
吴恩达《机器学习》课程总结(10)应用机器学习的建议
10.1决定下一步该干什么
当系统的效果很差时,你可能考虑到收集更多的样本,也可能:
(1)尝试减少特征的数量;
(2)尝试获得更多的特征;
(3)尝试增加多项式特征;
(4)尝试减少正则化程度λ;
(5)尝试增加正则化程度λ。
如果做决策将是本章的内容。而不是盲目的选择一种策略。
10.2评估一个假设
将数据集分为训练集和测试集,在测试集上计算误差:
(1)对于线性回归模型,我们利用测试集数据计算代价函数J;
(2)对于逻辑回归模型,不仅可以利用测试集计算代价函数外,还可以利用误分类的比率来计算结果:
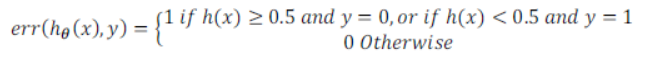
10.3模型选择和交叉验证集
将数据集按照8:2:2分为训练集,交叉验证集和测试集。
模型选择的方法:
(1)使用训练集训练处10个模型;
(2)用10个模型分别对交叉验证集计算得出交叉验证集误差;
(3)选取 代价函数数值最小的模型;
(4)用步骤3中选出的模型对测试集计算得出推广误差。
10.4诊断偏差和方差
(1)偏差(欠拟合)、方差(过拟合)
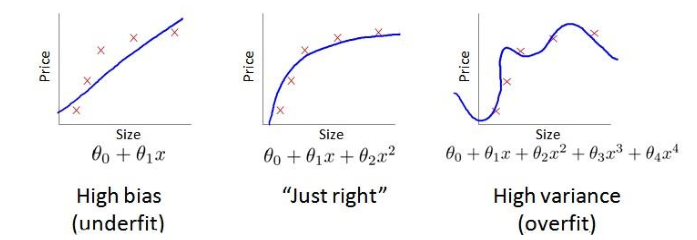
(2)误差随多项式次数的关系

次数低时,训练误差和验证误差都大,欠拟合;次数高时,训练误差小,验证误差大,过拟合。
训练误差和验证误差相近时,欠拟合;验证误差高于训练误差时过拟合。
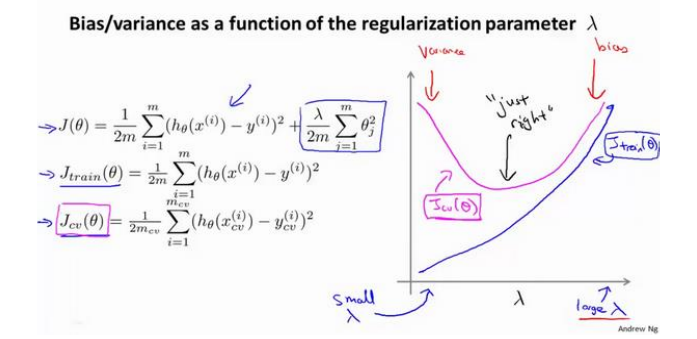
10.5正则化和偏差/方差
(1)正则化的影响:

(2)λ的选择(以2为倍数增加,如0,0.01,0.02,0.04,0.08,0.16,0.32……):
1.使用训练集训练出12个不同程度的正则化模型;
2.用12个模型分别对交叉验证集计算出交叉验证误差;
3.选择得出交叉验证误差最小的模型;
4.运用步骤3中选出模型对测试集计算得出推广误差。
(3)训练误差和验证误差与λ的关系:
10.6学习曲线
(1)学习曲线是将训练误差和交叉验证集误差作物训练样本数量(m)的函数绘制的图表:
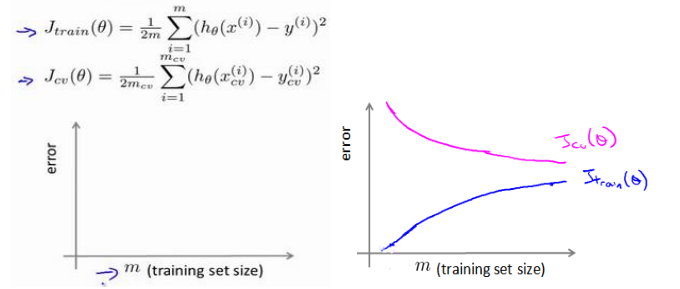
(2)训练误差很大,高偏差(增加数据不会有改观)
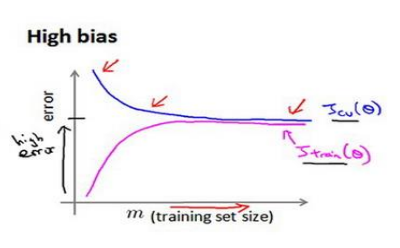
(3)验证集误差与训练集误差相差很大,高方差(增加数据可以提高算法效果)
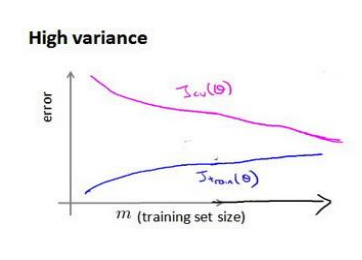
10.7决定下一步做什么
通过以上的诊断,下面是一些策略:
(1)获得更多的训练实例——解决高方差
(2)尝试减少特征的数量——解决高方差
(3)尝试获得更多的特征——解决高偏差
(4)尝试增加多项式——阶段高偏差
(5)尝试减小正则化程度——解决高偏差
(6)尝试增加正则化程度——解决高方差
一般使用较大的网络加上正则化会比使用小网络更有效。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号