FastAPi Celery RabbitMQ 与 Redis 的使用,并使用 Flower 监控 Celery 状态
FastAPi Celery RabbitMQ 与 Redis 的使用,并使用 Flower 监控 Celery 状态
本文介绍了Windows 下 FastAPi Celery 使用 RabbitMQ 与 Redis 做代理的使用方法,本文参考了国外大佬的文章,并做了修改与补充,原文见这里,Suman Das,他文章中的完整代码,见这里,GitHub
RabbitMQ 与 Redis 的主要优缺点正如 Celery 官网介绍的那样:
- RabbitMQ 功能齐全、稳定、耐用且易于安装。它是生产环境的绝佳选择。
- Redis 的功能也很齐全,但在突然终止或断电时更容易丢失数据。
同时你也可以看这篇文章,里面详细的列出了使用 RabbitMQ 与 Redis 的差异,RabbitMQ和Redis之间有什么区别?文章见这里
环境准备
- Windows 安装 RabbitMQ,可见这里,Linux系统则需要自行查阅资料了
- Windows 安装 Redis 很简单,直接下载安装即可,可见这里,GitHub
- 其余环境
requirements.txt
# windows 10
# Python 3.10.11 X64
fastapi==0.109.0
uvicorn[standard]==0.25.0
flower==2.0.1
httpx==0.26.0
celery[redis]==5.3.6
gevent==23.9.1
kombu==5.3.5
pydantic==2.5.3
starlette==0.35.1
代码准备
结构:
--- test_celery
|--- celery_utils.py
|--- main.py
|--- router.py
|--- schemas.py
|--- tasks.py
|--- universities.py
- 新建
main.py用于作为 tAPI 入口
"""
@ File : main.py
@ Author : yqbao
@ Version : V1.0.0
@ Description : API 入口
"""
import uvicorn as uvicorn
from fastapi import FastAPI
import router
from celery_utils import create_celery
app = FastAPI(version="1.0.0", )
app.celery = create_celery() # 将celery实例挂到app全局实例中
app.include_router(router.router)
celery = app.celery
# 设置celery的代理路径与结果存储路径,此处均使用 RabbitMQ
celery.conf.update(broker_url="amqp://guest:guest@localhost:5672//") # 代理
celery.conf.update(result_backend="rpc://") # 结果存储
# 设置celery的代理路径与结果存储路径,此处均使用 Redis
# 默认用户可省略:redis://:<You Passowrd>@localhost:6379/0
# celery.conf.update(broker_url="redis://default:<You Passowrd>@localhost:6379/0") # 代理
# celery.conf.update(result_backend="redis://default:<You Passowrd>@localhost:6379/1") # 结果存储
if __name__ == "__main__":
uvicorn.run("main:app", port=9000, reload=True)
- 添加文件
celery_utils.py配置并获取celery实例
"""
@ File : celery_utils.py
@ Author : yqbao
@ Version : V1.0.0
@ Description : 配置并获取 celery 实例
"""
from celery import Celery
from celery.result import AsyncResult
# 配置 https://docs.celeryq.dev/en/stable/userguide/configuration.html#general-settings
def create_celery():
celery = Celery(__name__)
celery.conf.update(timezone="Asia/Shanghai") # 时区
celery.conf.update(enable_utc=False) # 关闭UTC时区。默认启动
celery.conf.update(task_track_started=True) # 启动任务跟踪
# celery.conf.update(task_serializer='pickle') # 任务序列化方式(默认json)
# celery.conf.update(result_serializer='pickle') # 结果序列化方式(默认json)
# celery.conf.update(accept_content=['pickle', 'json']) # 接受的类型(默认json)
celery.conf.update(result_expires=200) # 结果过期时间,200s
celery.conf.update(result_persistent=True) # True,表示结果消息将是持久的。这意味着代理重新启动后消息不会丢失。
celery.conf.update(worker_send_task_events=False)
celery.conf.update(worker_prefetch_multiplier=1)
celery.conf.update(broker_connection_retry_on_startup=False) # 关闭启动时重试代理连接,默认启动
return celery
def get_task_info(task_id):
"""返回给定task_id的任务信息"""
task_result = AsyncResult(task_id)
result = {
"task_id": task_id,
"task_status": task_result.status,
"task_result": task_result.result
}
return result
- 文件
tasks.py添加Celery任务
"""
@ File : tasks.py
@ Author : yqbao
@ Version : V1.0.0
@ Description : 添加 Celery 任务
"""
from typing import List
from celery import shared_task
import universities
# 使用 @shared_task 来复用 celery 实例,也就是 create_celery() 中的实例,而不需要每次都新建 celery 实例
# 并开启 celery 内置的失败重试功能
@shared_task(bind=True, autoretry_for=(Exception,), retry_backoff=True, retry_kwargs={"max_retries": 5},
name='universities:get_all_universities_task')
def get_all_universities_task(self, countries: List[str]):
data: dict = {}
for cnt in countries:
data.update(universities.get_all_universities_for_country(cnt))
return data
@shared_task(bind=True, autoretry_for=(Exception,), retry_backoff=True, retry_kwargs={"max_retries": 5},
name='university:get_university_task')
def get_university_task(self, country: str):
university = universities.get_all_universities_for_country(country)
return university
- 文件
router.py添加 API 路由
"""
@ File : router.py
@ Author : yqbao
@ Version : V1.0.0
@ Description : API 路由
"""
from celery import group
from fastapi import APIRouter
from starlette.responses import JSONResponse
import universities
from celery_utils import get_task_info
from schemas import Country
from tasks import get_all_universities_task, get_university_task
router = APIRouter(prefix='/universities', tags=['University'], responses={404: {"description": "Not found"}})
# 该 API 是普通的 API,与 Celery 无关
@router.post("/")
def get_universities(country: Country) -> dict:
"""返回提供的国家/地区的大学列表,例如 [“土耳其”、“印度”、“澳大利亚”],以同步方式输入"""
data: dict = {}
for cnt in country.countries:
data.update(universities.get_all_universities_for_country(cnt))
return data
# 该 API 用于演示如何使用 Celery 异步执行长时间运行的任务。
# 当我们调用此 API 时,它会向代理提交一条任务消息并返回该消息的任务 ID。
@router.post("/async")
async def get_universities_async(country: Country):
"""
返回提供的国家/地区的大学列表,例如 [“土耳其”、“印度”、“澳大利亚”],
以异步方式输入。它只返回任务 ID,稍后可用于获取结果。
"""
task = get_all_universities_task.apply_async(args=[country.countries])
return JSONResponse({"task_id": task.id})
# 该 API 用于演示通过任务 ID 获取任务运行状态
@router.get("/task/{task_id}")
async def get_task_status(task_id: str) -> dict:
"""返回已提交任务的状态"""
return get_task_info(task_id)
# 该 API 用于演示如何使用 Celery 将大型任务拆分为较小的子任务并并行执行
# 当我们调用此 API 时,我们会为作为输入提供的每个国家/地区创建一个任务。一旦所有任务完成,小组就完成了,我们将得到结果。
@router.post("/parallel")
async def get_universities_parallel(country: Country) -> dict:
"""
返回提供的国家/地区的大学列表,例如 [“土耳其”、“印度”、“澳大利亚”],
以同步方式输入。这将使用 Celery 以并行方式执行子任务
"""
data: dict = {}
tasks = []
for cnt in country.countries:
tasks.append(get_university_task.s(cnt))
# create a group with all the tasks
job = group(tasks)
result = job.apply_async()
ret_values = result.get(disable_sync_subtasks=False)
for result in ret_values:
data.update(result)
return data
- 文件
universities.py获取大学列表
"""
@ File : universities.py
@ Author : yqbao
@ Version : V1.0.0
@ Description : 获取大学列表
"""
import json
import httpx
from schemas import University
def get_all_universities_for_country(country: str) -> dict:
url = 'http://universities.hipolabs.com/search'
params = {'country': country}
client = httpx.Client()
response = client.get(url, params=params)
response_json = json.loads(response.text)
universities = []
for university in response_json:
university_obj = University.model_validate(university)
universities.append(university_obj)
return {country: universities}
- 文件
schemas.py用于数据校验的pydantic模型
"""
@ File : schemas.py
@ Author : yqbao
@ Version : V1.0.0
@ Description : 数据校验
"""
from typing import Optional, List
from pydantic import BaseModel
class University(BaseModel):
country: Optional[str] = None
web_pages: List[str] = []
name: Optional[str] = None
alpha_two_code: Optional[str] = None
domains: List[str] = []
class Country(BaseModel):
countries: List[str] = ['turkey', 'india']
启动 API 与 Celery
- 启动
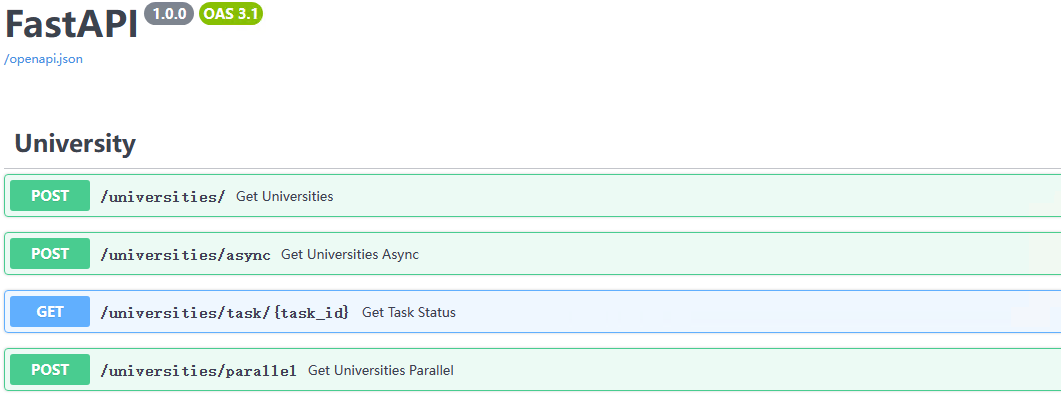
api:启动后访问http://127.0.0.1:9000/docs查看 API 文档
# 项目根目录下执行
Python main.py

- 启动
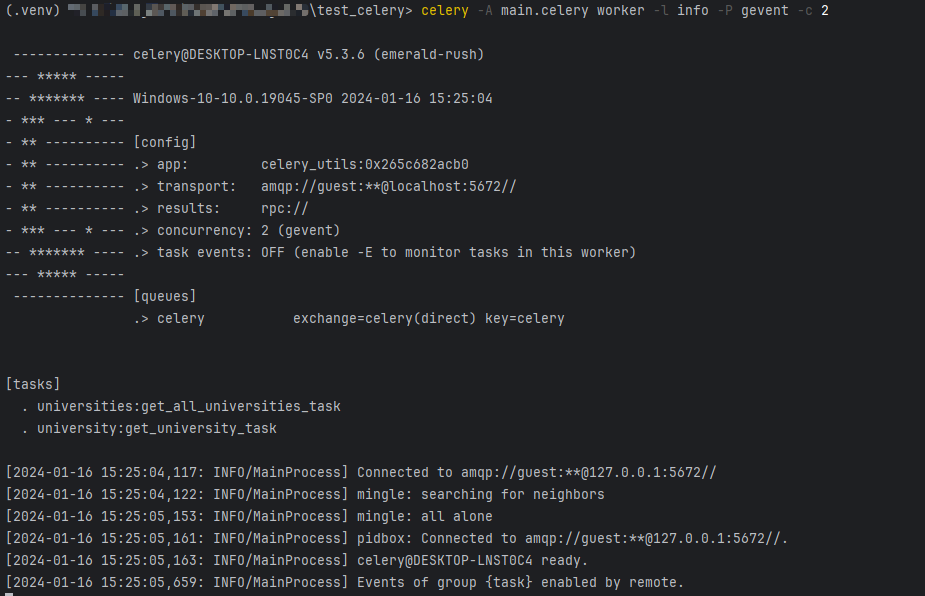
Celery:
# 项目根目录下执行,-P:Windos下必须用,否则会报错,-c:windows下是协程数。默认是10
celery -A main.celery worker -l info -P gevent -c 2
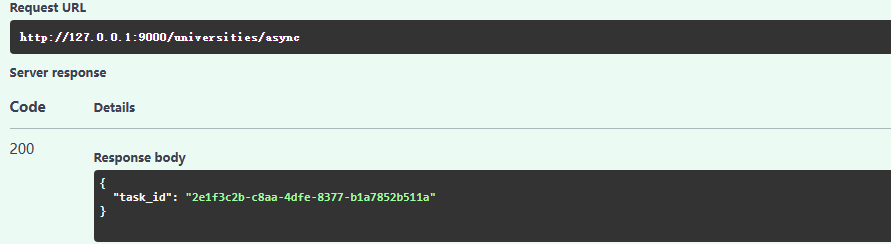
执行任务API,查看任务结果
- 在 API 文档中 执行
http://127.0.0.1:9000/universities/async你分别会看到下面这样的结果,就表示成功了

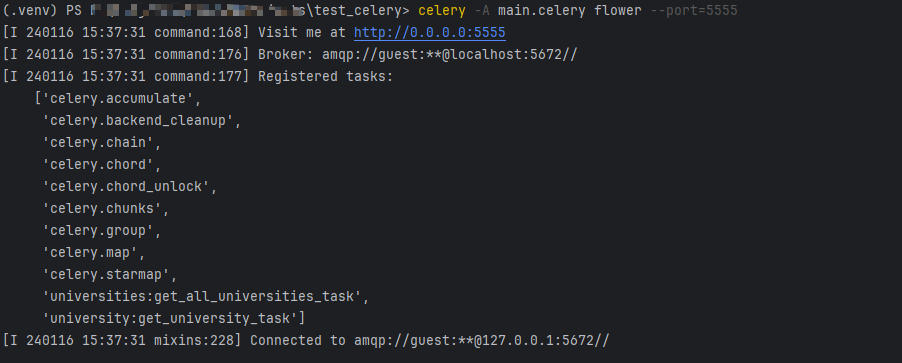
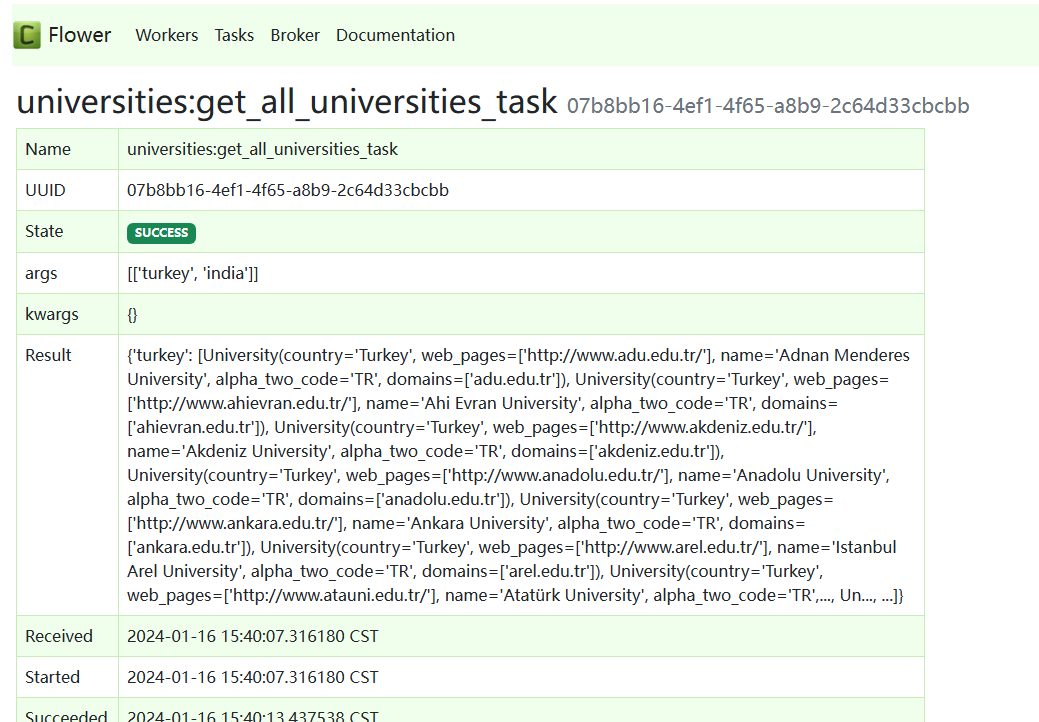
启动 Flower 监控 Celery 的状态
- 启动
Flower(注意:Celery也要启动)
# 项目根目录下执行,--port:flower端口
celery -A main.celery flower --port=5555
- 访问
Flower:浏览器打开http://127.0.0.1:5555/

- 在 API 文档中 执行
http://127.0.0.1:9000/universities/async后会看到这样的结果,点击可查看任务执行详情

本文来自博客园作者:星尘的博客,转载请注明出处:https://www.cnblogs.com/yqbaowo/p/17967525
