


深度学习图像处理CV算法合集
图像识别CNN
0.各种卷积操作
参考:https://blog.csdn.net/weixin_43624538/article/details/96917113
1.Alexnet
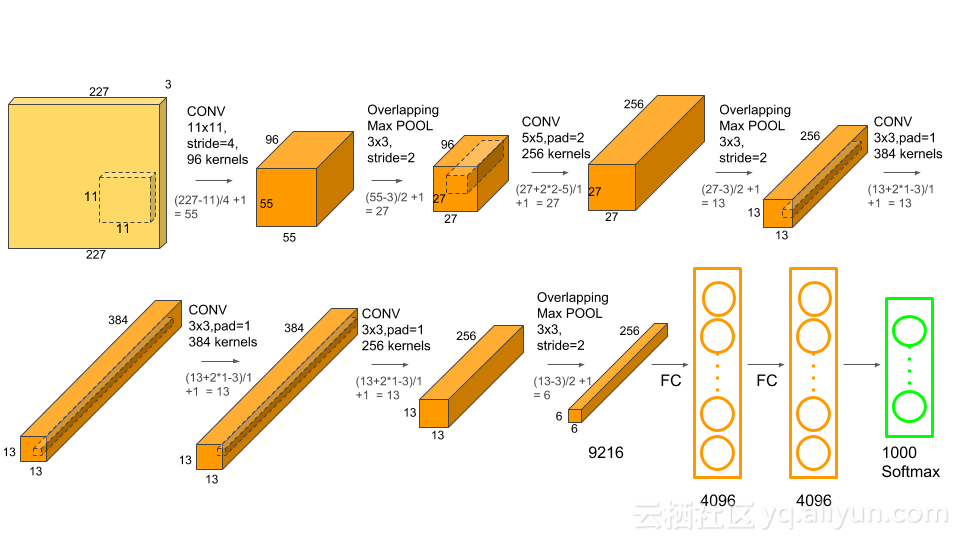
1.1 论文:ImageNet Classification with Deep Convolutional Neural Networks
1.2 过程
- 输入Input的图像规格: 224X224X3(RGB图像),实际上会经过预处理变为:227X227X3
- 96个大小规格为11X11X3的卷积核(步长为4),进行特征提取,卷积后的数据经过Relu激励变为:55X55X96 [(227-11)/4+1=55]
- 降采样pool1的核:3X3 步长:2,通过最大池化进行降采样之后的数据为27X27X96
- 256个5X5大小的卷积核(步长1)对27X27X96个特征图,进行进一步提取特征,然后进行relu操作,27X27X256
- 降采样pool2的核:3X3 步长:2,pool2(池化层)降采样之后的数据为13X13X256
- 384个卷积核(3X3,步长为1),没有降采样,13X13X384
- 256个卷积核(3X3,步长为1),没有降采样,13X13X256
- 降采样操作pool3的卷积核:3X3 步长:2,pool3(池化层)降采样之后的数据为6X6X256
- 两层全联接,并进行dropout,4096X1
- 最后输出层全联接,1000X1
1.3 经验
- Alexnet中采用的是最大池化,是为了避免平均池化的模糊化效果,从而保留最显著的特征
- AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性,减少了信息的丢失。
https://www.cnblogs.com/wangguchangqing/p/10333370.html
https://www.jianshu.com/p/00a53eb5f4b3
https://blog.csdn.net/luoluonuoyasuolong/article/details/81750190
2.VGG
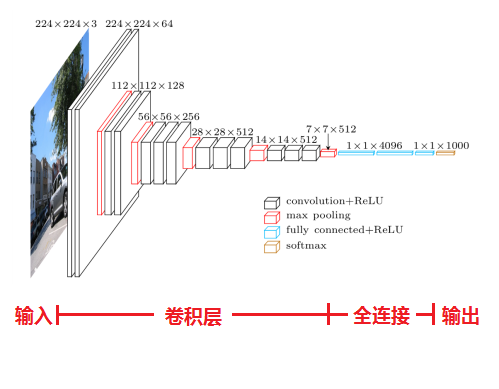
2.0 论文:《Very Deep Convolutional Networks for Large-Scale Image Recognition》(基于甚深层卷积网络的大规模图像识别)
2.1 加深版本的AlexNet,都是由卷积层、全连接层两大部分构成。
- 输入224x224x3的图片,预处理(preprocession)时计算出三个通道的平均值,在每个像素上减去平均值(处理后迭代更少,更快收敛)。
- 经64个3x3的卷积核作两次卷积+ReLU,卷积后的尺寸变为224x224x64
- 作max pooling(最大化池化),池化单元尺寸为2x2(效果为图像尺寸减半),池化后的尺寸变为112x112x64
- 经128个3x3的卷积核作两次卷积+ReLU,尺寸变为112x112x128
- 作2x2的max pooling池化,尺寸变为56x56x128
- 经256个3x3的卷积核作三次卷积+ReLU,尺寸变为56x56x256
- 作2x2的max pooling池化,尺寸变为28x28x256
- 经512个3x3的卷积核作三次卷积+ReLU,尺寸变为28x28x512
- 作2x2的max pooling池化,尺寸变为14x14x512
- 经512个3x3的卷积核作三次卷积+ReLU,尺寸变为14x14x512
- 作2x2的max pooling池化,尺寸变为7x7x512
- 与两层1x1x4096,一层1x1x1000进行全连接+ReLU(共三层)
- 通过softmax输出1000个预测结果
2.2 经验
- 1、LRN层无性能增益(A-LRN)
- 2、随着深度增加,分类性能逐渐提高(A、B、C、D、E)
- 3、多个小卷积核比单个大卷积核性能好(B)
- 最佳模型:VGG16,从头到尾只有3x3卷积与2x2池化,简洁优美;
2.3 VGG与Alexnet相比,具有如下改进几点:
- 去掉了LRN层,作者发现深度网络中LRN的作用并不明显,干脆取消了
- 采用更小的卷积核-3x3,Alexnet中使用了更大的卷积核,比如有7x7的,因此VGG相对于Alexnet而言,参数量更少
- 池化核变小,VGG中的池化核是2x2,stride为2,Alexnet池化核是3x3,步长为2
2.4 问题
- 虽然 VGGNet 减少了卷积层参数,但实际上其参数空间比 AlexNet 大,其中绝大多数的参数都是来自于第一个全连接层,耗费更多计算资源
3.Resnet
3.1 论文:Deep Residual Learning for Imafge Recognition
3.2 模型
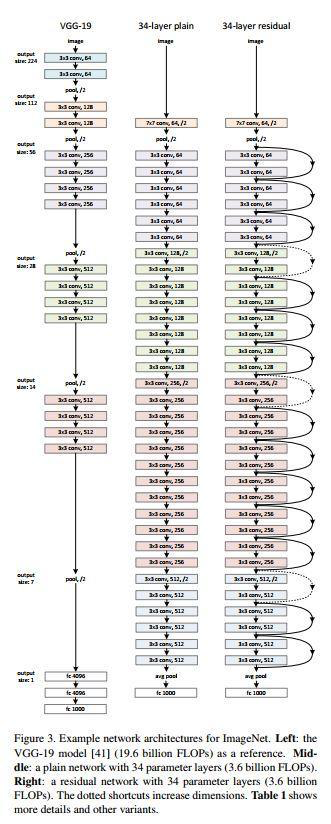
其中实线箭头的处理——即本文核心:残差块:

思想:确保输出的结果至少不会比输入更差。
3.3 衍生网络:Inception-Resnet,ResNeXt
图像识别的常用处理方法
1.特征图是否要尽可能保留RGB通道信息
2.通过权值共享来节约空间和提高效率(理解如何做到的)
3.合适的激励函数(如RELU,softmax),来确保特征图的值范围在合理范围之内。越深的网络反向梯度越难传导。
4.LRN处理
5.池化
6.dropout随机从丢掉一些节点信息。经过交叉验证,隐含节点dropout率等于0.5的时候效果最好,原因是0.5的时候dropout随机生成的网络结构最多。
7.数据增强:先resize,然后random_crop,flip操作(裁剪,镜像,标准化)
8.正则项
9.交叉熵,欧式距离,最小化方法?
10.学习率、batch_size、step定义与选择、动态调整
11.动量以加快学习速度,tf.train.momentumOptimizer
12. fine-tune 训练
深度学习的图像网络处理思路
增加图像分类的精度很重要的一个方面就是增加网络学习特征的质量。
1.增加深度——1000层残差网络
2.增加宽度——Wide Residual Networks
- 增大宽度可以增加各种深度的残差模型的性能
- 只要参数的数量可以接受,宽度和深度的增加就可以使性能提升。
- 在相同的参数数量下,更深的模型并不比更宽的模型有更好的性能。
目标检测
1.传统方法:Cascade + HOG/DPM + Haar/SVM以及上述方法的诸多改进、优化。
1.DPM:DPM的本质就是弹簧形变模型,参考:https://blog.csdn.net/ttransposition/article/details/12966521

2.提取候选区域,并对相应区域进行以深度学习方法为主的分类的方案
0.生成候选区域的方法:
- objectness
- selective search
- category-independen object proposals
- constrained parametric min-cuts(CPMC)
- multi-scale combinatorial grouping
- Ciresan
1.R-CNN(Selective Search + CNN + SVM)参考https://blog.csdn.net/briblue/article/details/82012575
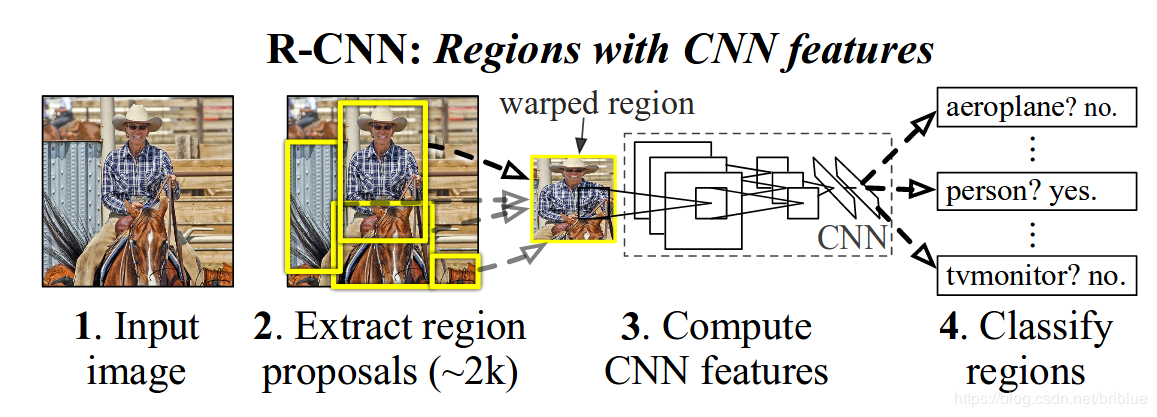
- 算法思路
- 给定一张输入图片,从图片中提取 2000 个类别独立的候选区域。
- 对于每个区域利用 CNN 抽取一个固定长度的特征向量。
- 再对每个区域利用 SVM 进行目标分类。
- 测试:计算 IoU 指标,采取非极大性抑制,以最高分的区域为基础,剔除掉那些重叠位置的区域。
2.Fast R-CNN(Selective Search + CNN + ROI)https://www.jianshu.com/p/26ca6f6bd1a1
https://www.jianshu.com/p/fbbb21e1e390
- 相比R-CNN最大的区别,在于RoI池化层和全连接层中目标分类与检测框回归微调的统一。
- 在推荐区域之前,先对图像执行特征提取工作,通过这种办法,后面只用对整个图像使用一个 CNN(之前的 R-CNN 网络需要在 2000 个重叠的区域上分别运行 2000 个 CNN)。
- 将支持向量机替换成了一个 softmax 层,这种变化并没有创建新的模型,而是将神经网络进行了扩展以用于预测工作。
3.Faster R-CNN(RPN + CNN + ROI)
- 用一个快速神经网络代替了之前慢速的选择搜索算法(selective search algorithm)。具体而言,它引入了一个 region proposal 网络(RPN)。
-
- 在最后卷积得到的特征图上,使用一个 3x3 的窗口在特征图上滑动,然后将其映射到一个更低的维度上(如 256 维),
- 在每个滑动窗口的位置上,RPN 都可以基于 k 个固定比例的 anchor box(默认的边界框)生成多个可能的区域。
- 每个 region proposal 都由两部分组成:a)该区域的 objectness 分数。b)4 个表征该区域边界框的坐标。
4.Mask rcnn
- 何恺明基于以往的Faster Rcnn架构提出的新的卷积网络.
- 掩码
- https://blog.csdn.net/weixin_43624538/article/details/88734864
5.R-FCN(RPN+)论文https://www.jianshu.com/p/e90692259530
- 通过最大化共享计算来提升速度。
- 位置敏感ROI池化层——图像分类:要求图像具有平移不变性(translation invariance)目标检测:要求图像具有位置敏感性(translation variance)
https://blog.csdn.net/qq_30622831/article/details/81455550
6.SPPNet(ROI Pooling)Spatial Pyramid Pooling(空间金字塔池化)
- 论文:Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition
7.MobileNet
3.基于深度学习的回归方法
1.YOLO
- 不再需要中间的region proposal找目标,直接回归便完成了位置和类别的判定。
- 没有了Region Proposal机制,只使用7*7的网格回归会使得目标不能非常精准的定位,这也导致了YOLO的检测精度并不是很高。
https://www.jianshu.com/p/13ec2aa50c12
2.SSD(Single-Shot Detector)
- SSD结合YOLO的回归思想以及Faster R-CNN的anchor机制
3.DenseBox
4.cornerNet
基于关键点的实时且精度高的目标检测算法
参考:https://my.oschina.net/u/876354/blog/1634322
https://www.jiqizhixin.com/articles/2017-09-18-7
https://cloud.tencent.com/developer/news/281788

