
4.tensorflow——CNN
1.CNN结构:X-->CONV(relu)-->MAXPOOL-->CONV(relu)-->FC(relu)-->FC(softmax)-->Y
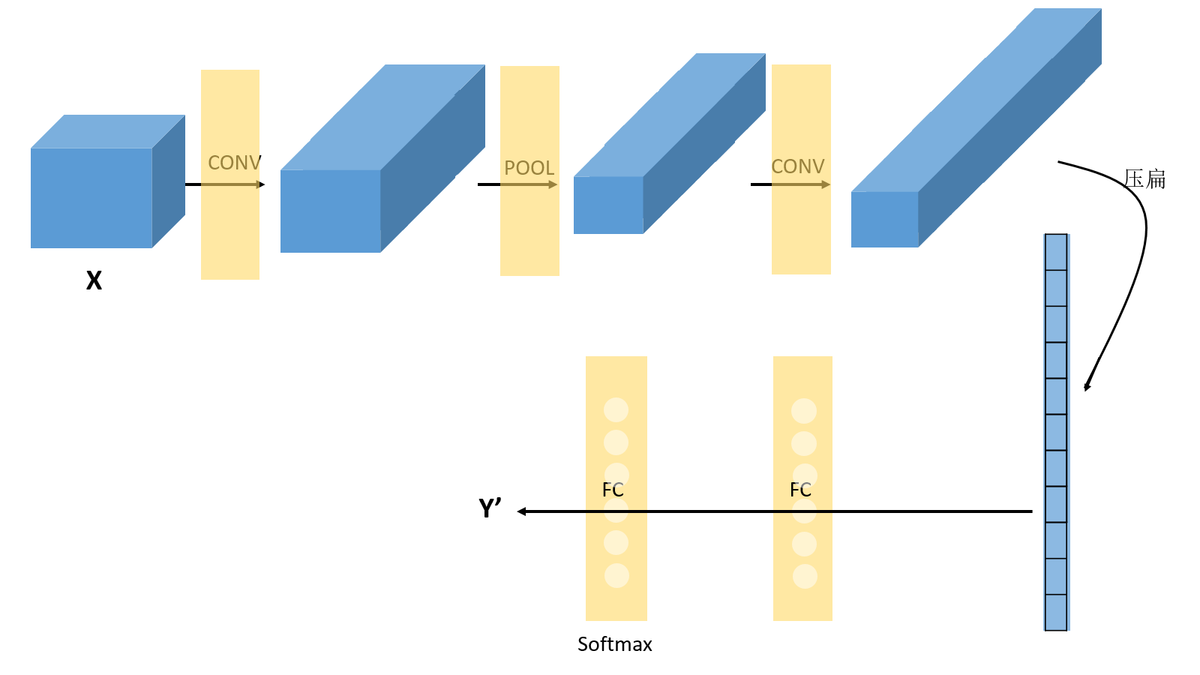
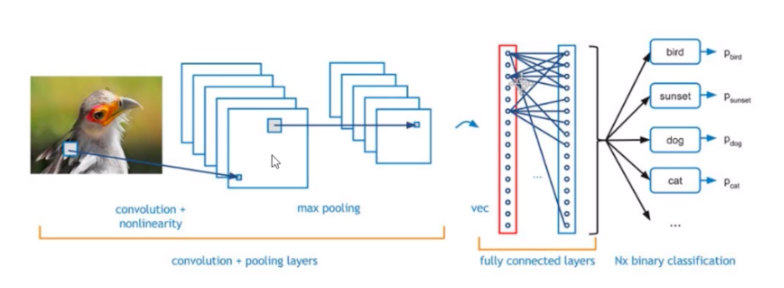
1.1 卷积层:提取特征,改变特征图的个数
- 卷积
- tensorflow卷积函数,tf.nn.conv2d(input=x,filter=W_conv1,strides=[1,1,1,1],padding='SAME')
1.2 池化层:缩小图片,不改变特征图个数
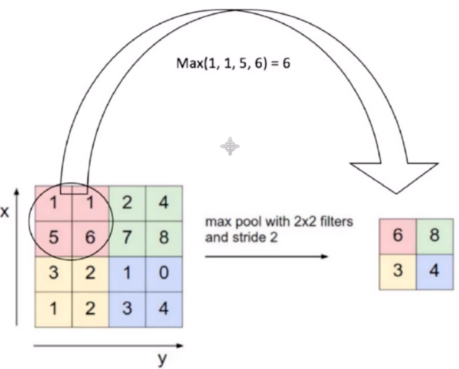
- 针对卷积层输出的特征图结果,为了提取一定区域的主要特征,并减少参数数量,防止模型过拟合。
- 除了MaxPooling,还有AveragePooling,顾名思义就是取那个区域的平均值。
- tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
- 池化带来的结果就是:图片缩小啦
1.3 全链层:特征组合
- 先将多维的数据进行“扁平化”,也就是把 (height,width,channel)的数据压缩成长度为 height × width × channel 的一维数组,然后再与 FC层连接,这之后就跟普通的神经网络无异了。
1.4 输出分类
2.相关辅助操作
- tf.truncated_normal(),截断正态分布随机数,https://blog.csdn.net/justgg/article/details/94362621
其他补充知识
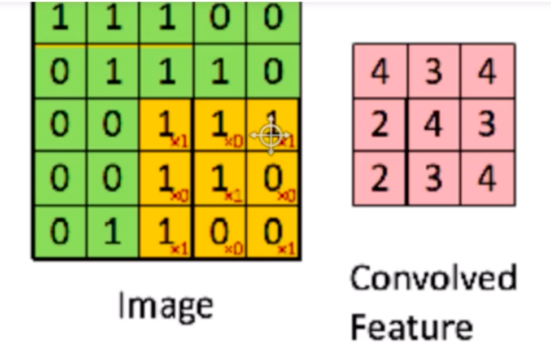
1.卷积
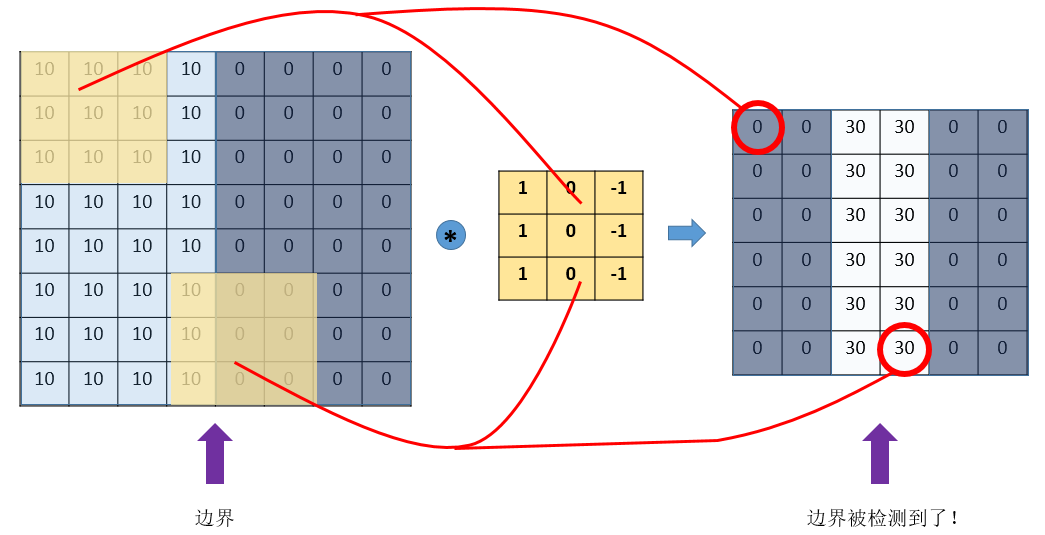
- 滤波器(filter,也称为kernel),大小3×3。
- 用这个filter,往我们的图片上“盖”,覆盖一块跟filter一样大的区域之后,对应元素相乘,然后求和。计算一个区域之后,就向其他区域挪动,接着计算,直到把原图片的每一个角落都覆盖到了为止。这个过程就是 “卷积”。
- 通过设计特定的filter,让它去跟图片做卷积,就可以识别出图片中的某些特征,比如边界。
- CNN(convolutional neural network),主要就是通过一个个的filter,不断地提取特征,从局部的特征到总体的特征,从而进行图像识别等等功能。
- 这些filter及每个filter中的各个数字,就是参数,可以通过大量的数据,来 让机器自己去“学习”这些参数嘛。这,就是CNN的原理。
2.padding 填白
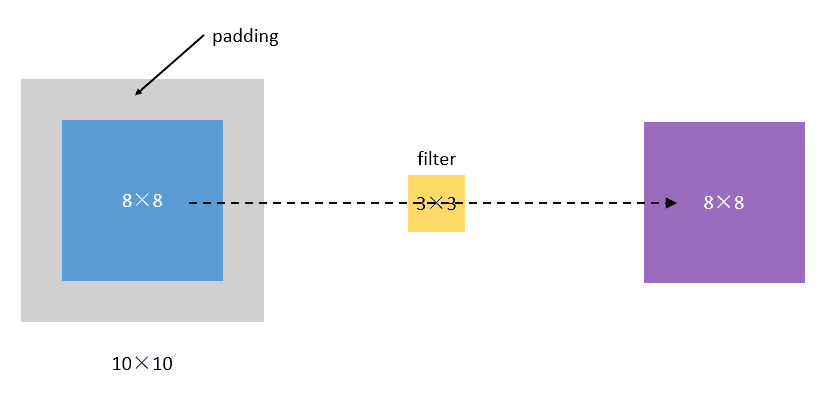
- 每次卷积,图像都缩小,这样卷不了几次就没了;
- 相比于图片中间的点,图片边缘的点在卷积中被计算的次数很少。这样的话,边缘的信息就易于丢失。
- 采用padding的方法。我们每次卷积前,先给图片周围都补一圈空白,让卷积之后图片跟原来一样大,同时,原来的边缘也被计算了更多次。
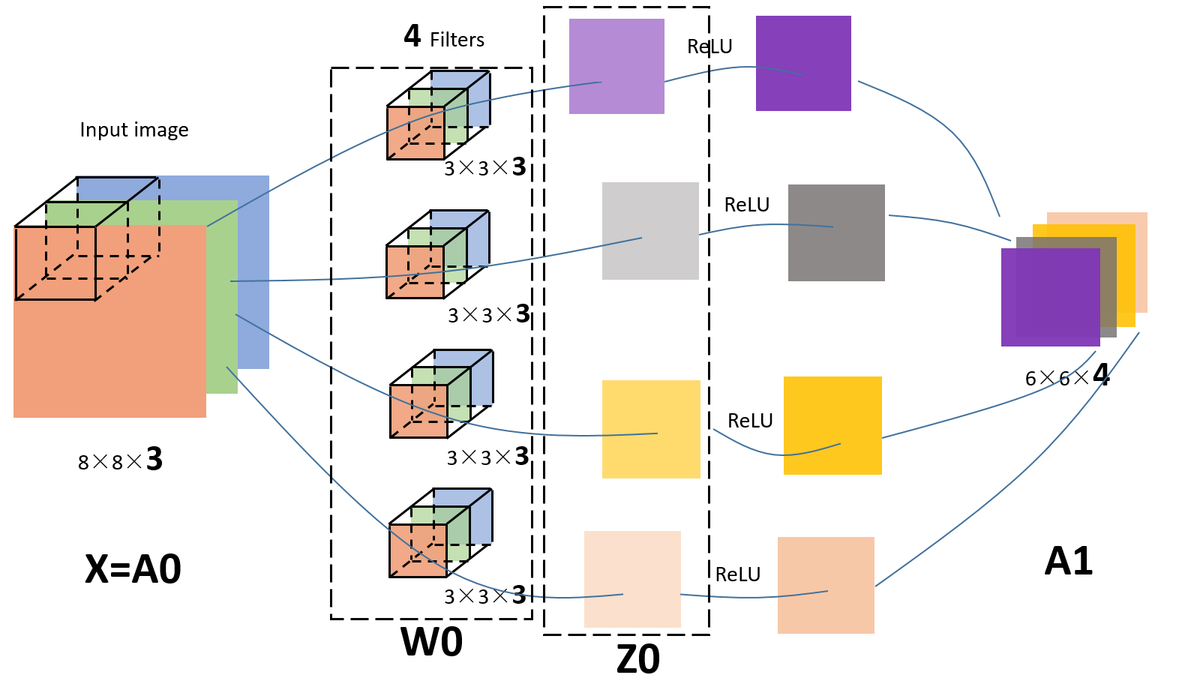
3.对多通道(channels)图片的卷积
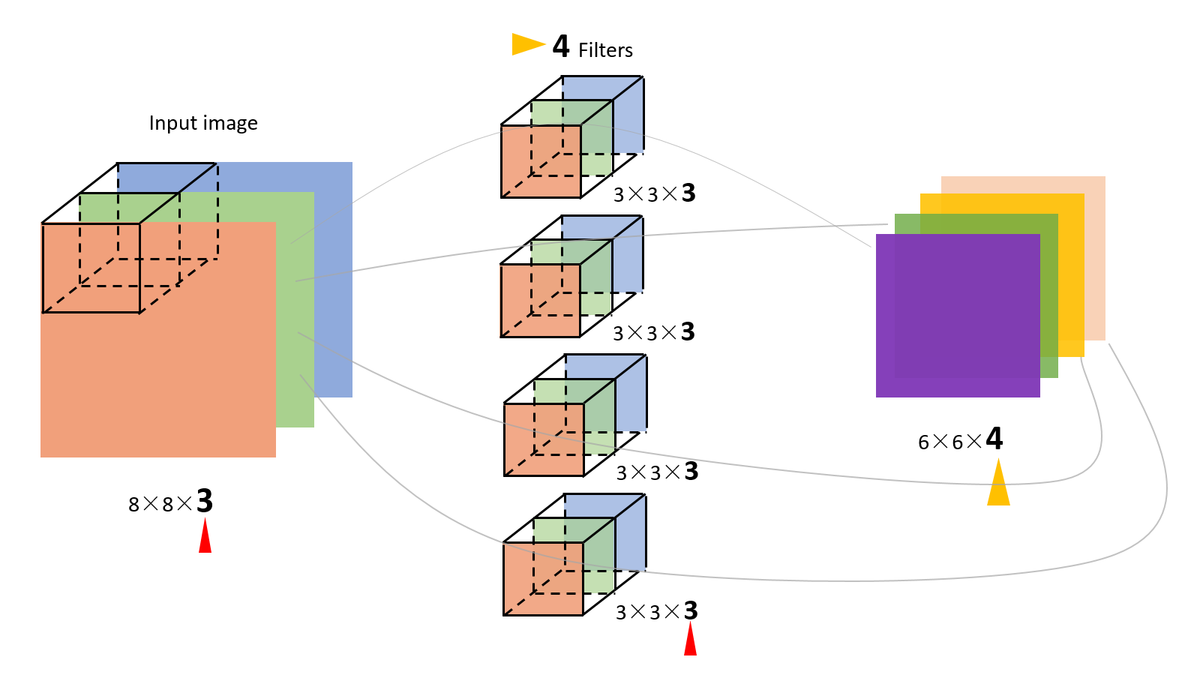
- 输入图片是三维的(即增多了一个channels),比如是(8,8,3)
- filter的维度:(3,3,3),最后一维要跟输入的channel维度一致。这个时候的卷积,是三个channel的所有元素对应相乘后求和,也就是之前是9个(3X3)乘积的和,现在是27个(3X3X3)乘积的和。
- 如果用4个filter,则输出的维度则会变为(6,6,4)
4.激活函数
5.softmax
- Softmax函数常用来最后的一层,并作为输出层进行多分类判别。
6.损失函数
卷积神经网络的精髓
1.CNN,无非就是把FC改成了CONV和POOL,就是把传统的由一个个神经元组成的layer,变成了由filters组成的layer。
- 参数共享机制(parameters sharing)
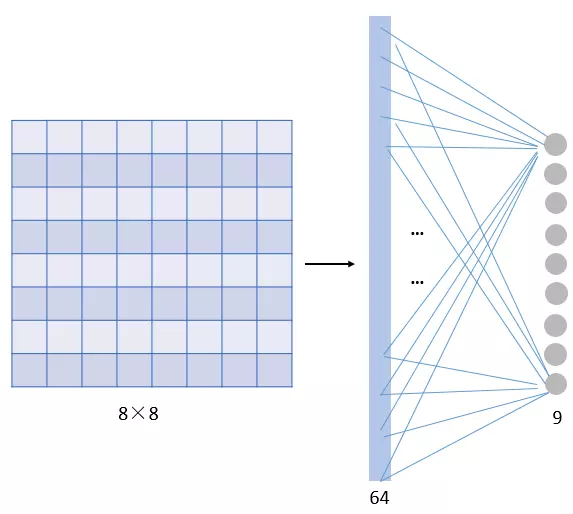
那这一层我们需要多少个参数呢?需要 64×9 = 576个参数(先不考虑偏置项b)。因为每一个链接都需要一个权重w。
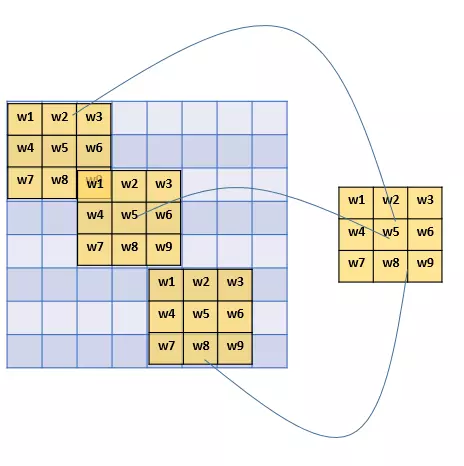
- 因为,对于不同的区域,我们都共享同一个filter,因此就共享这同一组参数。
- filter是用来检测特征的,那一个特征一般情况下很可能在不止一个地方出现,比如“竖直边界”,就可能在一幅图中多出出现,那么 我们共享同一个filter不仅是合理的,而且是应该这么做的。
-
由此可见,参数共享机制,让我们的网络的参数数量大大地减少。这样,我们可以用较少的参数,训练出更加好的模型,典型的事半功倍,而且可以有效地 避免过拟合。
同样,由于filter的参数共享,即使图片进行了一定的平移操作,我们照样可以识别出特征,这叫做 “平移不变性”。
2.连接的稀疏性(sparsity of connections)
- 由卷积的操作可知,输出图像中的任何一个单元,只跟输入图像的一部分有关系:
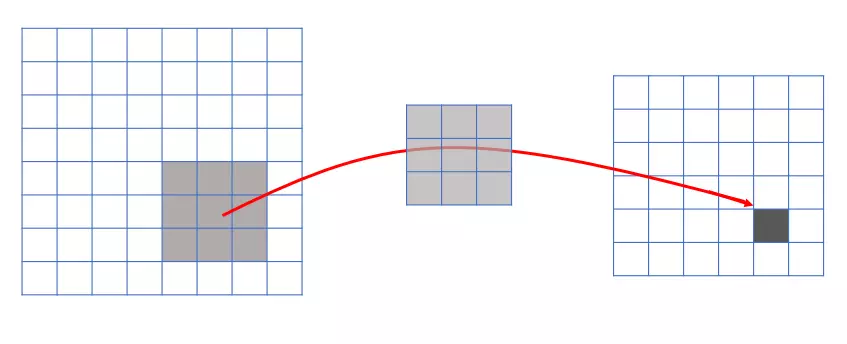
- 传统神经网络中,由于都是全连接,所以输出的任何一个单元,都要受输入的所有的单元的影响。这样无形中会对图像的识别效果大打折扣。比较,每一个区域都有自己的专属特征,我们不希望它受到其他区域的影响。
1.lrn层https://blog.csdn.net/banana1006034246/article/details/75204013
2.数据集:www.cs.toronto.edu/~kriz/cifar.html
参考:https://www.jianshu.com/p/c0215d26d20a
