


机器学习——激活函数理解
激活函数
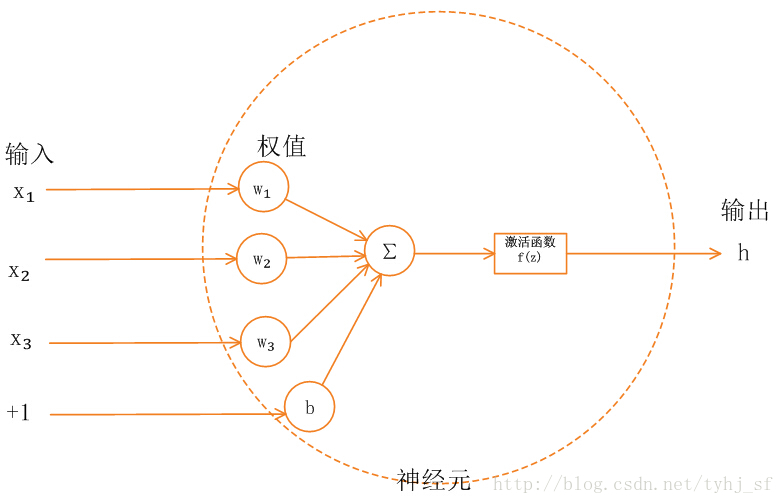
作用:
- 如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层节点的输入都是上层输出的线性函数,输出都是输入的线性组合,与没有隐藏层效果相当。
- 2线性的表达能力太有限了,即使经过多层网络的叠加,y=ax+b无论叠加多少层最后仍然是线性的,增加网络的深度根本没有意义。
- 对于y=ax+b 这样的函数,当x的输入很大时,y的输出也是无限大小的,经过多层网络叠加后,值更加膨胀的没边
- 引入非线性函数作为激励函数,这样深层神经网络表达能力就更加强大(不再是输入的线性组合,而是几乎可以逼近任意函数)。?:为什么非线性化后,增加网络就变得有意义?体现在哪里?
类别
| TF调用 | 公式 | 图像 | 导数 | 优点 | 缺点 | |
| sigmoid | |
|
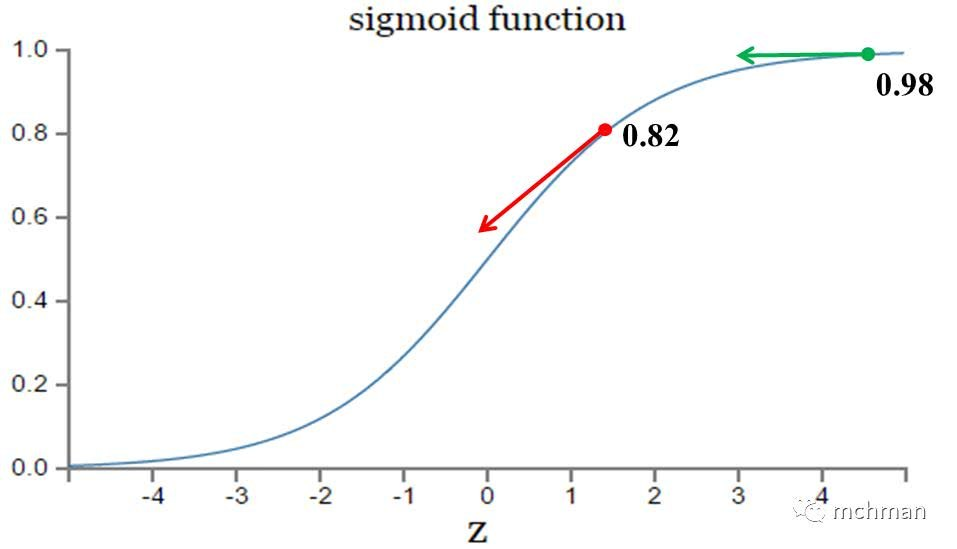
梯度反向传递时导致梯度爆炸和梯度消失 其中梯度爆炸发生的概率非常小 而梯度消失发生的概率比较大。 sigmoid输出永远是正数;非零中心 |
|||
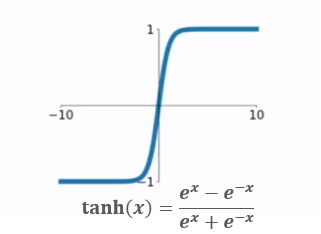
| tanh | 输出(-1,1) | 没有解决“梯度消失问题” | ||||
| ReLU | 不会有梯度消失问题 | 输入负数,则完全不激活,ReLU函数死掉 | ||||
| Leaky ReLU(LReLU) | ||||||
| ELU | ||||||
| Maxout | ||||||
| softmax |
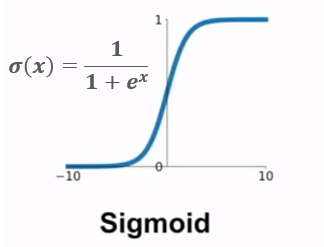
1.sigmoid函数
2.tanh
3.relu
4.softmax
- 输出层第i个神经元的Softmax函数表达式:
,其中k为类别的个数。
- 二分类在输出层之后一个单元不同的是,使用softmax的输出层拥有多个单元。
- softmax 进行分类时,类与类之间是互斥的;sigmoid 函数进行分类时,类与类之间并不是互斥的;
- softmax 函数多类分类问题,大多数损失函数为categorical_crossentropy,取概率分布中最大的作为最终的分类结果;
- sigmoid 函数在多标签分类中,大多使用binary_crossentropy损失函数,设置一个概率阈值,如果概率值大于阈值,则判定属于该类别符合,会造成一个样本具有多个类别。
选择
在同一个模型中,激活函数不会混搭使用,选定一个就用一个。一般最好的经验法则是使用ReLU函数,但是要谨慎的调节学习率。像LReLU,PReLU,ELU,Maxout这些函数则实验性强一点(实用性弱一点),但也可以试下。tanh和sigmoid就em....,算了吧。

参考:
https://segmentfault.com/a/1190000016048441
https://blog.csdn.net/tyhj_sf/article/details/79932893
https://www.jianshu.com/p/d49610e55632

