异常检测问题
此系列笔记来源于
Coursera上吴恩达老师的机器学习课程
异常检测问题
问题动机
有时我们需要对数据的异常检测,如生产线上某个产品是否合格,网站内某个用户是否异常……
步骤:
1、根据数据的特征值\(x^{(i)}\),我们进行建模,得到\(p(x)\)
2、设定一个阈值\(\epsilon\),如果 \(p(x) < \epsilon\) 则判定该数据不正常,否则正常
高斯分布(正态分布)
随机变量 \(X\) 服从一个位置参数 \(\mu\) 和 尺度参数,且其概率密度函数为
\(f(x) = \frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(x-\mu)^2}{2\sigma^2})\)
则 \(X\) 服从的分布是正态分布,记作$ X \sim N(\mu,;\sigma^2)$
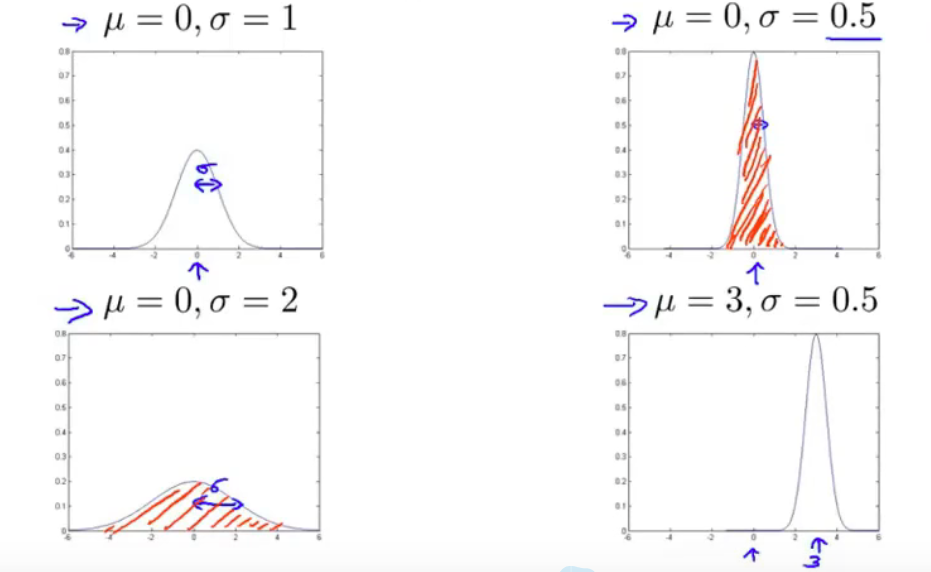
\(\mu\) 是正态分布的中心,当 \(\sigma\) 越小,则函数更窄更高,反之更宽更矮
\(\sigma^2\) 一般表示大部分数据集中区域的宽度
高斯概率密度函数的积分一定为 1
参数估计

对于已给数据集,我们如何估计其高斯概率密度函数:
\(\mu=\frac{1}{m}\sum^m_{i=1}x^{(i)},\;\sigma^2=\frac{1}{m}\sum_{i = 1}^m(x^{(i)}-\mu)^2\)
算法过程
1、数据集\(x^{(i)}\)
2、 计算参数
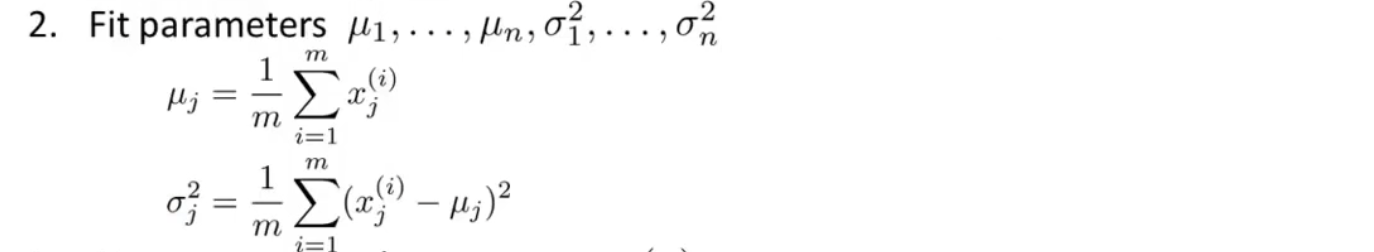
3、对于新样本,计算\(p(x)\)
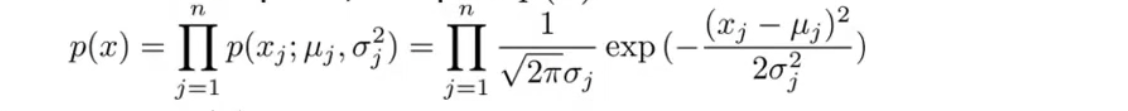
如果 \(p(x) < \epsilon\),则异常
评估异常检测系统
当我们开发一个异常检测系统时,我们会先从带标记(异常或正常)的数据着手,从中选择一部分正常数据用于构建训练集,然后用剩下的混合数据构成 cv集 和 test集
例如:我们有 10000 台正常引擎的数据,有 20 台异常引擎的数据。 我们这样分配数据:
- 6000 台正常引擎的数据作为训练集
- 2000 台正常引擎和 10 台异常引擎的数据作为交叉检验集
- 2000 台正常引擎和 10 台异常引擎的数据作为测试集
评估步骤
1、根据训练集,我们构建 \(p(x)\)
2、对cv集,我们尝试不同的 \(\epsilon\)值作为阈值,并预测数据是否异常,同时计算数据的 recall率和 precision率,根据F_1值来选择最好的\(\epsilon\)
3、选择好\(\epsilon\)后,针对test集进行预测,计算异常检验系统的recall率和 precision率和 F_1值
异常检测 vs 监督学习
| 异常检测 | 监督学习 |
|---|---|
| 非常少量的正向类(异常数据 y = 1), 大量的负向类(y = 0) | 同时有大量的正向类和负向类 |
| 许多不同种类的异常,且根据非常少量的正向类数据来训练算法。 | 有足够多的正向类实例,足够用于训练算法。 |
| 未来遇到的异常可能与已掌握的异常、非常的不同。 | 未来遇到的正向类实例可能与训练集中的非常近似。 |
| 例如: 1. 欺诈行为检测 2. 生产(例如飞机引擎) 3. 检测数据中心的计算机运行状况 | 例如: 1. 邮件过滤器 2. 天气预报 3. 肿瘤分类 |
选择合适的特征
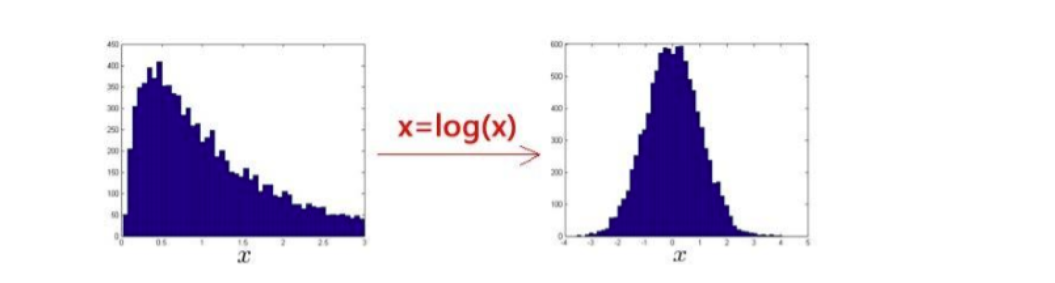
一般我们选择的特征需要是符合高斯分布的,对于数据的分布不是高斯分布,一般异常检测算法也能正常运行,但最好还是转化为高斯分布,例如对数据取对数等。
有一个常见的问题就是一些异常数据也有可能拥有较高的\(p(x)\),从而被认为是正常的。此时我们可以通过误差分析的步骤(与之前类似)先训练一个算法,然后在cv集上运行算法,接着找出预测错误的数据,最后看看能不能增加一些新的特征来解决这一问题,更好的进行异常检测
多元高斯分布
有时候特征的值域范围可能比较宽,此时一般的高斯分布模型有时并不能很好地识别异常数据。其原因在于,一般的高斯分布模型尝试的是去同时抓住两个特征的偏差,因此其会创造出一个比较大的判定边界。
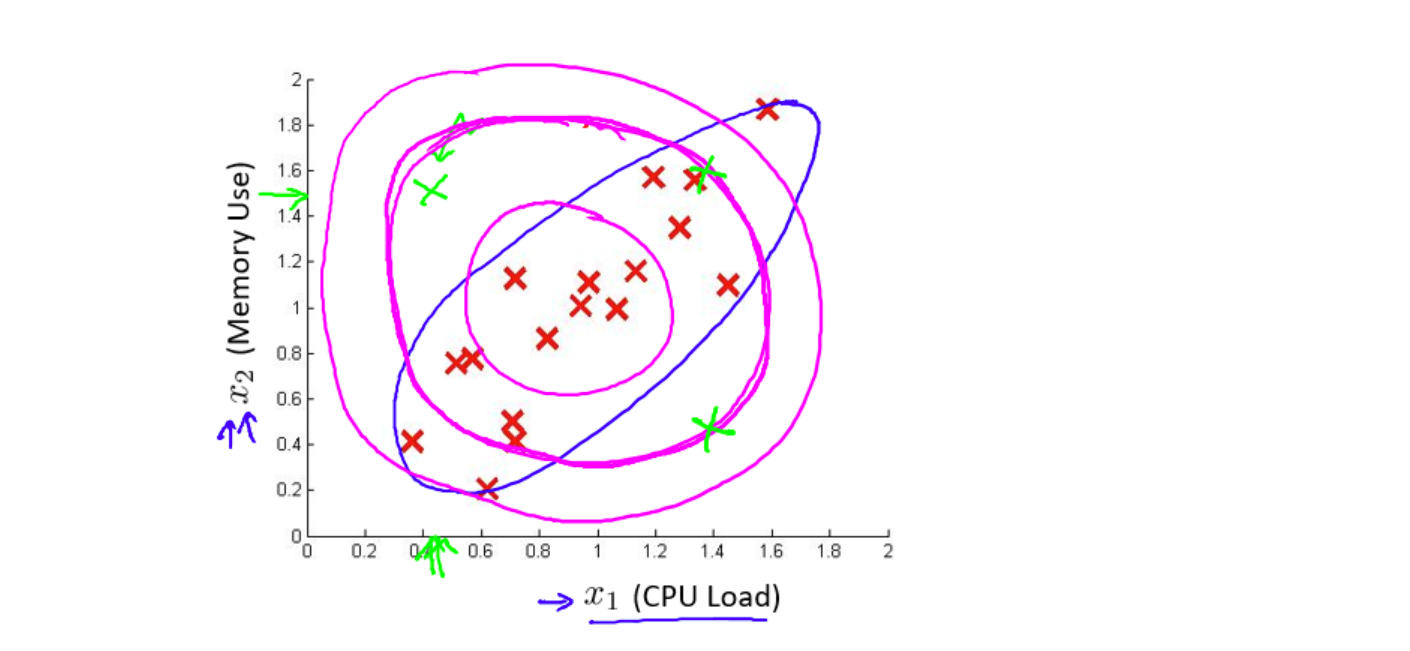
如图中的绿色点很可能是异常值,但其却在一般高斯分布模型获得的洋红色边界线中。而多元高斯分布将可以创造图中如蓝色曲线所示的判定边界
在多元高斯分布模型中,我们并不需要计算每个特征对应的\(p(x)\),而是先计算所有特征的平均值,然后再计算协方差矩阵
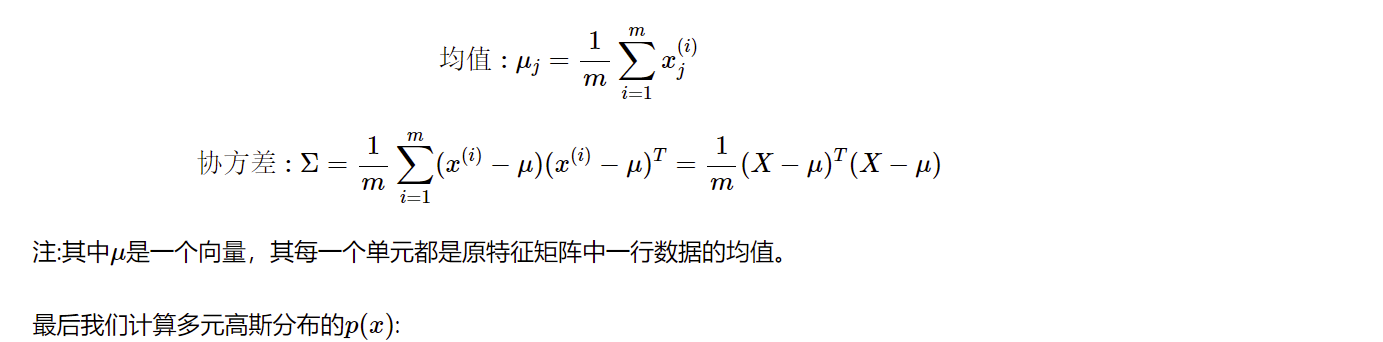
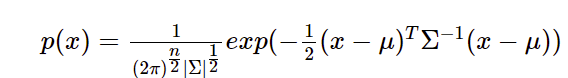
matlab 和 octave中 用 det(sigma)计算协方差矩阵
均值和协方差矩阵对模型的影响
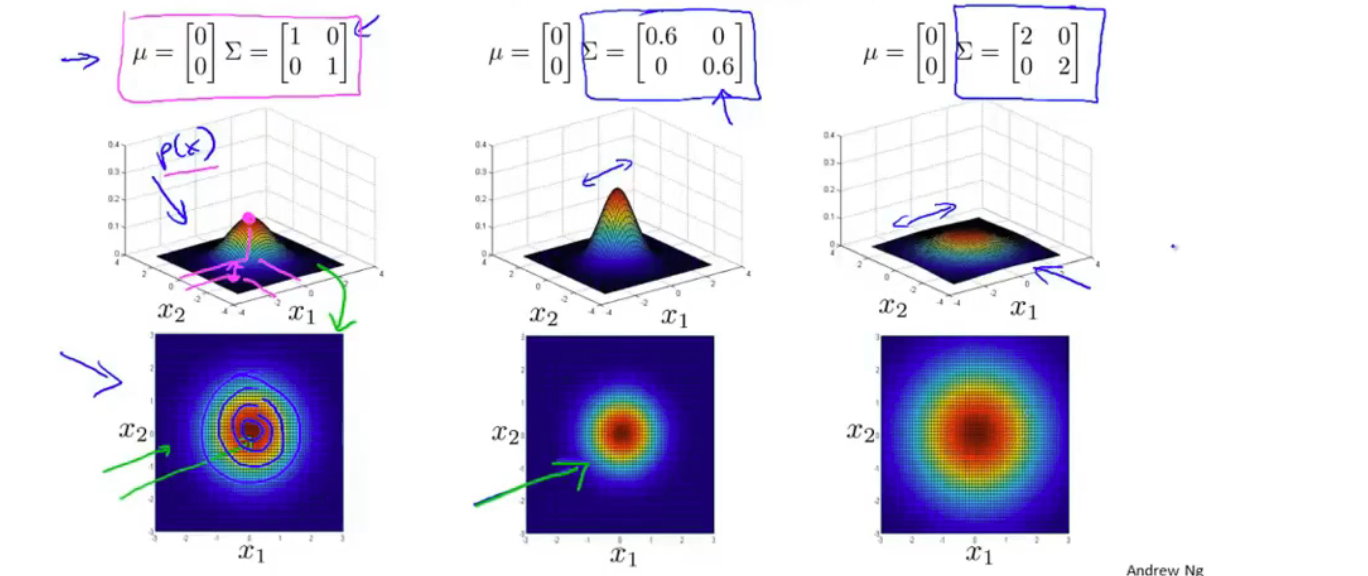
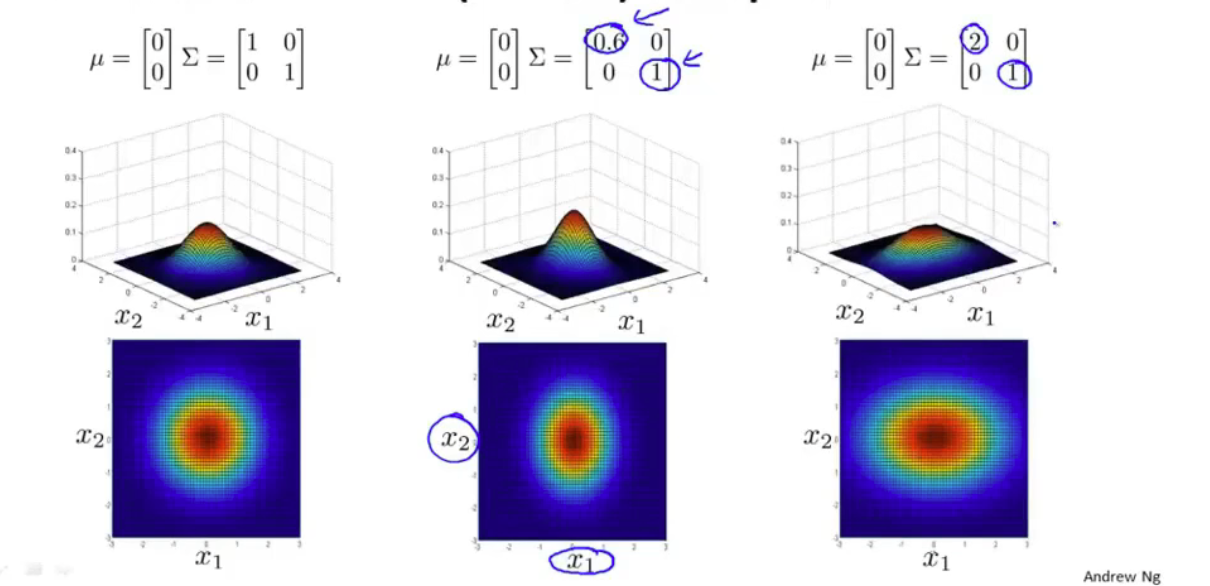
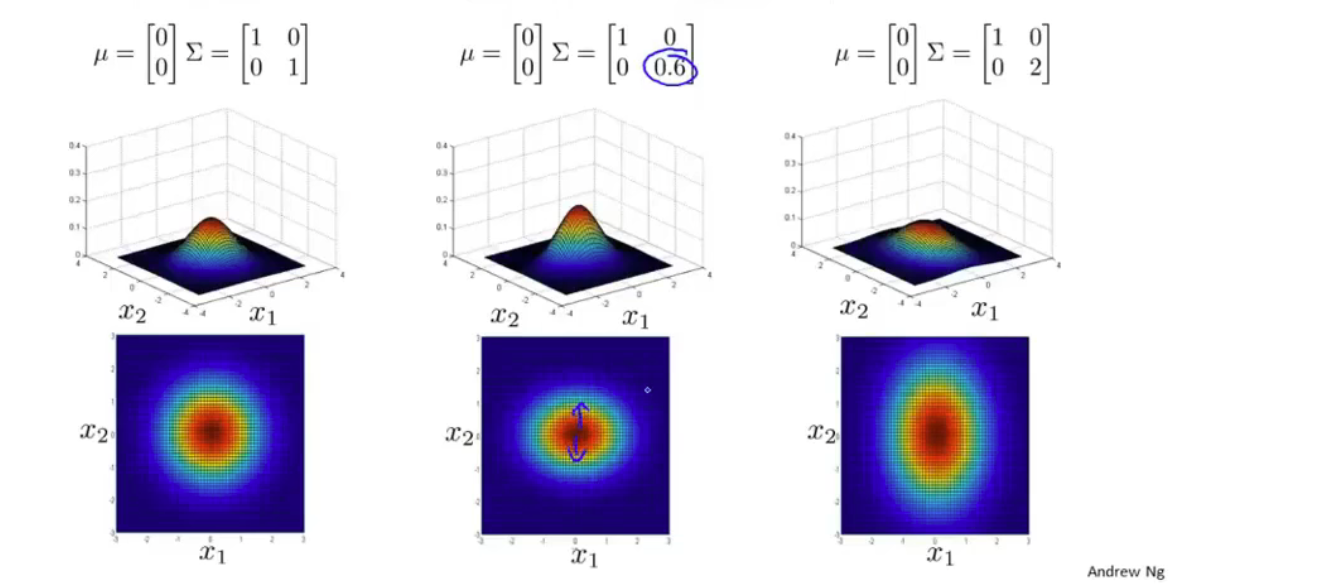
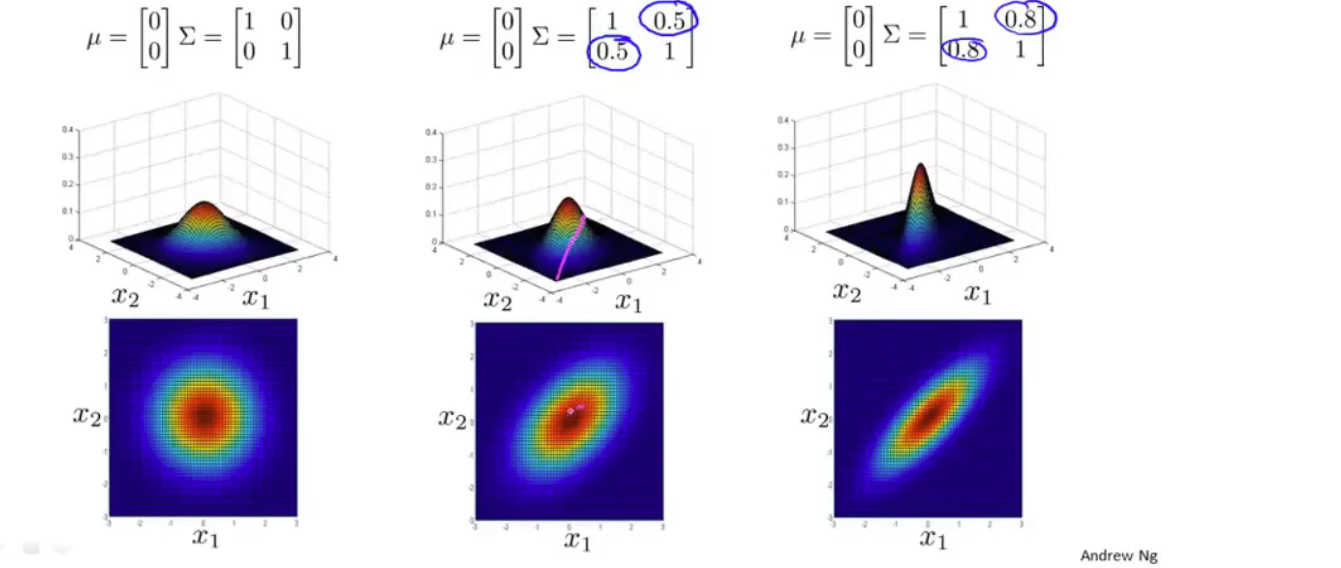
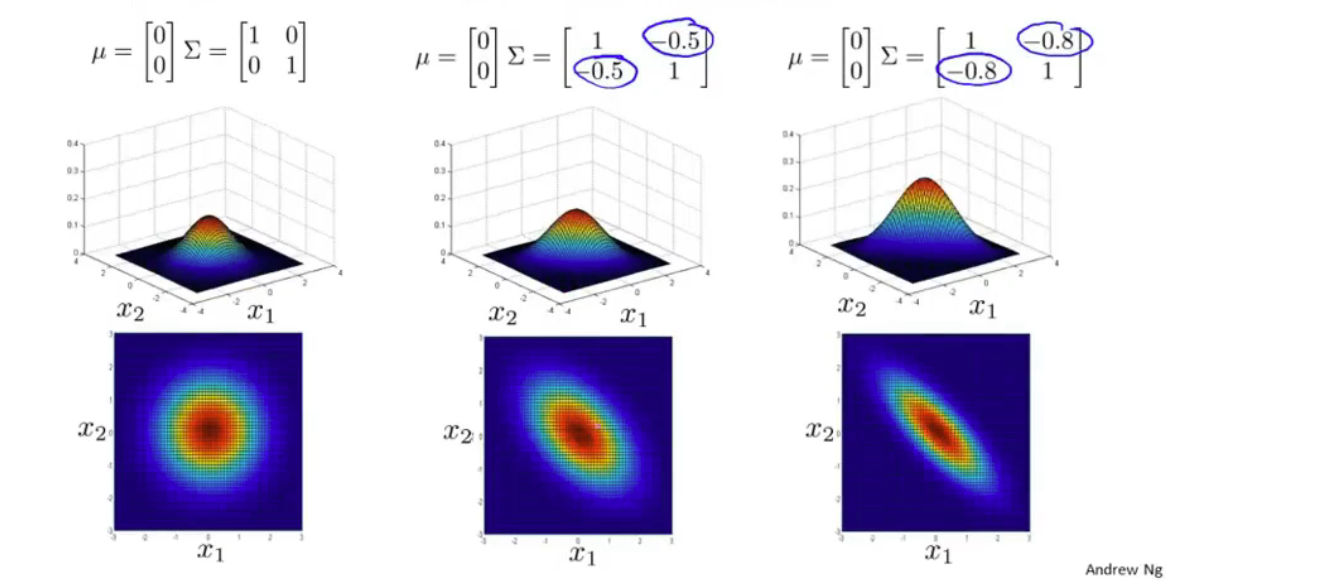
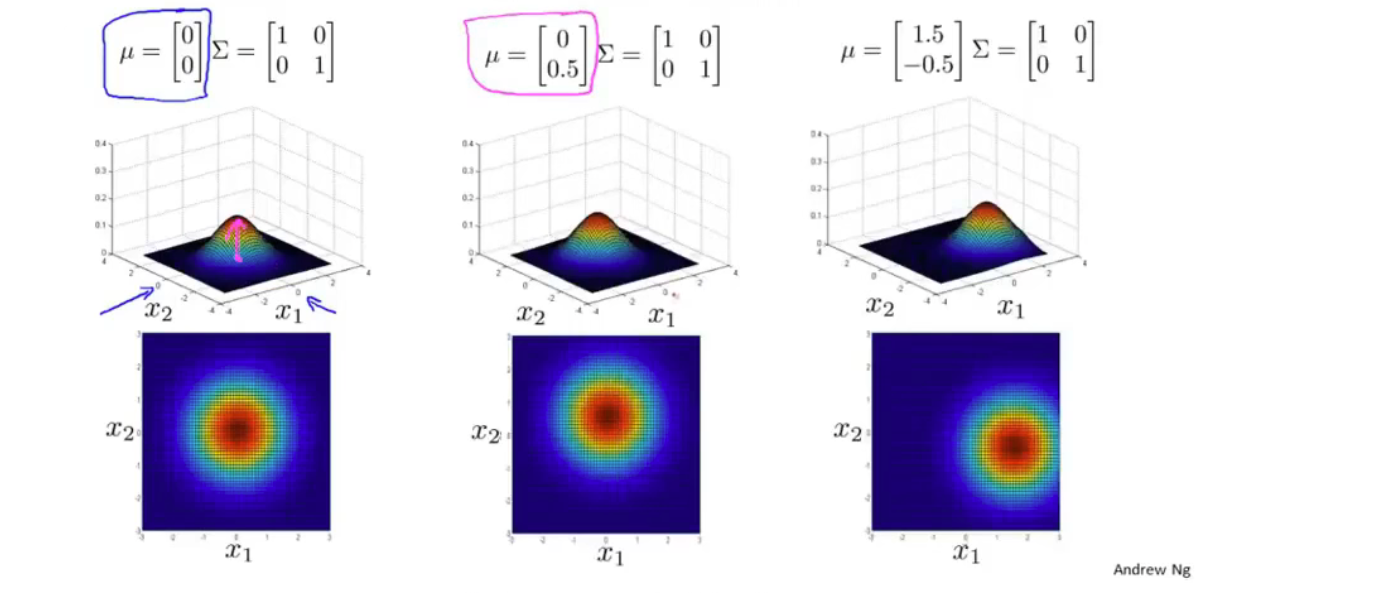
原理是通过协方差矩阵,令不同特征拥有不同的偏差,和改变特征之间的相关性
步骤:
1、计算 \(\mu\) 和 \(\sum\)
2、对与一个新的样本 x,计算 \(p(x)\)
3、判定 x 是否异常

原高斯分布模型 vs 多原高斯分布模型
原高斯分布模型是多原高斯分布模型的一个子集,只要当协方差矩阵只在主对角线上有非零值时即可。
| 原高斯分布模型 | 多元高斯分布模型 |
|---|---|
| 不能捕捉特征之间的相关性,但可以通过手动组合特征来解决 | 自动捕捉特征之间的相关性 |
| 计算代价低,能适应大规模的特征(large n) | 计算代价较高,训练集较小时也同样适用 |
| 必须要有 m>n,不然的话协方差矩阵不可逆的,通常需要 m>10n。另外特征冗余也会导致协方差矩阵不可逆,即线性相关的特征 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号