预训练语言模型公平性-公平性度量、去偏方法
一、内在偏见与外在偏见
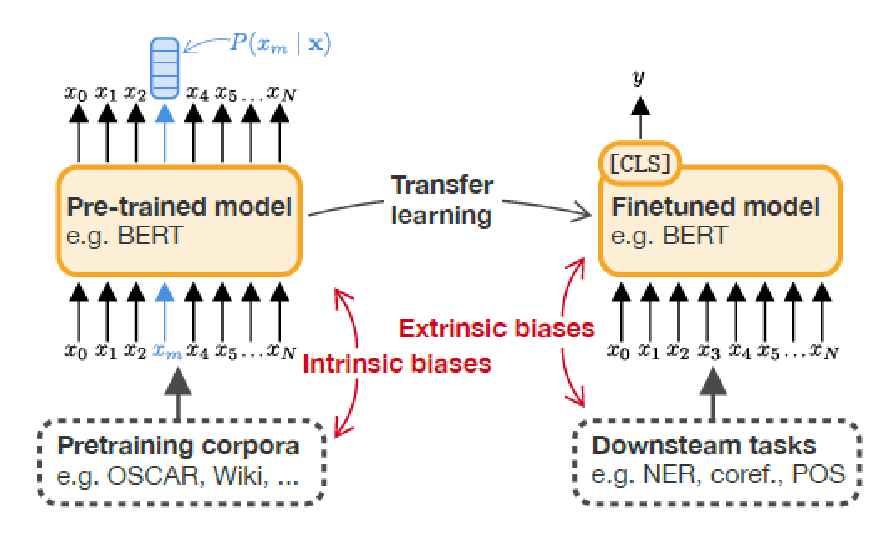
1、内在偏见:训练前数据集中存在的刻板印象;
2、外在偏见:用来衡量偏差如何在下游任务中传播。通常包括微调,然后评估其关于性别和种族等敏感属性的表现;
3、许多NLP应用程序对现有的语言模型进行了微调,这些模型将外在偏见和内在偏见交织在一起。
二、10种度量方法
2.1 内在度量

2.2 外在度量

三、5种去偏方法

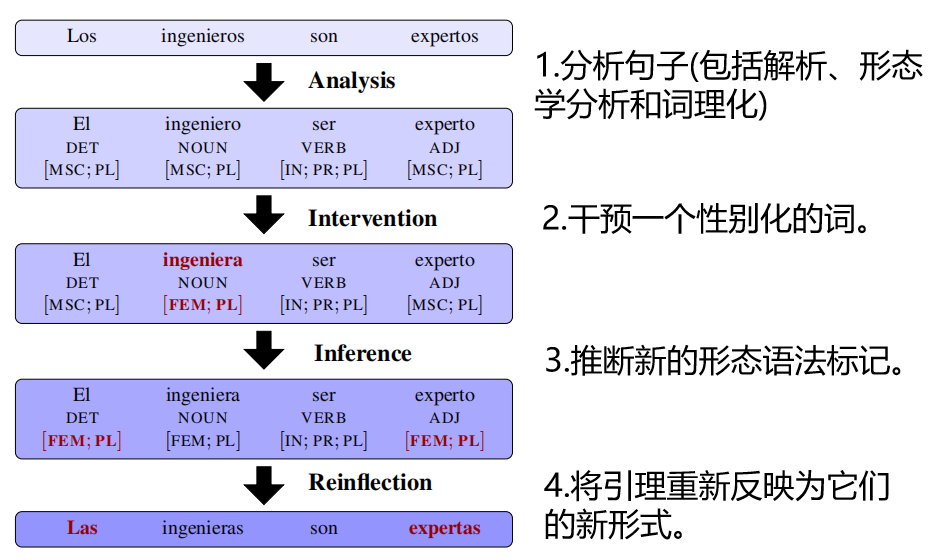
3.1 CDA-数据增强
通过反事实数据增强(CDA)[1,2]来减轻偏见:这是一种通过因果干预来增强语料库的通用方法,打破了性别和中性词汇之间的关联。使用了一个双向的性别词对词典,用双元组替换原始语料库中出现的每一个性别词(除了一些例外情况)。

3.2 INLP-基于投影
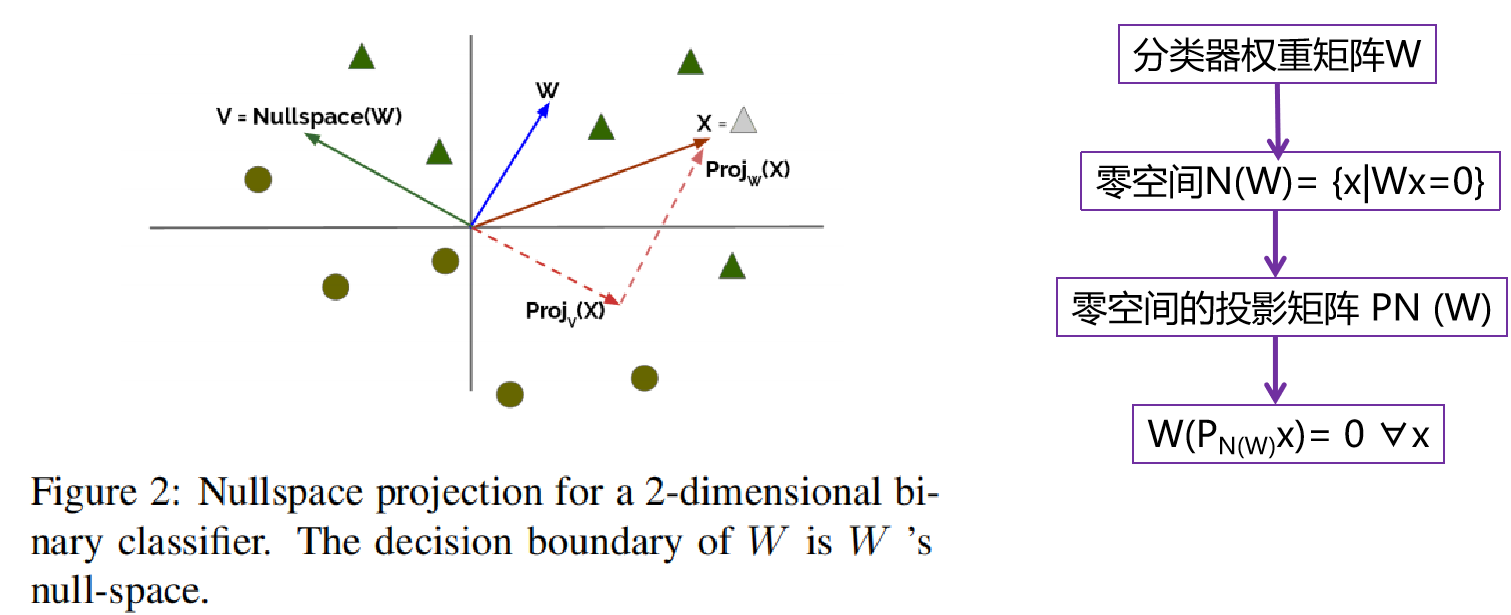
- INLP [3]去偏原理:选择性地从表示中删除特定类型的信息。消除属性和向量表示之间的线性依赖关系。训练线性分类器,让分类器无法识别目标属性。
- 迭代线性分类器,由矩阵W∈Rk×d参数化,它有一定的精度预测属性z。通过零空间投影来构造矩阵P,使W(Px)=0,使W在数据集X上无用。
- 分类器通常仍然可以训练恢复z投影x以上的机会精度,通常有多个线性方向(超平面),可以部分捕获多维空间的关系。通过迭代过程来解决。多个分类器产生多个零空间,产生多个零空间投影。最终相当于多个零空间交集的投影。
![]()
3.3 Sentence-Debias-基于投影
Sentence-debias[4]去偏分为4步:
1、定义具有偏见属性的词(来自5个数据集) ;
2、将这些词语境化为偏见属性句子,然后得到句子表示(考虑多个语料库中的模板) ;
3、估计句子表示偏差子空间;
4、通过移除在这个偏差子空间上的投影去偏。

3.4 Context-Debias-基于投影
- Context-Debias[5]一种微调方法,通过在中间(隐藏)层中的正交投影,消除预训练上下文嵌入中的词或句子级别的不同粒度或不同层(实验选用了第一、最后一、所有层)的偏见,保留了预先训练的上下文单词嵌入模型中的语义信息。
- 字符表示:
- 属性词Va和目标词Vt;
- Ω(w)为一个属性或一个目标词w提取的句子集;
- A和T为分别为包含所有属性和目标词的句子集;
- Ei(w, x; θe) 表示参数为θe的模型第i层,对句子x的token w的编码信息。
- A中去偏,T中保留语义信息
- Li :Vt的去偏词嵌入不能包含任何与a相关的信息,用a的非上下文嵌入和t的上下文嵌入内积计算损失;
- Lreg:测量了由θpre参数化的原始模型中第i层的单词w的上下文词嵌入与去偏模型之间的距离平方。
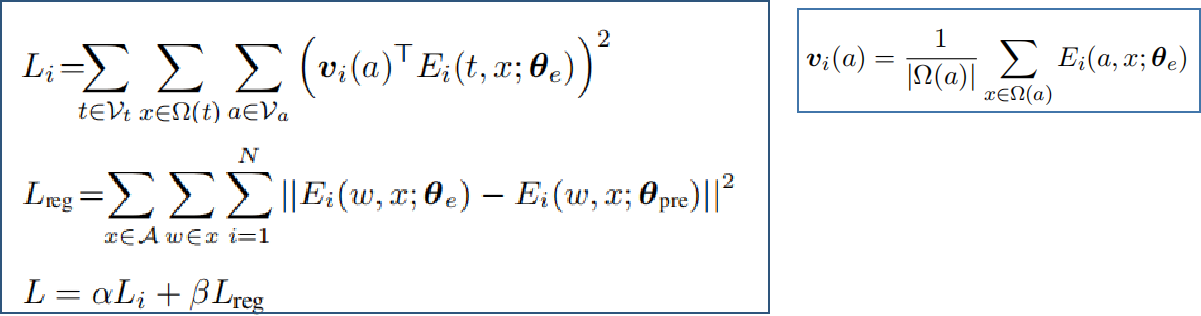
3.5 Auto-Debias-目标函数

- Auto-debias[6]去偏原理: he has a job as [MASK] 、she has a job as [MASK] ,预测MASK的概率分布是一致的。 微调目标:给定targert word(he、she)和 biased prompt(has a job as),最小化预测[MASK] token 分布之间的分歧。
- biased prompt:寻找在[MASK]位置生成target word时分歧最大。这里用JSD测量分布之间的一致性。
- 总结:先寻找让attribute word和targert word之间JSD最大的prompts,再用targert word预测next token 分布让JSD最小。
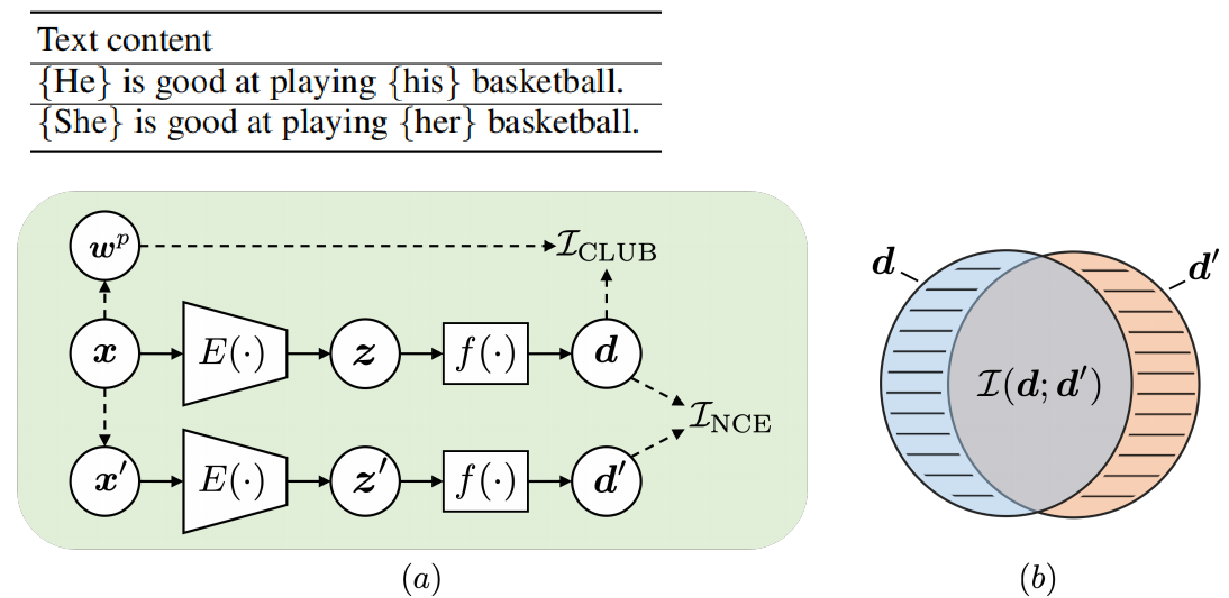
3.6 Fairfil-对比学习去偏-目标函数
Fairfil[7]去偏分为3步:
1、对于每个输入句子x,我们生成一个增广句子x’,它与x具有相同的语义,但潜在的偏差不同;
2、利用InfoNCE最大化原始嵌入z = f(x)和增广嵌入z’ = f(x’)之间的互信息;
3、一个去偏正则化器最小化d和x中敏感属性词之间的互信息。
3.7 Dropout
Dropout去偏[8]:BERT有两个可以配置的dropout参数,一个用于注意力权重(a),另一个用于隐藏激活(h),默认情况下都设置为0.10。通过在英语维基百科的随机样本上运行一个额外的预训练阶段(100k step;8x16 TPU上运行3.5小时),用public模型初始化(被训练了1M step)。得到a= .15和h = .20网络搜索最佳结果。
public ALBERT中dropout被设置为0,测试了重新引入dropout。重复上面的实验,但dropout值为0.01、0.05和0.10(每个<1h,16x16 TPU)。
3.8 Self-Debiasing
- Self-Debiasing[9]:只给定不期望行为的文本描述y,就可以降低模型产生问题文本的概率;
- pM(w|x):给定原始输入的下一个单词的分布;
- pM(w|sdb(x,y)):使用自去偏置输入获得的分布;
- 使用模板添加属性描述y会鼓励语言模型生成显示不希望的属性的文本,即pM(w|sdb(x,y))比pM(w|x)有更高的概率。

3.9 总结
1、CDA:通过交换一个数据集中的偏差属性词来重新平衡一个语料库,然后进行额外的预训练;
2、Dropout:增加注意权重和隐藏激活的dropout参数,并进行额外的预训练;
3、INLP:训练一个线性分类器来预测想要从表示中删除的受保护的属性来削弱模型的表示,通过将表示投影到学习分类器权重矩阵的零空间来去偏。
4、Self-Debias:一种后去偏技术,利用模型的内部知识来阻止它生成有偏见的文本,不会改变模型的内部表示或其参数;
5、SentenceDebias:基于投影,需要对特定类型的偏差估计一个线性子空间,从原始的句子表示中减去投影到估计的偏差子空间上的句子表示来去偏。
四、参考文献
- Lu K, Mardziel P, Wu F, et al. Gender bias in neural natural language processing[M]//Logic, Language, and Security. Springer, Cham, 2020: 189-202.
- Zmigrod R, Mielke S J, Wallach H, et al. Counterfactual data augmentation for mitigating gender stereotypes in languages with rich morphology[J]. arXiv preprint arXiv:1906.04571, 2019.
- Ravfogel S, Elazar Y, Gonen H, et al. Null it out: Guarding protected attributes by iterative nullspace projection[J]. arXiv preprint arXiv:2004.07667, 2020.
- Liang P P, Li I M, Zheng E, et al. Towards debiasing sentence representations[J]. arXiv preprint arXiv:2007.08100, 2020.
- Kaneko M, Bollegala D. Debiasing pre-trained contextualised embeddings[J]. arXiv preprint arXiv:2101.09523, 2021.
- Guo Y, Yang Y, Abbasi A. Auto-Debias: Debiasing Masked Language Models with Automated Biased Prompts[C]//Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022: 1012-1023.
- Cheng P, Hao W, Yuan S, et al. Fairfil: Contrastive neural debiasing method for pretrained text encoders[J]. arXiv preprint arXiv:2103.06413, 2021.
- Webster K, Wang X, Tenney I, et al. Measuring and reducing gendered correlations in pre-trained models[J]. arXiv preprint arXiv:2010.06032, 2020.
- Schick T, Udupa S, Schütze H. Self-diagnosis and self-debiasing: A proposal for reducing corpus-based bias in nlp[J]. Transactions of the Association for Computational Linguistics, 2021, 9: 1408-1424.
