逻辑回归问题
此系列笔记来源于
Coursera上吴恩达老师的机器学习课程
逻辑回归问题
逻辑回归问题由于历史原因,是属于分类问题的一种
下面都以二元分类问题为例
假设函数
在线性回归问题中,我们设定假设函数为
但在逻辑回归问 题中,如果,那么显然是不合理的。为了能有利于分类,我们便希望。
因此我们设
我们称为逻辑函数 Logistic Function 或者 Sigmoid Function
函数图像如下:
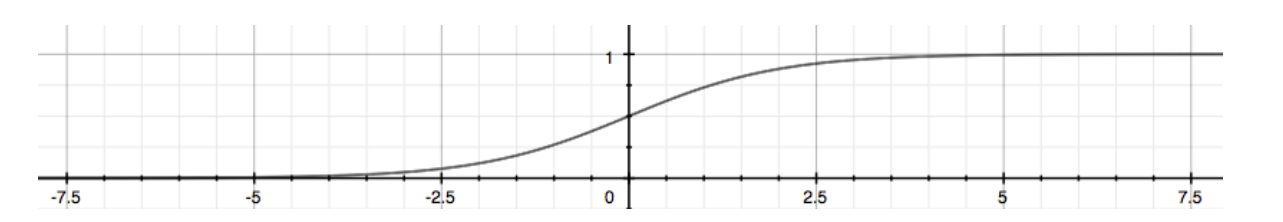
这样对任意我们都可以得到
而在这里的告诉了我们输出值为1的可能性,同时输出值为0的可能性也就是
决策边界
当 时,我们预测 0,当 时,我们预测 1。
我们很容易发现当 时,我们会得到 0,而 时,我们会得到 1
根据训练集,我们拟合出 后便能得到 的表达式。从而我们便能根据 来画出图像,从而得到这一条决策边界,帮助我们划分出两块区域。
例:
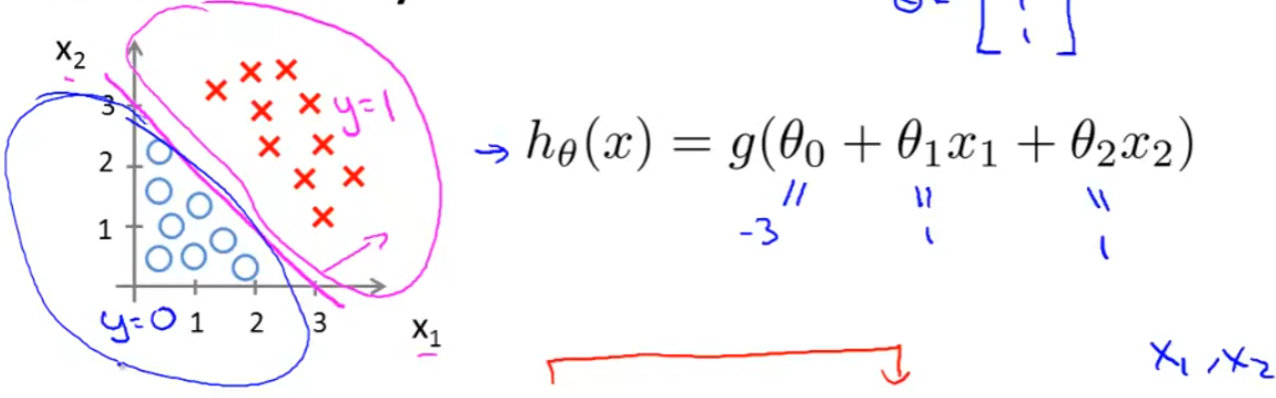

代价函数
为了能使用梯度下降算法,我们希望代价函数是凸函数(convex),因此我们令
函数图像如下:
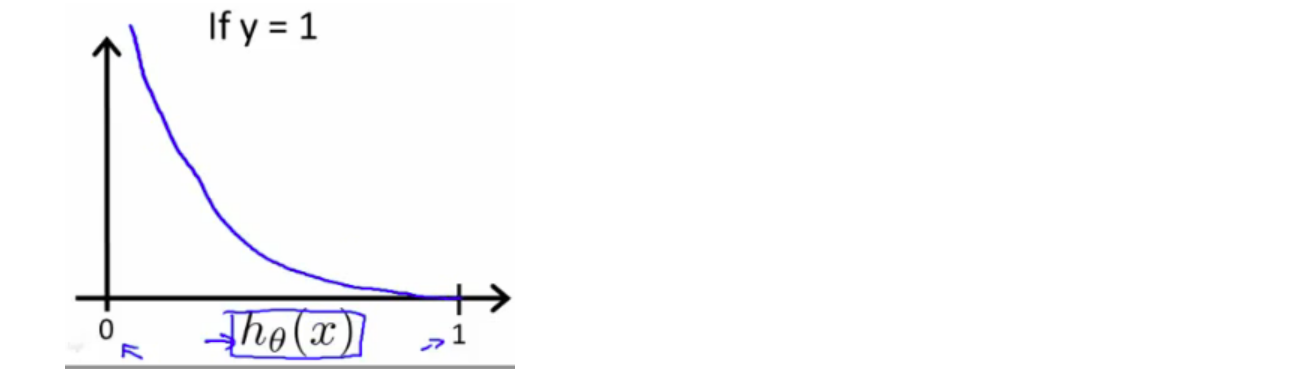
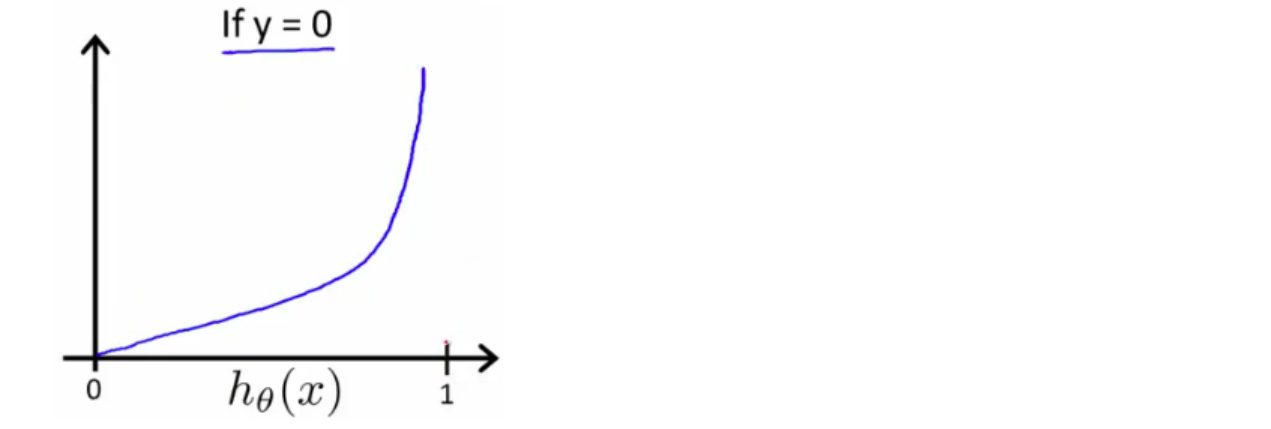
我们可以知道当 时,
而当 时,则
可以理解为学习了一个错误,花了极大代价。
如此一来,我们便能令代价函数为凸函数,为了逻辑回归。
最终我们还可以简化 Cost函数,不用分类,即:
代价函数则为:
向量化(vectorized) 后则为:
梯度下降算法
运用到梯度算法中,公式并没有改变,区别仅在于 函数的改变。
向量化后:
Advanced Optimization
"Conjugate gradient", "BFGS", and "L-BFGS"比起梯度下降更加高效,但更加复杂。我们可以通过调用相关被封装好的库函数,来代替梯度下降。
首先我们需要写一个函数,根据 得到 和
f unction [jVal, gradient] = costFunction(theta)
jVal = [...code to compute J(theta)...];
gradient = [...code to compute derivative of J(theta)...];
end
之后便可以通过调用 “fminunc()”函数 和 “optimset()”函数来进行计算
options = optimset('GradObj', 'on', 'MaxIter', 100); %GradObj 'on'意味着要给该算法提供一个梯度,MaxIter 100意味着最多迭代一百次
initialTheta = zeros(2,1);
[optTheta, functionVal, exitFlag] = fminunc(@costFunction, initialTheta, options);
多元分类
当 y 的值拓宽到 1 - n 时,我们可以将问题转化为二元分类问题
我们设定 n 个分类器,每个分类器将第 i 个类和其他类分为两类。
即:
此时我们的 prediction值即为
过度拟合 Overfitting
过度拟合指的是,根据训练集,我们设定的假设函数过度与训练集拟合,这可能会对接下来的预测产生不好的影响。
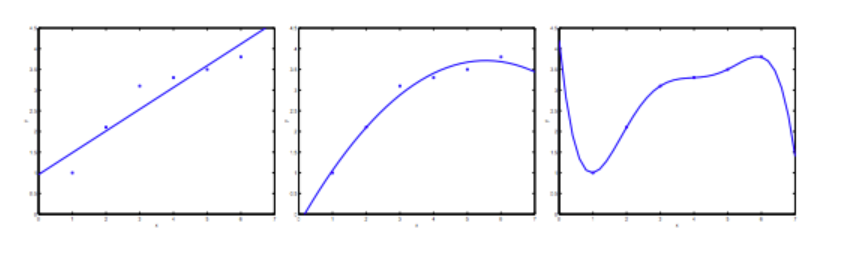
在线性回归问题中,当我们设定的特征函数不够拟合训练集,称为 ”欠拟合“(underfitting) 或者 “高偏差“(high bias),相反过度拟合训练集时,称为”过度拟合“(overfitting) 或者 “高方差”(high variance)
而这两种情况都无法很好的预测数据的趋势。
如何解决这两种情况:
1、减少特征数量
2、正则化 Regularization
正则化 Regularization
为了去减少特征值的影响力,而不是直接删除,我们可以通过加一些项来达到这一效果。
这样一来,如果原来假设函数是一个四次函数,且我们通过正则化去减少最高两项的系数 和 的值,从而使假设函数更加quadratic,那么便能得到一个更为简单的假设,更不易发生过度拟合。
同理,我们可以通过一个式子对所有 参数进行正则化:
$ min_\theta\frac{1}{2m}[\summ_{i=1}(h_\theta(x)-y{(i)})2+\lambda\sumn_{j=1}\theta_j2]$
称为正则化参数。正则化参数过大可能会导致欠拟合,
正则化后的线性回归
梯度下降:
在这里,便是正则化的部分。
第二个式子进行变形后可以得到:
而第一项中的 始终小于1
正规方程

经过证明后,我们可以得到 是一定可逆的
正则化后的逻辑回归
代价函数
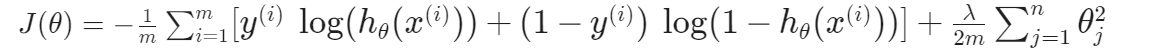
梯度计算
梯度下降


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY