吴恩达《深度学习》第二门课(1)深度学习的实用层面
1.1训练,验证,测试集(Train/Dev/Test sets)
(1)深度学习是一个按照下图进行循环的快速迭代的过程,往往需要多次才能为应用程序找到一个称心的神经网络。

(2)在机器学习中,通常将样本分成训练集,验证集和测试集三部分,数据规模相对较小,适合传统的划分比例(如6:2:2),数据集规模比较大的,验证集和测试集要小于数据总量的20%或者10%甚至更低。
(3)交叉验证集和测试集务必来自同分布。
(4)有时候只有训练集和验证集,没有独立的测试集(将无法提供无偏性能评估),这时人们也会把验证集称为测试集。
1.2偏差,方差(Bias/Varicance)
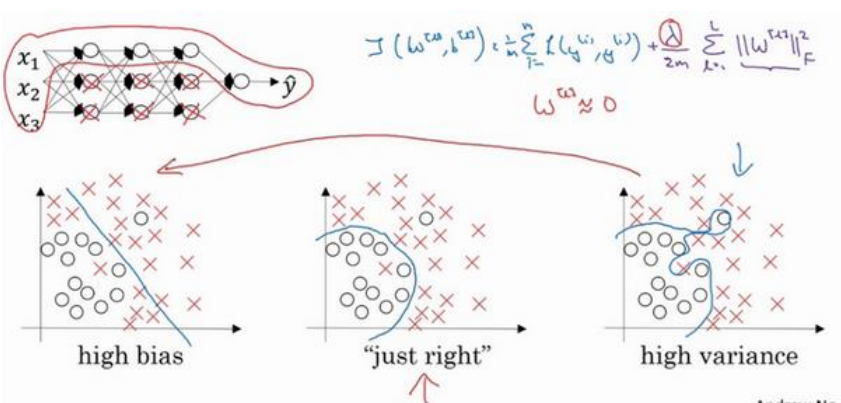
(1)以下三个图分别表示欠拟合(高偏差),适度拟合,过拟合(高方差):
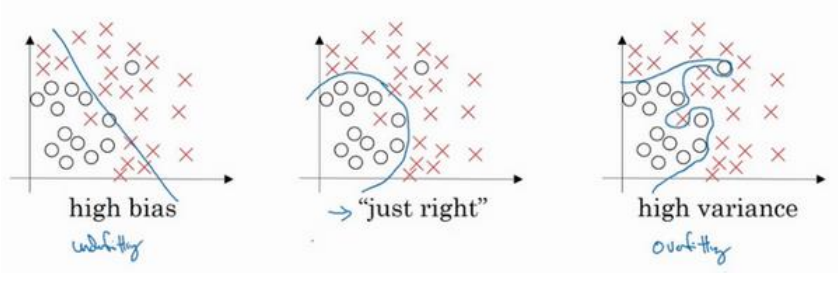
(2)最优误差也称为贝叶斯误差,本节中假设最有误差为零(如在图像分类中人可以辨别出所有图像的类别)。
(3)训练误差减去左右误差为偏差,结果大说明偏差大;验证集误差减去训练误差为方差,结果大说明偏差大。
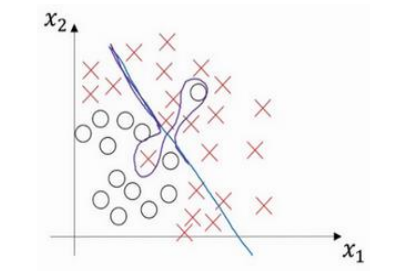
(4)是存在高偏差高方差的情况的,如下图,直线导致高偏差,局部过拟合导致高方差:
1.3机器学习基础
(1)偏差和方差是两种完全不同的情况,有分别对应的处理方法,不要盲目的使用一些策略。
(2)在深度学习时代,只要正则适度,通常构建一个更大的网络便可以在不影响方差的同时减少偏差,而采用更多数据通常可以在不过多影响偏差的同时减少方差。
1.4正则化
(1)过拟合常用的两种解决方法:添加正则化项(容易实现),增加更多数据(有时候很难得到更多数据)。
(2)L1正则化往往会使得W最终稀疏,即w向量中很多是0,事实证明它并没有减少太多的存储空间,所以现在越来越多人还是使用L2正则。
(3)L2正则式子如下:
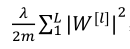
其中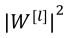 被定义为矩阵中所有元素的平方求和。
被定义为矩阵中所有元素的平方求和。
(4)正则化常常被称为“权重衰减”,是因为正则项会试图让W变得更小,实际上相当于给矩阵W乘以(1-αλ/m),如下所示:
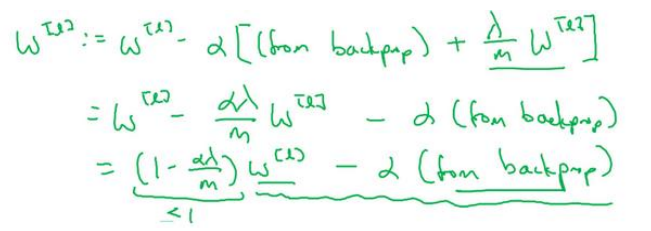
1.5为什么正则化有利于预防过拟合
(1)第一种直观理解,首先一个很复杂的神经网络(过拟合):
然后添加正则项,使λ,这时候很多权重变成0,然后相当于消除了很多隐藏单元,复杂网络变成很简单的网络(欠拟合),从过拟合到欠拟合中间会经历最优拟合的情况,如下图所示:
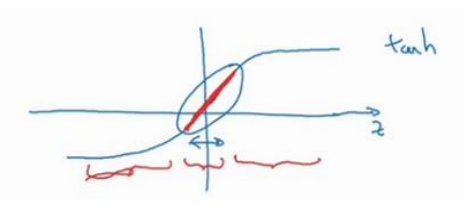
(2)第二种理解,W实际不会变成零,只会变得非常小,这时候z也会变得非常小,那么根据以下的激活函数,将会在中间线性的地方活动,那么相当与经过很多次线性变换,所以这也导致网络变得简答,消除了过拟合情况。
1.6dropout正则化
(1)原网络如下:
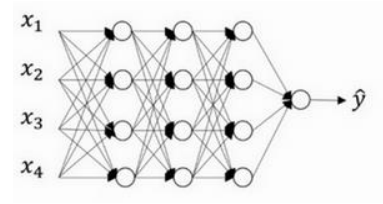
(2)设置keep-prob为0.8(相当于一个d[l]向量中80%为1,百分之20%为零),这个向量与某一层的输出a[l]相乘(与零相乘自然输出就为零了),其网络示意图如下(图中是设置为0.5):

(3)在上一步乘积之后的值又会除以0.8,如下面的公式,这样可以保证均值不会发生改变(因为单元数减少会导致后面一层的输入减少,通过除以减少量来维持不变)
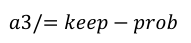
(4)测试的时候不使用dropout。
1.7理解dropout
(1)直观上理解:不要依赖于任何一个特征,因为该单元的输入可能随时被清除,或者说该单元的输入也都可能被随机清除,因此不愿意在任何一个输入单元上加上太多的权重,会把权重分摊给其他单元,这其实产生了收缩权重的平方范数的效果。
(2)dropout被正式的作为一种正则化的替代方式,L2对不同权重的衰减是不同的,他取决于倍增的激活函数的大小。
(3)不同层之间可以使用不同的keep-prob,一般矩阵W越大的层,越容易导致过拟合,所以keep-prob的值设置的越低(输入层一般为1),如下所示:
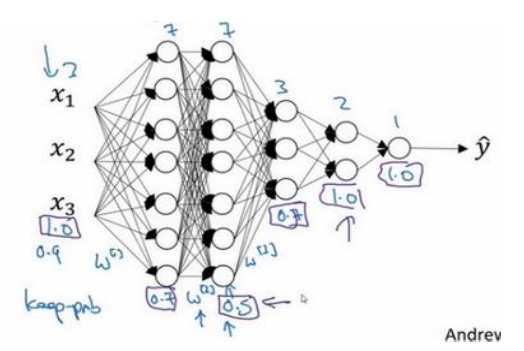
(4)计算机视觉中常用dropout,因为像素(特征)太多,数据量太少,常常导致过拟合。
(5)dropout的一大缺点就是代价函数J不再明确定义,每次迭代,都会随机移除一些节点,或者说某种程度上很难准确计算。
1.8其他正则化方法
(1)数据增强:旋转、扭曲、任意裁剪放大等。
(2)early stopping:在交叉验证集代价函数(误差率等)下降又上升的拐点处停止,如下图所示:
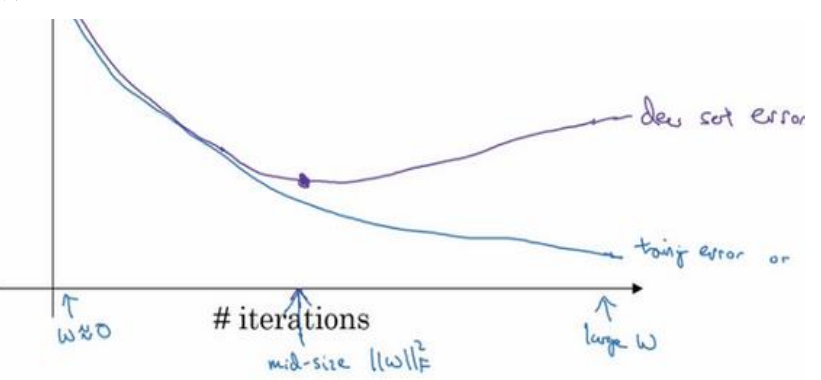
early stoping的主要缺点就是控制w不太大的时候,也终止的优化代价函数J,而不能向其他方式一样:一方面不断的使代价函数变小,用另外的方式来控制使其不发生过拟合。
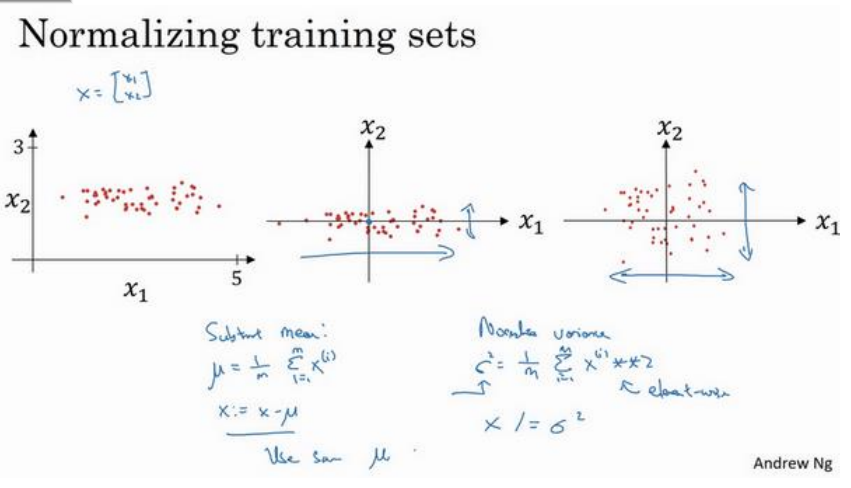
1.9归一化输入
(1)归一化需要两步:零均值(减去均值)、归一化方差(除以方差)(测试集用的是训练集的均值和方差做处理,不要再计算测试集的均值方差),其效果如下:
公式分别如下:
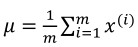
x-=μ
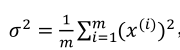
x/=σ 2
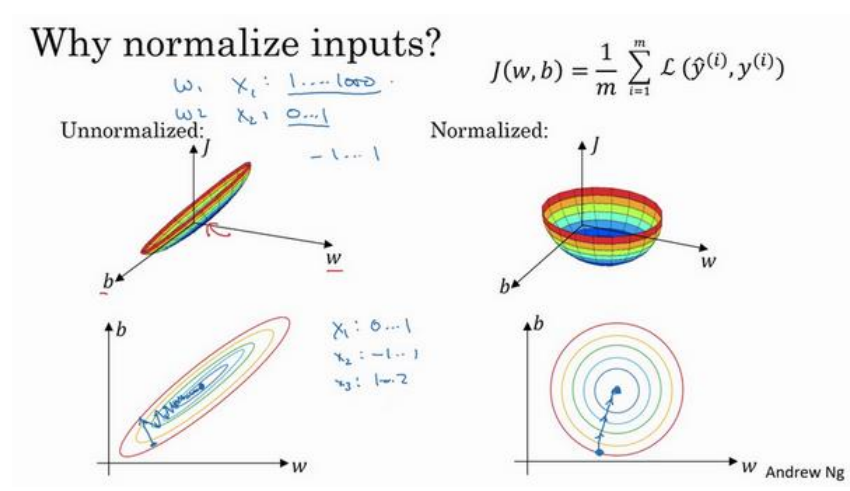
(2)各特征取值在同一个数量级时(如分别为0-1,-1到1,1-2)时不需要归一化,如果在不同不同数量级时要进行归一化(如0-1,0-1000)。
(3)归一化之后的代价函数如下右图所示(左图为未归一化),归一化之后可以使用更大的学习率,因为每一步都是朝向梯度下降的方向进行的。
1.10梯度消失/梯度爆炸(Vanishing/Exploding gradients)
(1)假设为线性激活函数,忽略b,那么对于以下的网络,有如下的输出:
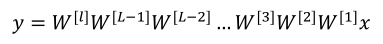
假设每个权重为:
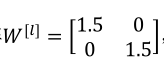
则有: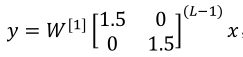
他是1.5倍的单位矩阵,y=1.5(L-1)x,这时候输出是随着层数增加呈现指数增大的(梯度爆炸,导数时也有这个性质);同理,如果把1.5改成0.5时,将会呈现指数减小,即梯度消失(导数时也有这个性质)。
(2)上面虽然只讨论的激活函数的指数级递增递减,但它同样适用于于层数L相关的导数和梯度函数,也是呈现指数级增长或指数递减。
(3)合理的初始化能够较有效(虽然不能完美解决)解决如上问题。
1.11神经网络的权重初始化
(1)z是由参数与特征乘积求和得到,如下式,我们不希望z过大(爆炸)或者过小(消失),所以当特征特别多时,很自然的希望初始化时w能比较小,所以w的初始化应该与各层的输入个数有关。
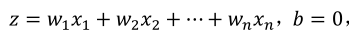
(2)使用ReLU激活函数时,对w常用的初始化(因为是看输入个数,即上一层的神经元个数):
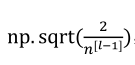
(3)使用tanh激活函数时,对w常用的初始化:
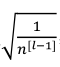
(4)其他初始化方法:
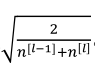
(5)以上给出的初始化方差都是默认值,如果想改变方差,可以在上面的公式再乘以一个系数。(通常这一步的调优优先级不高)
1.12梯度的数值逼近
(1)双边误差公式比单边误差公式更准确。
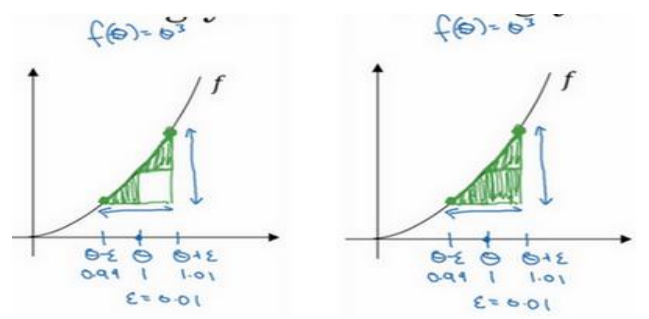
双边误差公式:
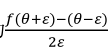 、
、
单边误差公式:
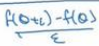
1.13梯度检验
(1)对代价函数的每一个参数进行双边梯度检测:
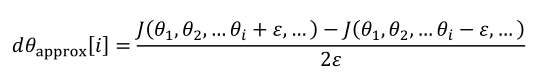
(2)检查计算值和偏到的欧氏距离,当小于10-7,很好;10-5,需要检查;10-3很可能存在错误。
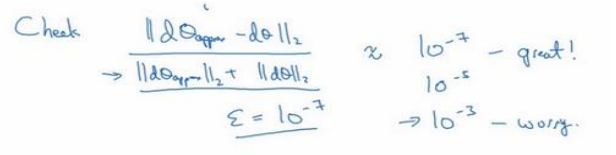
1.14梯度检验应用的注意事项
(1)不要在训练的时候应该梯度检测,它只用于调试。
(2)如果算法的梯度检验失败,需要检测所有项。
(3)当代价函数含有正则化项时,dθ务必将正则项添加进去,不要漏了。
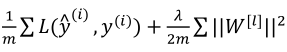
(4)梯度检验和dropout不要同时使用,梯度检验是关掉dropout。后者的存在将会难以计算代价函数J。
(5)这一点一般情况下不会出现,比较微妙:只有在w,b较小的时候,梯度检验才会正确,所以一般过程是先初始化,然后就进行梯度检验,再进行训练(训练一般会时w,b变大导致梯度检验越来越不准确)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号