eBPF会成为服务网格的未来吗?
服务网格现状
服务网格为服务提供了复杂的应用层网络管理,如服务发现、流量路由、弹性(超时/重试/断路)、认证/授权、可观察性(日志/度量/追踪)等。
在分布式应用的早期,这些要求是通过直接将所需的逻辑嵌入到应用中来解决的,比如spring cloud等微服务框架。服务网格将这些功能从应用程序中提取出来,作为基础设施的一部分透明的提供给所有应用程序使用,因此不再需要修改每个应用程序。
在早期,服务网格的功能通常是以库的形式实现的,要求网格中的每个应用程序都要链接到以应用程序的语言框架编写的库。类似的事情也发生在互联网的早期:曾几何时,应用程序还需要运行自己的 TCP/IP 协议栈!正如我们将在这篇文章中讨论的那样,服务网格正在发展成为一种内核责任,就像网络堆栈一样。

今天,服务网络通常使用一种叫做sidecar模型的架构实现的,通过在每一个应用pod上添加一个代理sidecar容器,如Envoy或Linkerd,这些代理也被称为服务网格的数据平面。
这种方式优点是支持异构系统的服务治理,如果许多服务是用不同的语言编写部署的,或者如果你正在运行不可变的第三方应用程序,这就很有好处,因为它对服务的治理是无侵入式的。同时治理模块升级对用户应用是透明的。
缺点也是比较明显的:
-
服务治理进程本身占用的系统资源也不可被忽略,20个服务,每个服务5个pod就会有100个代理容器,这种纯粹的重复都会耗费资源。

-
服务网格将服务治理从应用中分离出来变成独立的进程,这样便增加了两跳网络的通信成本,势必会对整体时延有所增加。

用eBPF解锁内核级服务网格
引入eBPF
由于sidecar模式的缺点,如何减少代理带来的资源占用以及应用到代理之间的网络延迟成为Service Mesh能否推广的关键。理想的服务网格是作为Linux的一部分透明的提供服务,就像今天的TCP一样。
为什么我们以前没有在内核中创建一个服务网格?或者Linux社区不直接解决这些需求?我们知道,Linux内核的发展是非常缓慢而严谨的,它必须确保用户使用的版本是安全的。它如果有bug,那可能就是灾难级的,所以新版本的内核需要几年的时间才能进入用户手中。与之相对应的云原生技术栈,它的发展,更新迭代是非常迅速的。
而eBPF的出现改变了这个状况,它是一种内核技术,它允许自定义程序在内核中运行,从而动态地扩展Linux内核功能。
eBPF有一个巨大的优势,eBPF代码可以在运行时插入到现有的 Linux 内核中,类似于 Linux 内核模块,但与内核模块不同,它可以以安全和可移植的方式进行。这使得 eBPF 的实现能够随着服务网格社区的发展而继续发展,从而使 Linux 内核能够跟上快速发展的云原生技术栈。

告别服务代理,全面拥抱eBPF?
看起来eBPF能做的事情有很多,那我们可以用eBPF将所有功能写入到操作系统内核吗?
简短的回答:这将是相当困难的,而且可能也不是一个正确的做法。eBPF 采用的是一个事件-处理器模型,因此其运行方式有一些限制。你可以把 eBPF 模型看成是内核的 “Function as a service”。例如,eBPF 代码的执行路径必须是完全确定的,会在执行前进行验证,以确保其可以在内核中安全运行。eBPF 程序不能有任意的循环,否则验证程序将不知道程序何时停止执行。简而言之,eBPF 是图灵不完整的。
图灵完备是针对一套数据操作规则而言的概念,数据操作规则可以是一门编程语言,也可以是计算机里具体实现了的指令集。
当这套规则可以实现图灵机的所有功能时,即可以计算出一切可计算问题,就称它具有图灵完备性。
图灵不完备的语言常见原因有循环或递归受限(无法写不终止的程序,如 while(true){}; ), 无法实现类似数组或列表这样的数据结构(不能模拟纸带). 这会使能写的程序有限。图灵不完备不是没有意义的,有些场景我们需要限制语言本身. 如限制循环和递归, 可以保证该语言能写的程序一定是终止的,就像我们的eBPF一样,这也是图灵完备可能带来的坏处。
在许多方面,eBPF是O(1)复杂性的理想选择(例如检查一个数据包,操作一些比特,然后发送它)。实现像HTTP/2和gRPC这样复杂的协议可能是O(n)复杂度,而且非常难以调试。那么,这些L7功能可以驻留在哪里?
Envoy代理已经成为服务网状结构实现的事实上的代理,并且对我们大多数客户需要的第7层功能有非常好的支持。虽然eBPF和Kernel可以用来改善网络的执行(短路最佳路径、卸载TLS/mTLS、可观察性收集等),但复杂的协议协商、解析和用户扩展可以保留在用户空间。对于第7层的复杂情况,Envoy仍然是服务网状结构的数据平面。
因此 eBPF 是优化服务网格的一种强大方式,同时我们认为 Envoy 代理是数据平面的基石。
优化服务网格
Per-Node or Sidecar?
为了减少每个应用运行一个代理带来的资源消耗,可以采用共享代理模式,即一个节点中的所有工作负载使用一个共享代理,这种模型可以提供内存和配置开销的优化,对大型集群而言,内存开销时需要首要考虑的问题,这将是非常有意义的。当我们的代理从sidecar模型转向per-node时,代理为多个程序提供连接,代理必须具有多租户感知。这与我们从使用单个虚拟机转向使用容器时发生的过渡完全相同。由于我们不再使用在每个虚拟机中运行的完全独立的操作系统副本,而开始与多个应用程序共享操作系统,Linux 必须具有多租户感知。这就是命名空间和 cgroup 存在的原因。好在Envoy 已经有了命名空间的初步概念,它们被称为监听器。监听器可以携带单独的配置并独立运行。
但共享代理模型并不适用于所有人。许多企业用户认为,因为采用边车代理可以获得更好的租户和工作负载隔离,可以减少出现问题时的故障域,一些额外的内存开销是值得的。
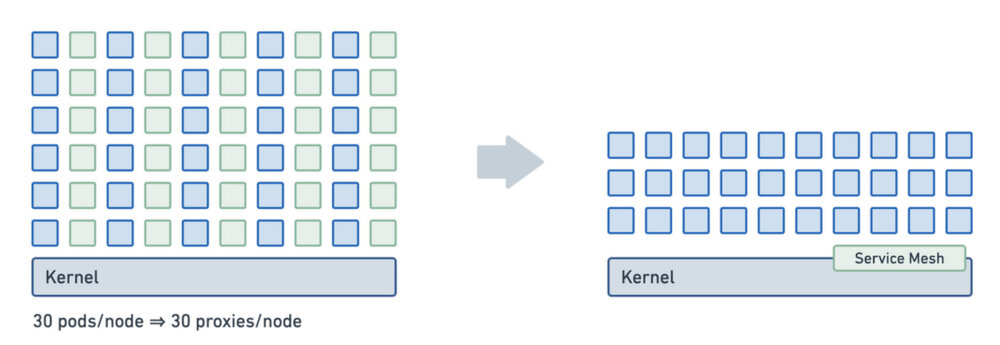
除了这两种方式来优化内存上的开销外,还可以让每个节点上的每个服务账户共享一个代理以及带有微型代理的共享远程代理。


使用eBPF优化网络性能
由于eBPF工作在内核层,这使得它可以绕过内核的部分网络堆栈,使网络性能得到显著改善。

在服务网格的情况下,代理在传统网络中作为 sidecar 运行,数据包到达应用程序的路径相当曲折:入站数据包必须穿越主机 TCP/IP 栈,通过虚拟以太网连接到达 pod 的网络命名空间。从那里,数据包必须穿过 pod 的网络堆栈到达代理,代理将数据包通过回环接口转发到应用程序。考虑到流量必须在连接的两端流经代理,与非服务网格流量相比,这将导致延迟的显著增加。
基于 eBPF 的 Kubernetes CNI 实现,如 Cilium,可以使用 eBPF 程序,明智地钩住内核中的特定点,沿着更直接的路线重定向数据包。这是可能的,因为 Cilium 知道所有的 Kubernetes 端点和服务的身份。当数据包到达主机时,Cilium 可以将其直接分配到它所要去的代理或 Pod 端点。
通过per-node模型+eBPF进行网络加速,我们的服务网格模型看起来将会是这样:

eBPF在云原生中的应用才刚刚开始,一切皆有可能!
参考链接:
https://www.zhaohuabing.com/post/2021-12-19-ebpf-for-service-mesh/
https://cloudnative.to/blog/how-ebpf-streamlines-the-service-mesh/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号