Celery 任务路由的使用,在多任务时,实现分组管理任务
Celery 任务路由的使用,在多任务时,实现分组管理任务
Celery 任务路由的使用,本文参考了国外大佬的文章,并做了修改与补充,原文见这里,Bjoern Stiel
任务路由的主要作用:把任务分类,让他们在不同队列中运行,互不干扰,同时方便管理
本文介绍 3 种任务路由添加方式,如不分组,则全部任务都执行在 celery 默认队列中
代码
本文的代码 基于 FastAPi Celery RabbitMQ 与 Redis 的使用,并使用 Flower 监控 Celery 状态 这篇文章修改
第1种
使用指定格式的 字典对象来实现,其中的字典 key main.*,表示匹配所有 main.开头的任务,universities:*同理
修改文件 celery_utils.py
"""
@ File : celery_utils.py
@ Author : yqbao
@ Version : V1.0.0
@ Description : 配置并获取 celery 实例
"""
from celery import Celery
from celery.result import AsyncResult
def create_celery():
celery = Celery(__name__)
celery.conf.update(timezone="Asia/Shanghai") # 时区
celery.conf.update(enable_utc=False) # 关闭UTC时区。默认启动
# 任务路由,为任务分配不同的队列(可理解为分组)
# 方案1
# main.*,表示匹配所有 main.开头的任务,匹配支持正则表达式
# {'queue': 'celery'},中,celery 表示队列名称
celery.conf.update(task_routes={
'main.*': {'queue': 'celery'},
'universities:*': {'queue': 'universities'},
'university:*': {'queue': 'university'}
})
celery.conf.update(task_track_started=True) # 启动任务跟踪
celery.conf.update(task_serializer='pickle') # 任务序列化方式
celery.conf.update(result_serializer='pickle') # 结果序列化方式
celery.conf.update(accept_content=['pickle', 'json']) # 接受的类型
celery.conf.update(result_expires=200) # 结 果过期时间,200s
celery.conf.update(result_persistent=True)
celery.conf.update(worker_send_task_events=False)
celery.conf.update(worker_prefetch_multiplier=1)
celery.conf.update(broker_connection_retry_on_startup=True) # 启动时重试代理连接
return celery
def get_task_info(task_id):
"""返回给定task_id的任务信息"""
task_result = AsyncResult(task_id)
result = {
"task_id": task_id,
"task_status": task_result.status,
"task_result": task_result.result
}
return result
第2种
使用 Queue 实例的包含列表的元组
修改文件 celery_utils.py
"""
@ File : celery_utils.py
@ Author : yqbao
@ Version : V1.0.0
@ Description : 配置并获取 celery 实例
"""
from celery import Celery
from celery.result import AsyncResult
from kombu import Queue
def create_celery():
celery = Celery(__name__)
celery.conf.update(timezone="Asia/Shanghai") # 时区
celery.conf.update(enable_utc=False) # 关闭UTC时区。默认启动
# 任务路由,为任务分配不同的队列(可理解为分组)
# 方案2
# main.*,表示匹配所有 main.开头的任务,匹配支持正则表达式
celery.conf.update(task_routes=(
Queue(name='celery', routing_key='main.*'),
Queue(name='universities', routing_key='universities:*'),
Queue(name='university', routing_key='university:*'),
))
celery.conf.update(task_track_started=True) # 启动任务跟踪
celery.conf.update(task_serializer='pickle') # 任务序列化方式
celery.conf.update(result_serializer='pickle') # 结果序列化方式
celery.conf.update(accept_content=['pickle', 'json']) # 接受的类型
celery.conf.update(result_expires=200) # 结 果过期时间,200s
celery.conf.update(result_persistent=True)
celery.conf.update(worker_send_task_events=False)
celery.conf.update(worker_prefetch_multiplier=1)
celery.conf.update(broker_connection_retry_on_startup=True) # 启动时重试代理连接
return celery
def get_task_info(task_id):
"""返回给定task_id的任务信息"""
task_result = AsyncResult(task_id)
result = {
"task_id": task_id,
"task_status": task_result.status,
"task_result": task_result.result
}
return result
第3种
使用任务名称,自动分配队列
- 修改文件
celery_utils.py
"""
@ File : celery_utils.py
@ Author : yqbao
@ Version : V1.0.0
@ Description : 配置并获取 celery 实例
"""
from celery import Celery
from celery.result import AsyncResult
def route_for_ask(name, *args, **kwargs):
if ":" not in name:
return {"queue": "celery"}
queue, _ = name.split(":")
return {"queue": queue}
def create_celery():
celery = Celery(__name__)
celery.conf.update(timezone="Asia/Shanghai") # 时区
celery.conf.update(enable_utc=False) # 关闭UTC时区。默认启动
# 任务路由,为任务分配不同的队列(可理解为分组)
# 方案3
celery.conf.update(task_routes=(route_for_ask,))
celery.conf.update(task_track_started=True) # 启动任务跟踪
celery.conf.update(task_serializer='pickle') # 任务序列化方式
celery.conf.update(result_serializer='pickle') # 结果序列化方式
celery.conf.update(accept_content=['pickle', 'json']) # 接受的类型
celery.conf.update(result_expires=200) # 结 果过期时间,200s
celery.conf.update(result_persistent=True)
celery.conf.update(worker_send_task_events=False)
celery.conf.update(worker_prefetch_multiplier=1)
celery.conf.update(broker_connection_retry_on_startup=True) # 启动时重试代理连接
return celery
def get_task_info(task_id):
"""返回给定task_id的任务信息"""
task_result = AsyncResult(task_id)
result = {
"task_id": task_id,
"task_status": task_result.status,
"task_result": task_result.result
}
return result
- 任务名称的设置,见
tasks.py文件中的name
"""
@ File : tasks.py
@ Author : yqbao
@ Version : V1.0.0
@ Description : 添加 Celery 任务
"""
from typing import List
from celery import shared_task
import universities
# name='universities:get_all_universities_task',冒号前的值,决定此任务被分配到那个队列中执行
@shared_task(bind=True, autoretry_for=(Exception,), retry_backoff=True, retry_kwargs={"max_retries": 5},
name='universities:get_all_universities_task')
def get_all_universities_task(self, countries: List[str]):
data: dict = {}
for cnt in countries:
data.update(universities.get_all_universities_for_country(cnt))
return data
@shared_task(bind=True, autoretry_for=(Exception,), retry_backoff=True, retry_kwargs={"max_retries": 5},
name='university:get_university_task')
def get_university_task(self, country: str):
university = universities.get_all_universities_for_country(country)
return university
启动 API 与 Celery:
-
启动
api:启动后访问http://127.0.0.1:9000/docs查看 API 文档 -
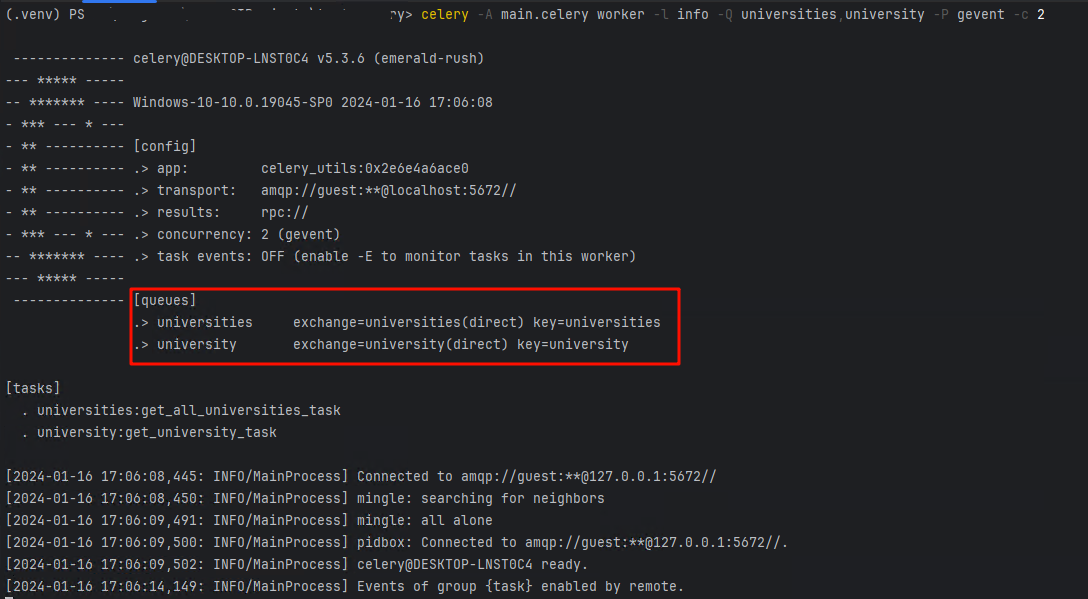
添加队列分组后启动命令,与不分组有所不同
# -Q:启动队列,celery为默认队列,不需要则不加
celery -A main.celery worker -l info -Q universities,university -P gevent -c 2
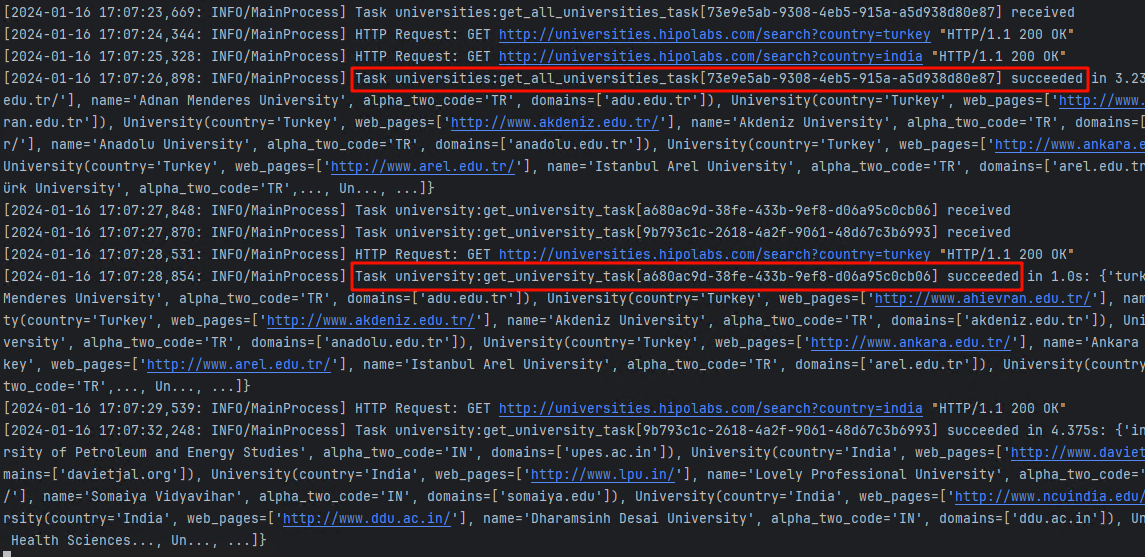
执行任务API,查看任务结果
- 在 API 文档中 分别执行
/universities/async/universities/parallel你分别会看到下面这样的结果
本文来自博客园作者:星尘的博客,转载请注明出处:https://www.cnblogs.com/yqbaowo/p/17968110
合集:
FastAPI 使用笔记
标签:
Python3


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!