
1. 理解单线程模型
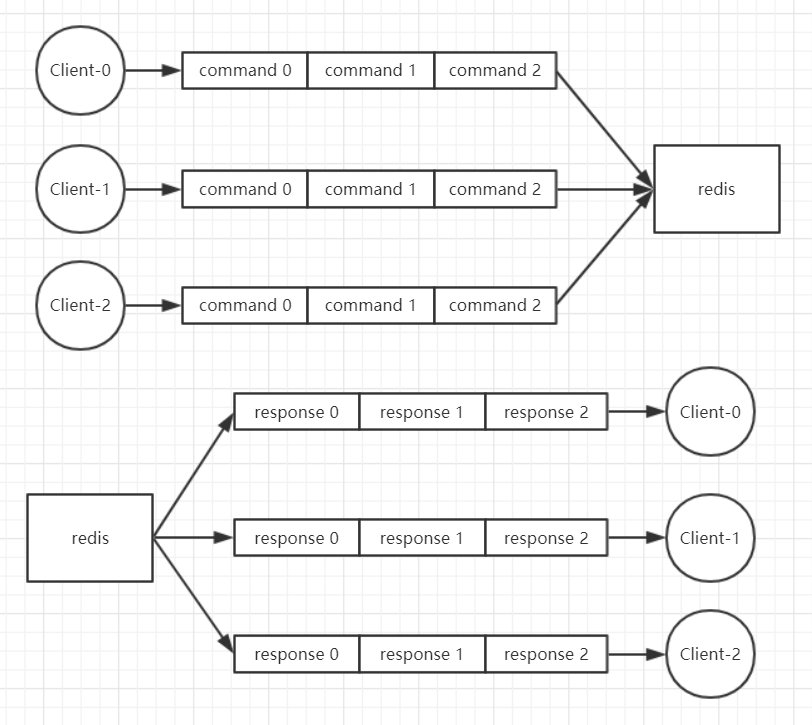
- redis 会将每个客户端都关联一个指令队列。客户端的指令通过队列来按顺序处理,先到先服务。
- 在一个客户端的指令队列中的指令是顺序执行的,但是多个指令队列中的指令是无法保证顺序的,例如执行完 client-0 的队列中的 command-0 后,接下去是执行哪个队列中的第一个指令是无法确定的,但是肯定不会同时执行两个指令。
- redis 同样也会为每个客户端关联一个响应队列,通过响应队列来顺序地将指令的返回结果回复给客户端。
- 同样,一个响应队列中的消息可以顺序的回复给客户端,多个响应队列之间是无法保证顺序的。
- 所有的客户端的队列中的指令或者响应,redis 每次都只能处理一个,同一时间绝对不会处理超过一个指令或者响应。
2. 为什么redis使用单线程模型还能保证高性能?
(1) 纯内存访问
redis 将所有数据放在内存中,内存的响应时长大约为 100 纳秒,这是 redis 的 QPS 过万的重要基础。
(2) 非阻塞式IO
- 什么是阻塞式 IO
当我们调用 Scoket 的读写方法,默认它们是阻塞的。
read() 方法要传递进去一个参数 n,表示读取这么多字节后再返回,如果没有读够 n 字节线程就会阻塞,直到新的数据到来或者连接关闭了, read 方法才可以返回,线程才能继续处理。
write() 方法会首先把数据写到系统内核为 Scoket 分配的写缓冲区中,当写缓存区满溢,即写缓存区中的数据还没有写入到磁盘,就有新的数据要写道写缓存区时,write() 方法就会阻塞,直到写缓存区中有空闲空间。
- 什么是非阻塞式 IO
非阻塞 IO 在 Scoket 对象上提供了一个选项Non_Blocking ,当这个选项打开时,读写方法不会阻塞,而是能读多少读多少,能写多少写多少。
能读多少取决于内核为 Scoket 分配的读缓冲区的大小,能写多少取决于内核为 Scoket 分配的写缓冲区的剩余空间大小。读方法和写方法都会通过返回值来告知程序实际读写了多少字节数据。
有了非阻塞 IO 意味着线程在读写 IO 时可以不必再阻塞了,读写可以瞬间完成然后线程可以继续干别的事了。
(3) IO多路复用
非阻塞 IO 有个问题,那就是单个线程要处理多个读写请求,处理某个客户端的的读数据的请求,结果读了一部分就返回了,线程如何知道什么时候才应该继续读数据。处理写请求的时候,如果缓冲区满了,写不完,剩下的数据何时才应该继续写?在什么时候处理什么请求?redis 单线程处理多个IO请求时就用到了IO多路复用技术。
简单的理解下 IO 多路复用技术,假设每个客户端的 IO 请求是一条电路,redis 是一个开关,如下图所示:
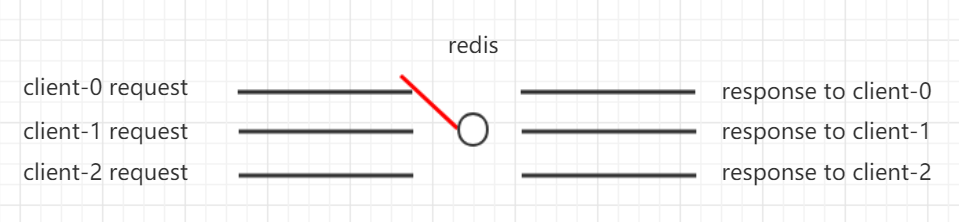
在上图中,redis 需要处理 3 个 IO 请求,同时把 3 个请求的结果返回给客户端,所以总共需要处理 6 个 IO 事件,由于 redis 是单线程模型,同一时间只能处理一个 IO 事件,于是 redis 需要在合适的时间暂停对某个 IO 事件的处理,转而去处理另一个 IO 事件,这样 redis 就好比一个开关,当开关拨到哪个 IO 事件这个电路上,就处理哪个 IO 事件,其他 IO 事件就暂停处理了。这就是IO多路复用技术。
以上是大致的理解下 IO 多路复用技术,在系统底层,IO 多路复用有 3 种实现机制:
- select
- poll
- epoll
这些实现机制的底层我不清楚,看过一些博客(细节也没看懂),总结一下就是:
epoll 是目前最新的也是最先进的 IO 多路复用的实现解决了select 和 poll 的很多问题。而 redis 就是使用的基于 epoll 的 IO 多路复用技术。
对这 3 种实现机制感兴趣的话,可以去看看大神的博客,本人在这里就不再胡说了。
(4) 单线程避免了线程切换和竞态产生的消耗。
单线程能带来几个好处:
- 第一,单线程可以简化数据结构和算法的实现。并发数据结构实现不但困难而且开发测试比较麻
- 第二,单线程避免了线程切换和竞态产生的消耗,对于服务端开发来说,锁和线程切换通常是性能杀手。
- 单线程的问题:对于每个命令的执行时间是有要求的。如果 某个命令执行过长,会造成其他命令的阻塞,所以 redis 适用于那些需要快速执行的场景。
原文: https://cloud.tencent.com/developer/article/1403767
