
Kubernetes网络原理
🌟Kubernetes网络模型
kubernetes网络模型设计的一个基础原则就是:每个Pod拥有一个独立IP地址,这个模型也被称为IP-per-Pod模型,并假定所有Pod都在一个可以直接连通的、扁平的网络空间中。所以不管他们是否运行在同一个Node中,都要求他们可以直接通过对方的IP进行访问。
在Kubernetes的世界里,一个Pod内部的所有容器共享一个网络堆栈,IP地址和端口在Pod内部和外部都保持一致,不需要进行NAT转换。这种IP-per-Pod方案很好地利用了现有的各种域名解析和发现机制,而且同一Pod内的容器因为共用一个网络堆栈(IP地址、网络设备和配置等共享),彼此之间可以通过localhost来连接对方的端口,这样同一Pod内的容器隔离性减小了。
因此按照这个原则,kubernetes对集群网络有如下要求:
- 所有容器可以在不用NAT的方式下同别的容器通信。
- 所有节点都可以在不用NAT的方式下同所有容器通信,反之亦然。
- 容器的地址和别人看到的地址是同一个地址。
原生的Docker网络目前还不能很好的支持这些要求。谷歌设计kubernetes的一个主要运行基础就是其公有云GCE,GCE默认支持这些网络要求。如果在私有云上运行Kubernetes+Docker集群,需要自己搭建出符合Kubernetes要求的网络环境。下面简单回顾一下Docker和Linux的网络基础。
🌟Docker网络基础
Docker本身的技术依赖于近年来Linux内核虚拟化技术的发展,所以Docker对Linux内核的特性有很强的依赖。
1. 网络命名空间(network namespace)
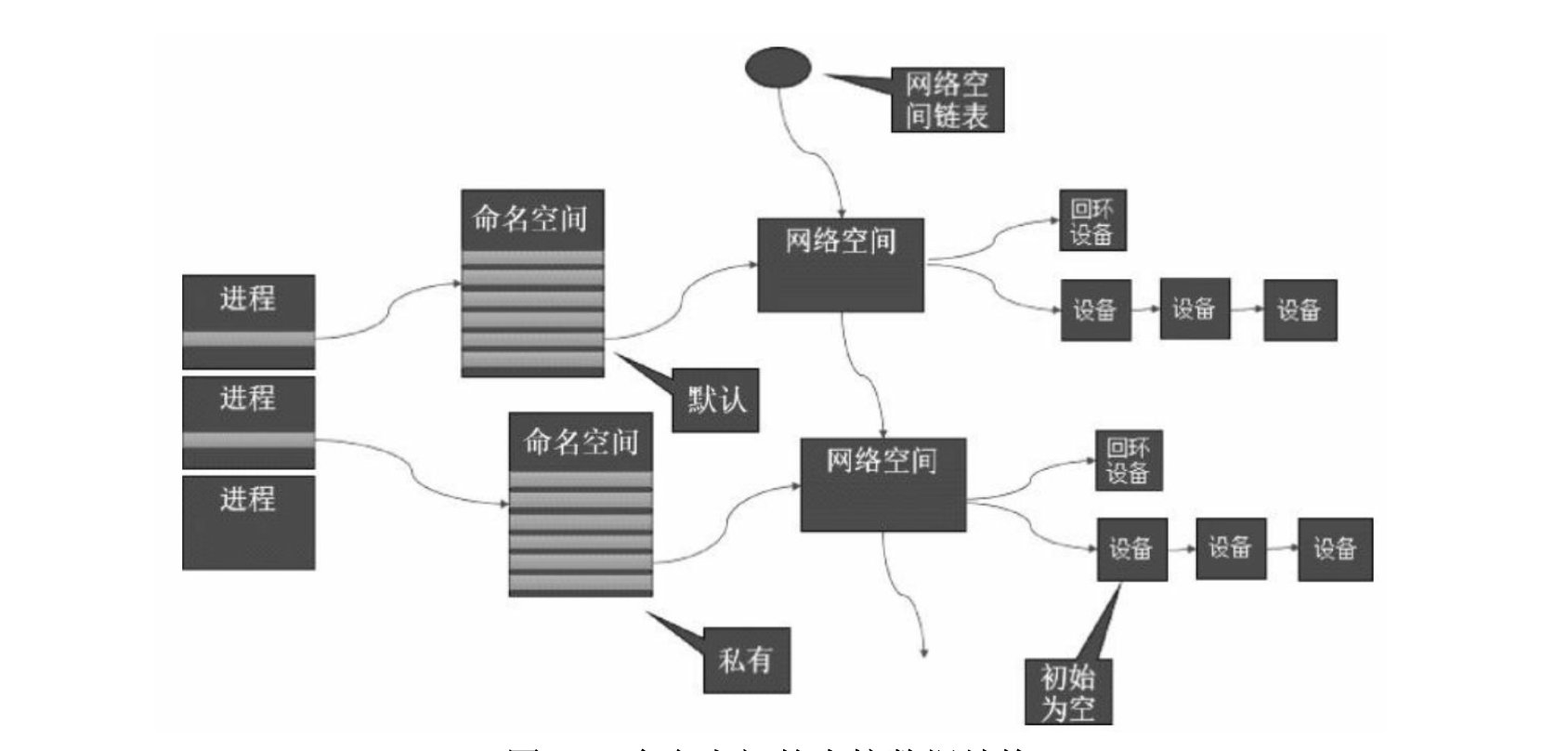
为了支持网络协议栈的多个实例,Linux在网络栈中引入了网络命名空间,这些独立的协议栈被隔离到不容的命名空间中。处于不同命名空间中的网络栈是完全隔离的,彼此之间无法通信,就好像两个“平行宇宙”。通过对网络资源的隔离,就能在一个宿主机上虚拟多个不同的网络环境。Docker正是利用了网络的命名空间特性,实现了不同容器之间的网络隔离。
$ ip netns add <name> #创建命名空间 $ ip netns exec <name> <command> #在指定命名空间执行一个命令 $ ip netns exec <name> bash #进入内部shell界面
2. veth设备对
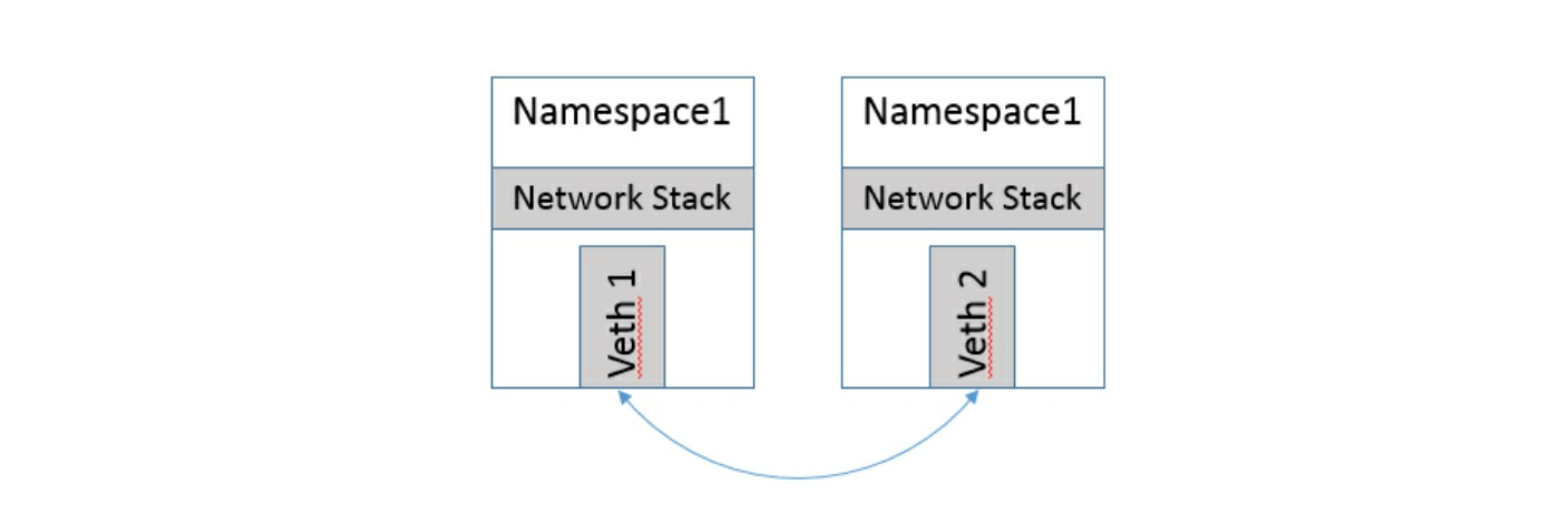
$ ip link add veth0 type Beth peer name veth1 #创建veth设备对 $ ip link set veth1 nets netns1 #把veth1这一头甩给另一个命名空间 $ ip link nets exec netns1 ip link show #在netns1命名空间查看veth1这个头
在Dokcer的实现里面,它处理将Veth放入容器内,还将它的名字改成了enth0,简直以假乱真,你以为它是一个本地网卡吗!!!
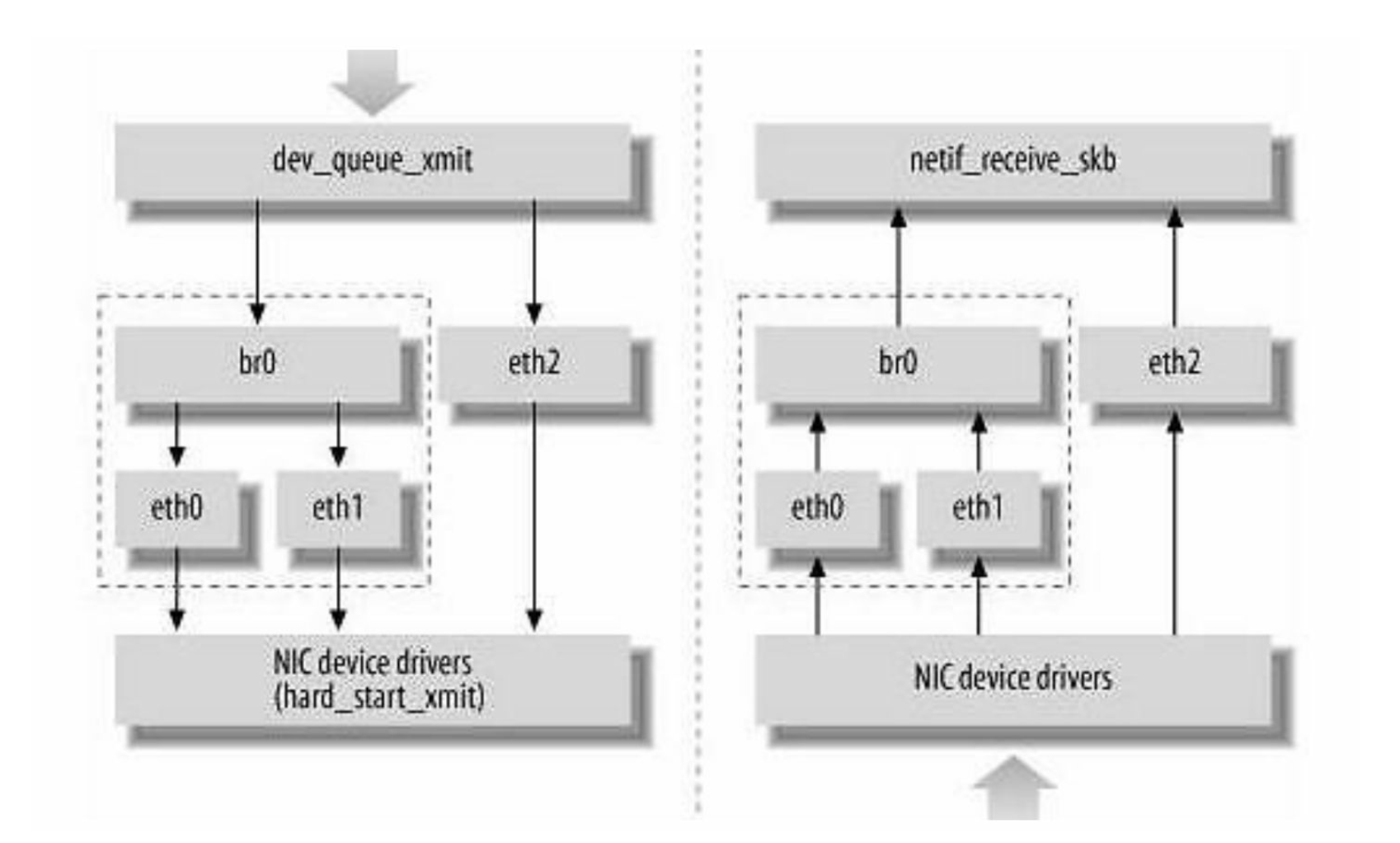
3. 网桥
网桥的概念可以参考网络通信中各种设备介绍,Linux实现的是一个虚拟网桥设备,作用和物理网桥一样。过去Linux主机一般只有一个网卡,现在多网卡机器越来越多,而且有很多虚拟设备的存在,所以Linux的网桥提供了在这些设备之间互相转发数据的二层设备,下图中的网桥可以当作二层交换机来看。
4. iptables和Netfilter
Linux网络协议栈非常搞笑,同时比较复杂。Linux提供了一套机制来为用户实现自定义的数据包处理过程。Netfilter负载在内核中执行各种挂接的规则,运行在内核模式中;而iptables是在用户模式下运行的进程,负责协助和维护内核中Netfilter的各种规则表。二者相互配合来实现整个Linux网络协议栈中灵活的数据包处理机制。
🌟Docker网络实现
Docker一开始并没有考虑到多主机互联的网络解决方案,它一直以来的理念都是“简单为美”,而虚拟化技术中最复杂的部分就是网络技术,Docker明智地避开了这个“雷区”,让其专业人员去用现有的虚拟化网络技术解决Docker主机的互联问题,以免让用户觉得Docker太难,从而放弃学习Docker。Docker成名后,开始重新重视网络的解决方案,在1.9版本后开启了一个宏伟的虚拟化网络解决方案——Libnetwork。但这仅仅是Docker官方的一次“尝试”,未来是否会对虚拟化网络模型产生深远冲击,还不得而知。
🌟Kubernetes网络实现
1. 容器到容器的通信
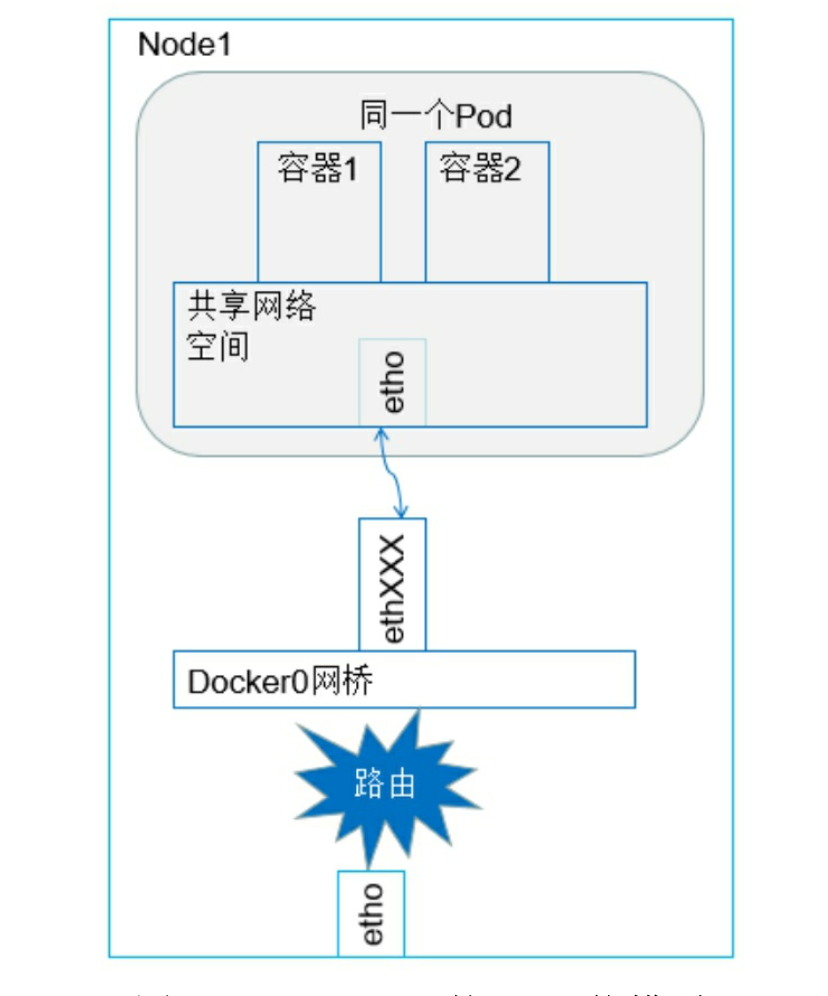
2. Pod之间的通信
- 同一Node内Pod之间的通信
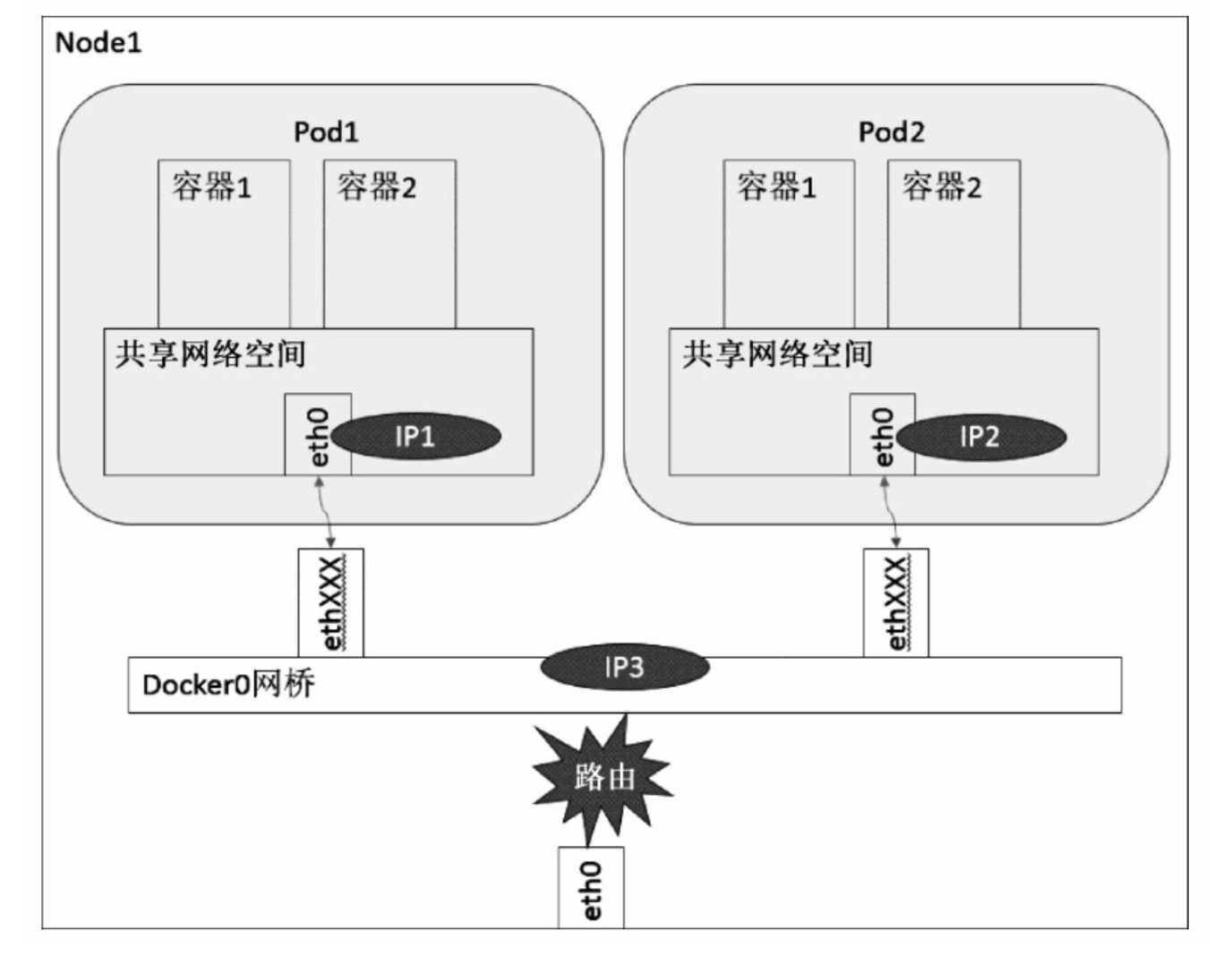
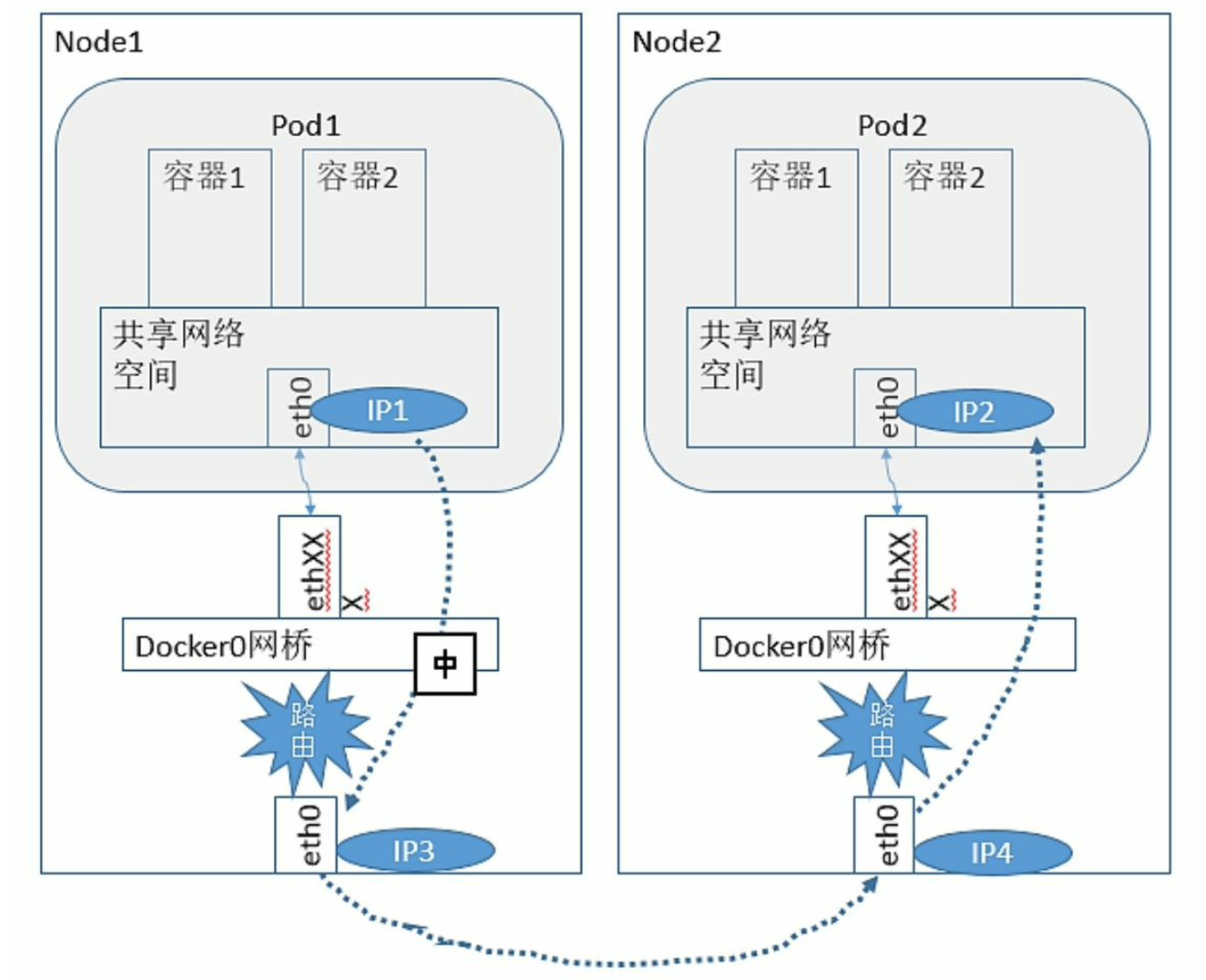
- 不同Node上Pod之间的通信
🌟CNI网络模型
随着容器技术在企业生产系统中的逐步落地,跨主机容器间的网络互通已经成为基本要求。目前主流的容器网络模型主要有Docker公司提出的CNM模型和CoreOS公司提出的CNI模型。
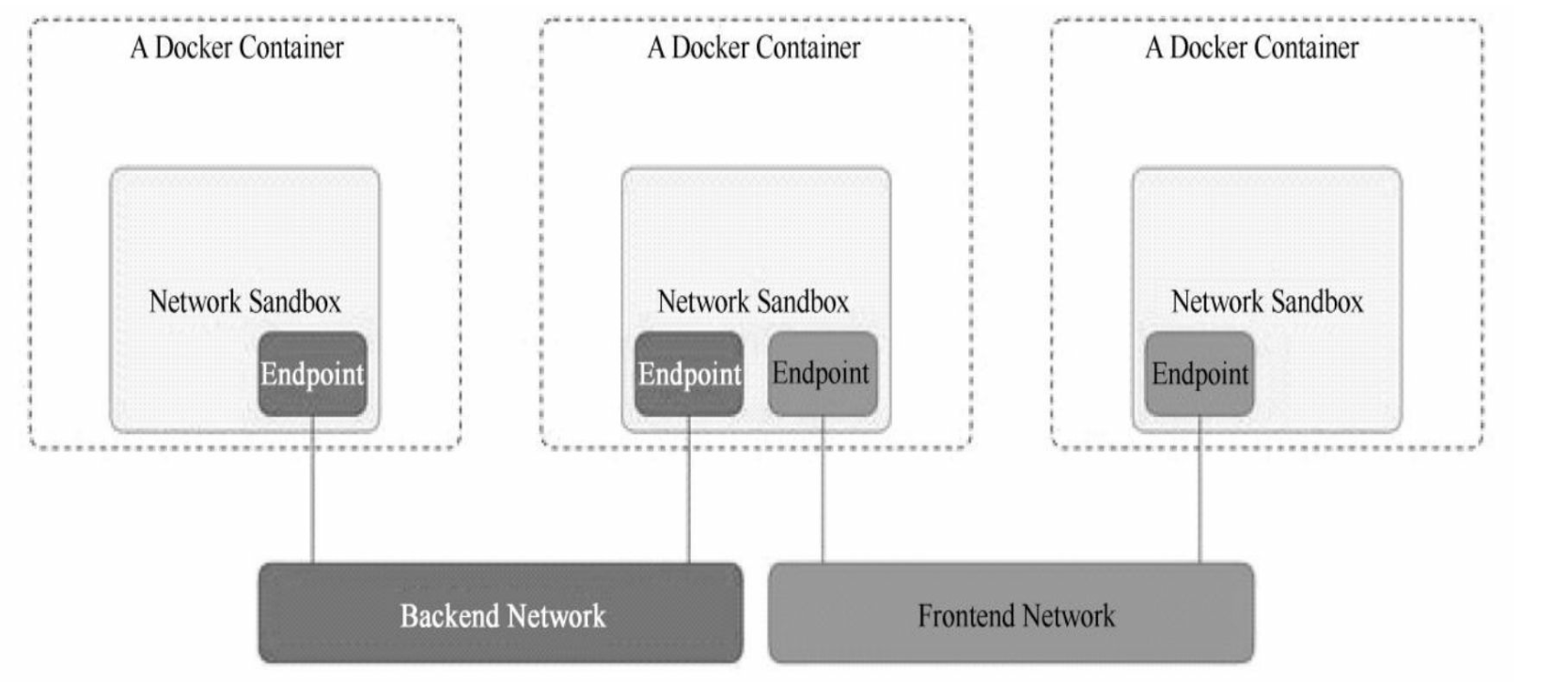
1. CNM模型
CNM网络模型主要通过Network Sandbox,Endpoint和Network这三个组件进行实现,相关介绍参考我的博客。
2. CNI模型
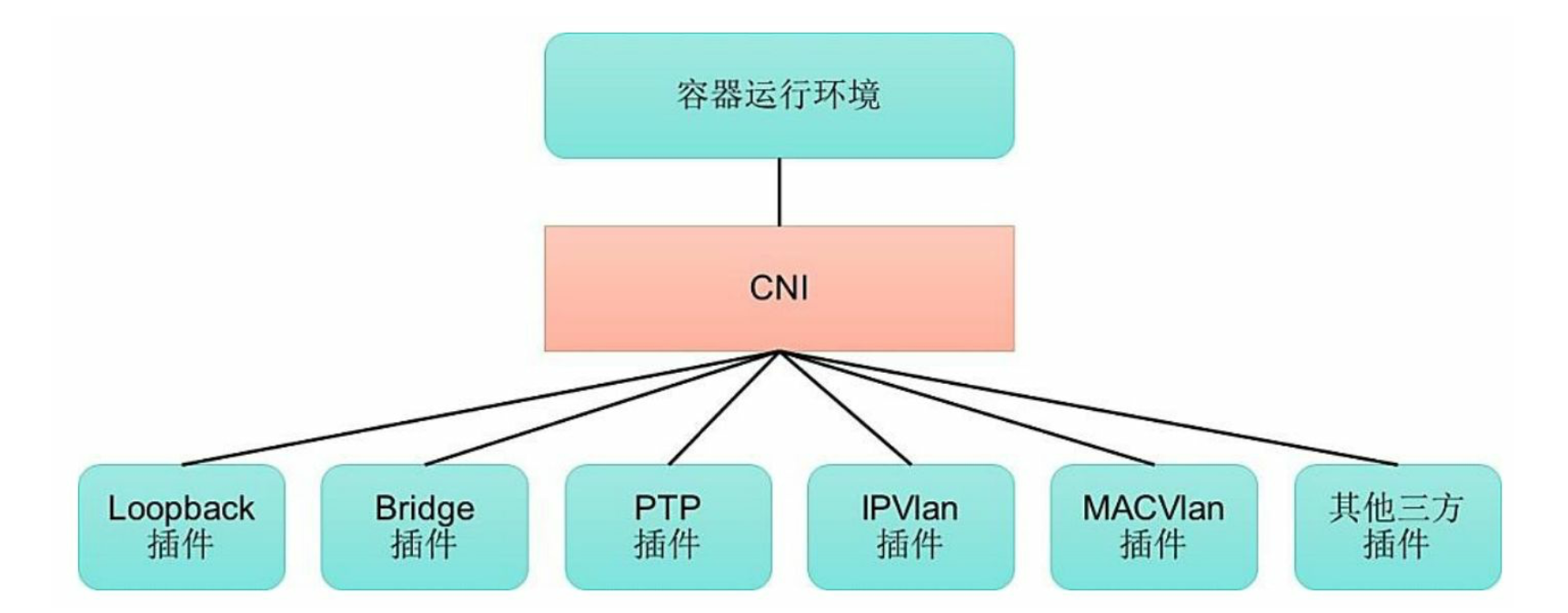
CNI是另一种容器网络规范,现在已经被Kubernetes项目采纳。CNI定义的是容器运行环境与网络插件之间的简单接口规范,通过一个JSON Schema定义CNI插件提供的输入和输出参数。一个容器可以通过绑定多个网络插件加入多个网络中。
CNI仅关注在创建容器时分配网络资源,销毁容器时删除网络资源,这使得CNI规范非常轻巧,易于实现。CNI模型中只涉及两个概念:容器和网络。对容器网络的操作都通过插件进行实现,CNI插件有两种类型:CNI Plugin和IPAM Plugin。前者负责为容器配置网络资源,后者负责对容器的IP地址进行分配和管理。
目前已有多个开源项目支持以CNI网络插件的形式部署到Kubernetes集群中,进行Pod的网络设置和网络策略的设置,包括Calico、Flannel等。
🌟开源的网络组件
Kubernetes的网络模型假定了所有Pod都在一个可以直接连通的扁平网络空间中。在私有云搭建集群时,我们需要自己实现这个网络,将不同节点上的Docker容器之间的互相访问打通。目前已经有多个开源组件支持容器网络模型,包括Flannel、Open vSwitch、直接路由和Calico,我们主要介绍一下Flannel的实现。
Flannel之所以可以搭建Kubernetes依赖的底层网络,是因为它实现了以下两点:
- 给每一个Node上的Docker容器都分配互相不冲突的IP地址。
- 它能在这些IP地址之间建立一个覆盖网络(Overlay Network),通过这个覆盖网络,将数据包原封不动地传递到目标容器内。
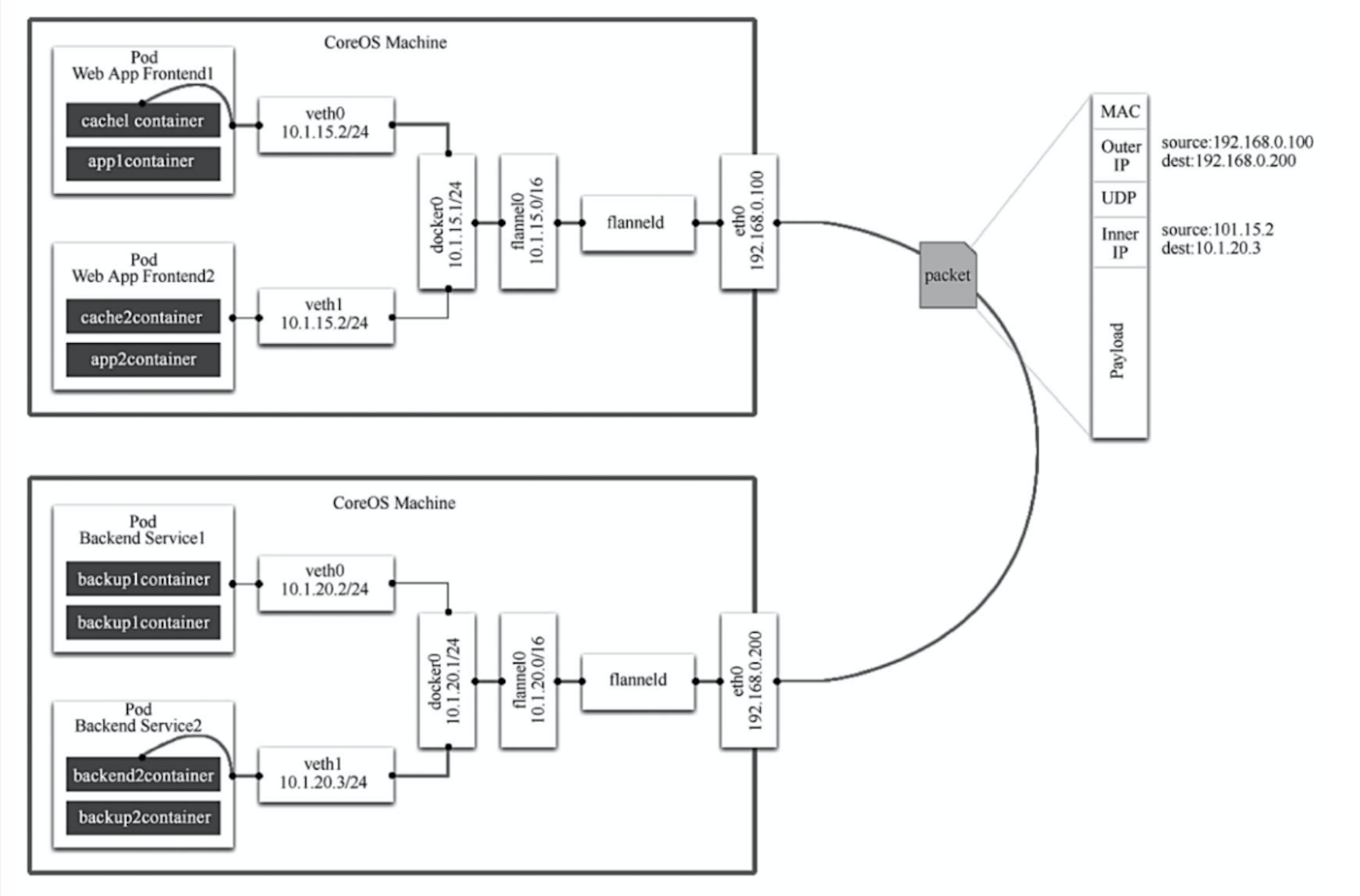
可以看到,Flannel首先创建了一个名为flannel0的网桥,一端连接docker0网桥,另一端连接flanneld的服务进程。
flanneld进程并不简单,它上连etcd来管理可分配的IP地址段资源,同时监控etcd中每个Pod的实际地址,并在内存中建立了一个Pod节点路由表。下连docker0和物理网络,使用内存中的Pod节点路由表,将docker0发送给他的数据包封装起来,利用物理网络的连接将数据包投递到目标flanneld上。通过源flanneld封包和目标flanneld的解包,最终docker0收到的就是原始数据,对容器应用来说是透明的,感觉不到中间Flannel的存在。
总的来说,Flannel通过etcd获取全局IP信息,然后通过修改Docker启动参数--bip来确保给每个Node上的docker0网桥分配不同的IP地址段(因为节点容器IP从docker0网桥上动态获取),这样就保证了每个节点上容器的IP在整个集群中唯一了,而使用集中式存储etcd也很容易理解了。而发送到docker0的数据包经过flannel0网桥后被flanneld进程封装头部信息,也就是目标Pod所在的节点IP后,由Node节点的eth0网卡发出经过物理网络后到达目标Node节点,然后执行相反的操作。至于为什么这样做,相信看完前面的知识就很容易理解了。
由于数据包发送到目标节点的过程中经历了flannel0和flanneld进程等一系列繁琐的步骤,所以会引入一些网络的时延消耗。
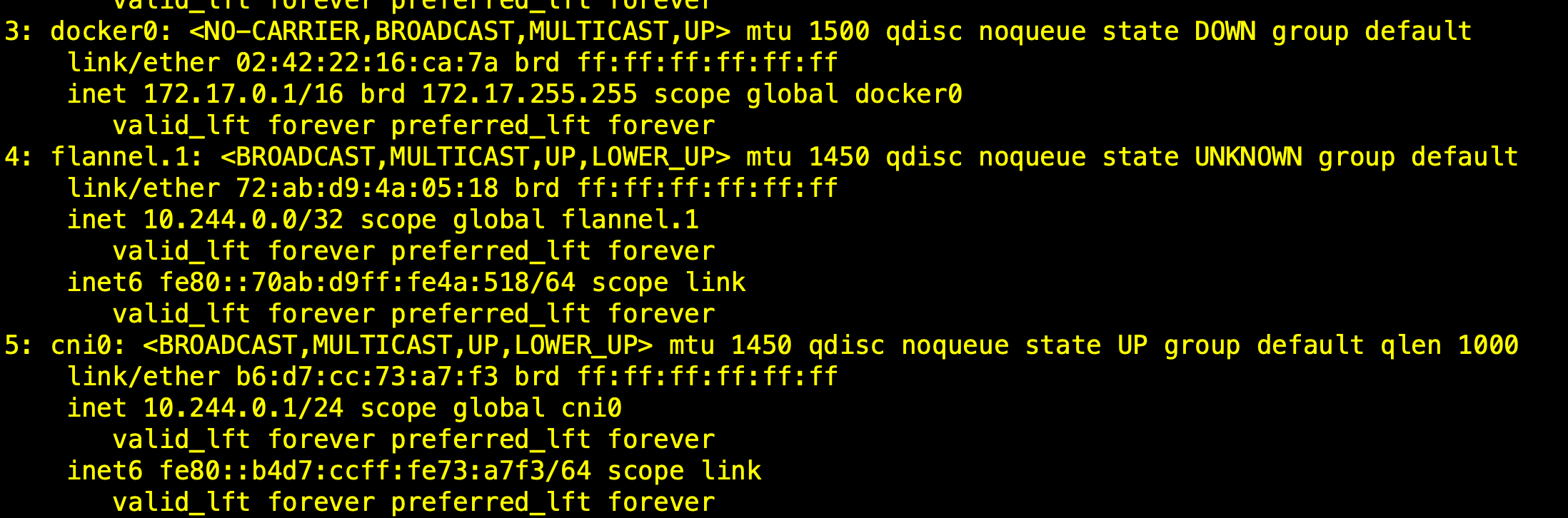
当配置完Flannel查看节点网卡信息时候,如果发现docker0没有被覆盖,但多了一个cni0的网卡。可能是因为Flannel版本的问题,它不会去覆盖docker0网桥,而是新建一个网桥cni0,flannel0连接的是cni0而不是docker0,k8s集群创建的容器也是通过cni0来动态获取IP的。

参考书目:《Kubernetes权威指南第四版》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号