
大数据概论
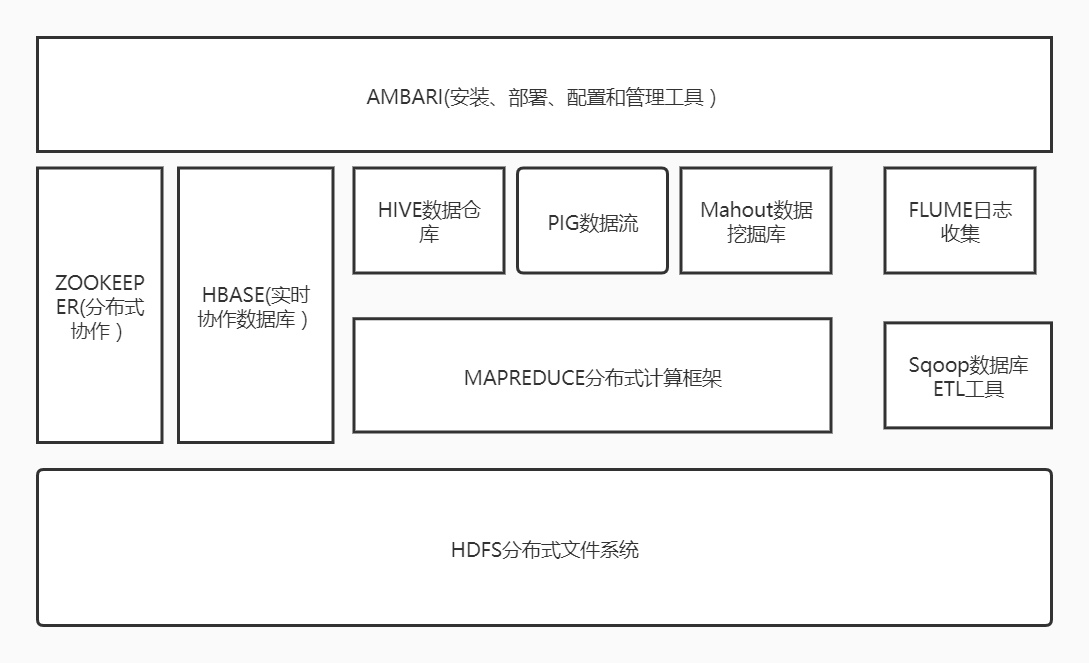
一.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
1、HDFS(hadoop分布式文件系统)
是hadoop体系中数据存储管理的基础。他是一个高度容错的系统,能检测和应对硬件故障。
client:切分文件,访问HDFS,与namenode交互,获取文件位置信息,与DataNode交互,读取和写入数据。
namenode:master节点,在hadoop1.x中只有一个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户 端请求。
DataNode:slave节点,存储实际的数据,汇报存储信息给namenode。
secondary namenode:辅助namenode,分担其工作量:定期合并fsimage和fsedits,推送给namenode;紧急情况下和辅助恢复namenode,但其并非namenode的热备。
2、mapreduce(分布式计算框架)
mapreduce是一种计算模型,用于处理大数据量的计算。其中map对应数据集上的独立元素进行指定的操作,生成键-值对形式中间,reduce则对中间结果中相同的键的所有值进行规约,以得到最终结果。
jobtracker:master节点,只有一个,管理所有作业,任务/作业的监控,错误处理等,将任务分解成一系列任务,并分派给tasktracker。
tacktracker:slave节点,运行 map task和reducetask;并与jobtracker交互,汇报任务状态。
map task:解析每条数据记录,传递给用户编写的map()并执行,将输出结果写入到本地磁盘(如果为map—only作业,则直接写入HDFS)。
reduce task:从map 它深刻地执行结果中,远程读取输入数据,对数据进行排序,将数据分组传递给用户编写的reduce函数执行。
3、 hive(基于hadoop的数据仓库)
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。
hive定于了一种类似sql的查询语言(hql)将sql转化为mapreduce任务在hadoop上执行。
4、hbase(分布式列存数据库)
hbase是一个针对结构化数据的可伸缩,高可靠,高性能,分布式和面向列的动态模式数据库。和传统关系型数据库不同,hbase采用了bigtable的数据模型:增强了稀疏排序映射表(key/value)。其中,键由行关键字,列关键字和时间戳构成,hbase提供了对大规模数据的随机,实时读写访问,同时,hbase中保存的数据可以使用mapreduce来处理,它将数据存储和并行计算完美结合在一起。
5、zookeeper(分布式协作服务)
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
6、sqoop(数据同步工具)
sqoop是sql-to-hadoop的缩写,主要用于传统数据库和hadoop之间传输数据。
数据的导入和导出本质上是mapreduce程序,充分利用了MR的并行化和容错性。
7、pig(基于hadoop的数据流系统)
定义了一种数据流语言-pig latin,将脚本转换为mapreduce任务在hadoop上执行。
通常用于离线分析。
8、mahout(数据挖掘算法库)
mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。mahout现在已经包含了聚类,分类,推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法是,mahout还包含了数据的输入/输出工具,与其他存储系统(如数据库,mongoDB或Cassandra)集成等数据挖掘支持架构。
9、flume(日志收集工具)
cloudera开源的日志收集系统,具有分布式,高可靠,高容错,易于定制和扩展的特点。他将数据从产生,传输,处理并写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在flume中定制数据发送方,从而支持收集各种不同协议数据。
10、资源管理器(YARN和mesos)
随着互联网的高速发展,基于数据 密集型应用 的计算框架不断出现,从支持离线处理的mapreduce,到支持在线处理的storm,从迭代式计算框架到 流式处理框架s4,...,在大部分互联网公司中,这几种框架可能都会采用,比如对于搜索引擎公司,可能的技术方法如下:网页建索引采用mapreduce框架,自然语言处理/数据挖掘采用spark,对性能要求到的数据挖掘算法用mpi等。公司一般将所有的这些框架部署到一个公共的集群中,让它们共享集群的资源,并对资源进行统一使用,这样便诞生了资源统一管理与调度平台,典型的代表是mesos和yarn。
二:1.hadoop优点:
Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
可靠性: Hadoop将数据存储在多个备份,Hadoop提供高吞吐量来访问应用程序的数据。
高扩展性: Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
高效性: Hadoop以并行的方式工作,通过并行处理加快处理速度。
高容错性: Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
低成本: Hadoop能够部署在低廉的(low-cost)硬件上。
2.spark优点:
计算速度快: 因为spark从磁盘中读取数据,把中间数据放到内存中,,完成所有必须的分析处理,将结果写回集群,所以spark更快。
Spark 提供了大量的库: 包括Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX。
支持多种资源管理器: Spark 支持 Hadoop YARN,及其自带的独立集群管理器
操作简单: 高级 API 剥离了对集群本身的关注,Spark 应用开发者可以专注于应用所要做的计算本身。
联系:Hadoop提供分布式数据存储功能HDFS,还提供了用于数据处理的MapReduce。 MapReduce是可以不依靠spark数据的处理的。当然spark也可以不依靠HDFS进行运作,它可以依靠其它的分布式文件系统。但是两者完全可以结合在一起,hadoop提供分布式 集群和分布式 文件系统,spark可以依附在hadoop的HDFS代替MapReduce弥补MapReduce计算能力不足的问题。
三:一方面,由于Hadoop生态系统中的一些组件所实现的功能,目前还是无法由Spark取代的,比如,Storm可以实现毫秒级响应的流计算,但是,Spark则无法做到毫秒级响应。另一方面,企业中已经有许多现有的应用,都是基于现有的Hadoop组件开发的,完全转移到Spark上需要一定的成本。因此,在许多企业实际应用中,Hadoop和Spark的统一部署是一种比较现实合理的选择。由于Hadoop MapReduce、HBase、Storm和Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署。
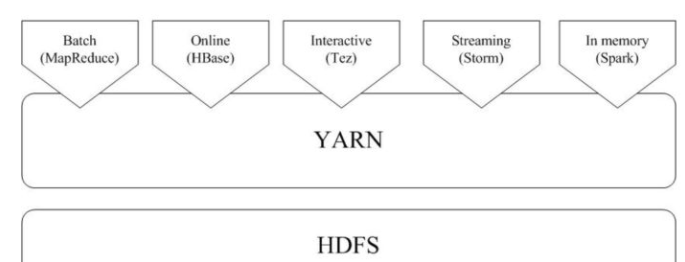
对比Hadoop与Spark的优缺点。
1. Spark 概述
1.1. 什么是 Spark(官网:http://spark.apache.org)
spark 中文官网:http://spark.apachecn.org
Spark 是一种快速、通用、可扩展的大数据分析引擎,2009 年诞生于加州大学伯克利分校AMPLab,2010 年开源,2013 年 6 月成为 Apache 孵化项目,2014 年 2 月成为 Apache
顶级项目。目前,Spark 生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib 等子项目,Spark 是基于内存计算的大数
据并行计算框架。Spark 基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将 Spark 部署在大量廉价硬件之上,形成集群
1.2. Spark 和 Hadoop 的比较
mapreduce 读 – 处理 - 写磁盘 -- 读 - 处理 - 写
spark 读 - 处理 - 处理 --(需要的时候)写磁盘 - 写
Spark 是在借鉴了 MapReduce 之上发展而来的,继承了其分布式并行计算的优点并改进了 MapReduce 明显的缺陷,(spark 与 hadoop 的差异)具体如下:
首先,Spark 把中间数据放到内存中,迭代运算效率高。MapReduce 中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而 Spark 支持 DAG 图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。(延迟加载)
其次,Spark 容错性高。Spark 引进了弹性分布式数据集 RDD (Resilient DistributedDataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即允许基于数据衍生过程)对它们进行重建。另外在RDD 计算时可以通过 CheckPoint 来实现容错。
最后,Spark 更加通用。mapreduce 只提供了 Map 和 Reduce 两种操作,Spark 提供的数据集操作类型有很多,大致分为:Transformations 和 Actions 两大类。Transformations包括 Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort 等多种操作类型,同时还提供 Count, Actions 包括 Collect、Reduce、Lookup 和 Save 等操作
如何实现Hadoop与Spark的统一部署?
一、hadoop部署
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。[1] Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
1、 实现root账户可登录
Root登陆:
vi /etc/lightdm/lightdm.conf
更改为:
[SeatDefaults]
greeter-session=unity-greeter
user-session=ubuntu
greeter-show-manual-login=true
allow-guest=false
出现tyy –s loading ……… .root/.profile
在刚修改完root权限自动登录后,发现开机出现以下提示:
Error found when loading /root/.profile
stdin:is not a tty
…………
解决方法:在终端中用命令gedit /root/.profile,打开文件后找到“mesg n”,
将其更改为“tty -s && mesg n”
2、 ssh 各节点之间的登录
sudo apt-get install vim //安装vim
sudo apt-get install openssh-server // 安装ssh server
cd ~
mkdir .ssh # 可能该文件已存在,不影响
cd ~/.ssh/
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat id_rsa.pub >> authorized_keys # 将本机加入授权
scp ~/.ssh/id_rsa.pub root@Slave1:/home # 将公钥发送给Slave1
cd ~
mkdir .ssh
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys // 将master 节点的公钥加入到Slave1的授权文件中,Master 即可无需密钥访问到Slave1,同理将slave1的公钥放入到master , slave1 也可以直接访问master
3、 将hadoop目录放在合适的目录中
修改core-site.xml文件
fs.defaultFS
hdfs://Master:9000
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
修改hdfs-site.xml文件
dfs.replication
1
dfs.namenode.secondary.http-address
Master:50090
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/hadoop/tmp/dfs/data</value>
</property>
1
2
3
4
5
6
7
8
9
修改mapred-site.xml文件 两种模式未都测试过
参考: http://blog.csdn.net/yuzhiyuxia/article/details/20001447
按我前面的配置会卡在mapreduce.Job: Running job
在etc/hadoop/mapred-site.xml中,如果配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
1
2
3
4
则使用yarn来进行计算,那么必须启动nodemanager,
如果不使用yarn,进行mapreduce.job.tracker配置,也可以用MRv2来执行job,这样就不需要启动nodemanager:
保留下面
mapreduce.job.tracker
hdfs://master:端口
true
4、 配置yarn 如果使用yarn ,需要配置yarn-site.xml

