吴恩达《Machine Learning Yearning》总结(1-10章)
1.为什么选择机器学习策略
案例:建立猫咪图像识别app
系统的优化可以有很多的方向:
(1)获取更多的数据集,即更多的图片;
(2)收集更多多样数据,如处于不常见的位置的猫的图,颜色奇异的猫的照片等;
(3)增加算法迭代次数,使算法训练的更久;
(4)尝试添加正则化;
(5)改变神经网络的架构(层数,单元的个数等);
……
2.如何使用本书帮助你的团队
本书其实就是帮助做决策,决定改进的策略。
3.先修知识和符号标记
监督学习(supervised learning)主要会介绍:线性回归(linear regression)、逻辑回归(logistic regression)、神经网络(neural network)。
4.规模驱动机器学习非发展
(1)数据可用性(data availability):各种数字设备、智能终端带来了海量的数据。
(2)计算机计算能力的增强(computational scale)。
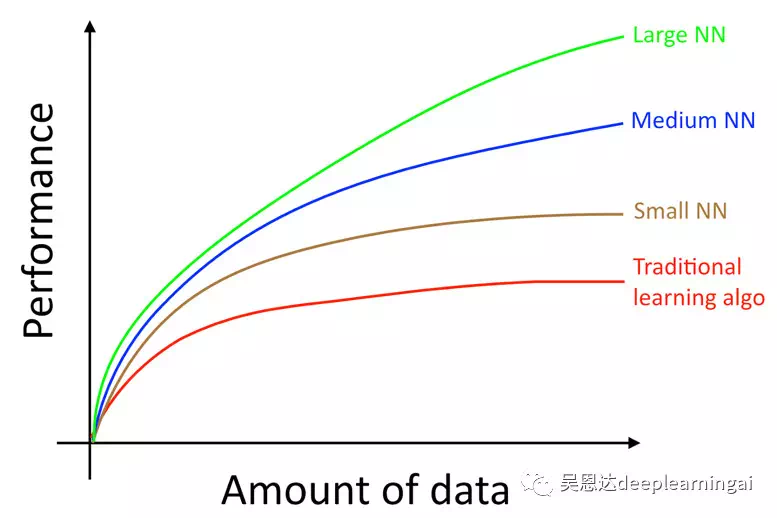
图说明:小数据集时,可能一些传统的机器学习算法通过人工的设计特征等,其效果会优于深度神经网络,但随着数据量的增强,深度神经网路的优势愈发明显。
5.开发集合测试集的概念
(1)训练集(training set):用于运行你的算法。
(2)开发集(development set):用于调整参数,选择特征,以及对学习算法做出其他决定,也被称为留出交叉验证集(hold-out cross validation set)。
(3)测试集(test data):用于评估算法的性能,但不会据此决定使用什么学习算法或参数。
开发集和测试集的使命就是引导你的团队对机器学习系统做出最重要的改变。
在传统机器学习中,训练集和测试集可能按照7/3来划分,但随着数据的增加,测试集所占的比例会不断减少。
6.开发集和测试集应该服从同一分布
开发时所使用的数据集分布和上线后面对的真实数据之间尽量保持同分布,如果分布不同可能效果会很差,例如:开发时都是使用网上爬取的高清照片毛,而上线后上传的可能都是一些手机拍摄的模糊的猫照片,二者分布不同,故造成效果不好。
训练集效果好,测试集效果不好,首先得确定是否同分布,在这个前提下再去考虑过拟合等其他原因。
7.开发集和测试集应该多大
训练集测试集比例7/3较适用于数据规模在100至10000个样本时,随着数据的增加,测试集所占的比例会不断减少。
8.使用单值评估指标进行优化
准确率是单值评估指标,精确度(presicion)和召回率(recall)不是单值指标。
将precision和recall转换为单值指标公式F1 score:2(PR)/(P+R),值越大越好。
| 1(label) | 0(label) | ||
| 1(predict) | True Positive | False Positive | precision=TP/(TP+FP) |
| 0(predict) | False Negative | Ture Negetive | |
| recall=TP/(TP+FN) | accuracy=(TP+TN)/(TP+TN+FP+FN) |
说明:precision是从预测结果的视角来看的,预测为正样本中到底有多少是正样本;recall是从样本的视角来看的,真正的正样本有多少被预测到了。
9.优化指标和满意度指标
例子:既要追求速度,又要追求准确度,这里有两个指标,如果都融入一个公式中如accuracy-0.5*time,这样不是很合理,这时可以设定不超过100ms作为一个前提,即满意度指标,在这个指标的前提下去考虑剩余的那个指标。
当有N个指标时,使其中N-1个变为满意度指标,然后去优化剩余的那个指标。
10.通过开发集和度量指标加速迭代
(1)尝试一些关于系统构建的想法(idea);
(2)使用代码(code)实现想法;
(3)根据实验(experiment)结果判断想法是否行得通,在此基础上学习总结,从而产生新的想法,并保持这一迭代过程;
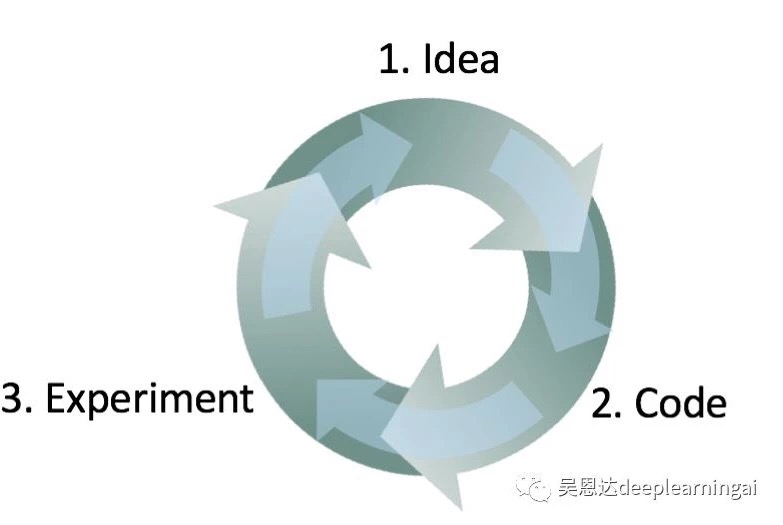
图说明:迭代越快进展越快,此时拥有开发集、测试集和度量指标的重要性便体现出来了,每当有一个新想法, 在开发集上评估其性能可以帮助你判断当前方向是否确定。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号