交并比的值大于0.5看成是检测正确的,当然这个值可以根据实际情况来定。

3.7非极大值抑制
(1)需要理解的一点是,我们做的样本标签中一个对象只会属于一个网格(中心点落在该网格上),但是当我们开始对网络进行预测时,很多网格都会觉得这个对象是属于自己的,如下图所示:

(2)用只有一个类别(如汽车)来说明非极大值抑制的过程。首先将预测到有汽车的网格中概率小于阈值的都去掉(比如说0.6),然后将剩下预测到有汽车的都进行排序,去其中可能性最大的,它将成为一个预测结果,然后与它的交并比大于某个阈值的都去掉,然后再在剩下中取最大可能性的,重复以上步骤,直到处理完全部。
如下图所示(下图中的pc其实是之前的pc乘上类别概率c1、c2或c3):

(3)当有多个类别时,按类别分开进行非极大值抑制。
3.8Anchor Box
(1)上面都是假设一个网格里面只有一个对象,如果有两个对象,如下图所示,人和汽车的中心点几乎重合,这时可以提出一种新概念,即在一个网格框中设置多个不同形状的anchor box,比如说两个,一个瘦高的,一个挨胖的,如下图所示:
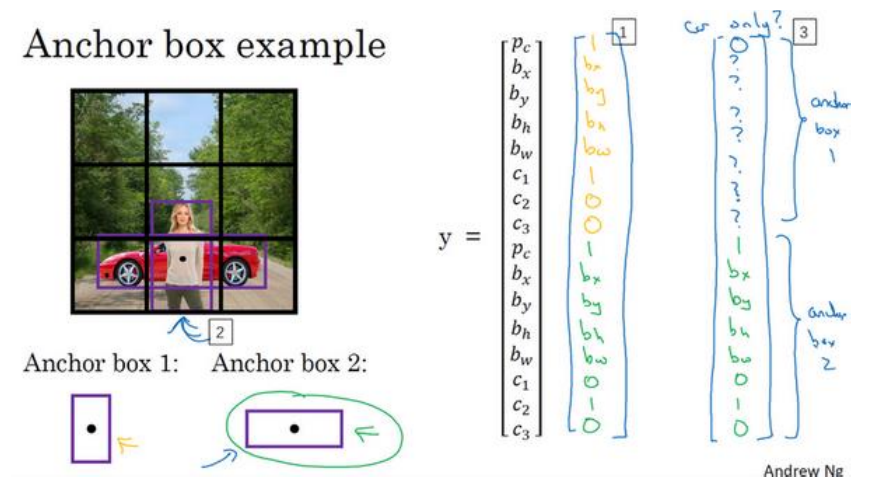
(2)其实实质就是每个网格的第三维度增加输出,把之前的3*3*8变成3*3*16(如下图所示),有时候会变成四个维度如3*3*2*8。
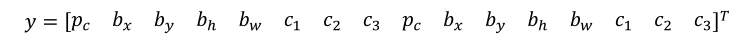
(3)有一点需要注意的是,在给样本打标签时要做到统一,比如说瘦高型的,那么将对应到前八个输出,如果是矮胖型的对应到后面的八个输出。
(4)当超过两个对象在同一个网格(其实概率特别小),暂时没有什么好的办法;如果两个对象都是与同一种类型(比如说瘦高型的),也没什么特别好的办法。
3.9YOLO算法
(1)将上面提到的各个模块组合在一起其实就是YOLO算法了,每个网格多个anchor box,最后再做非极大值抑制。
3.10候选区域(Region proposals)
(1)RCNN:首先使用传统图像分割的方法,对图像进行分割,然后提取出2000个可能有对象的候选框,这样相对于最开始提到的滑动框的方式减少了非常多的框,其他二者其实是一回事,然后送入网络,如下图所示:

(2)Fast RCNN:即先将整个图像进行卷积,然后再将候选框映射到卷积之后的输出做分类,其实就是上面提到的卷积整幅图减少重复计算。
(3)Faster RCNN:由于使用传统的图像分割选出候选框需要非常多的时间,所以使用卷积神经网络来选出候选框。三个算法特点如下图:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号