
datax(一):整体调用流程
调用方法流程
datax的调度机制:
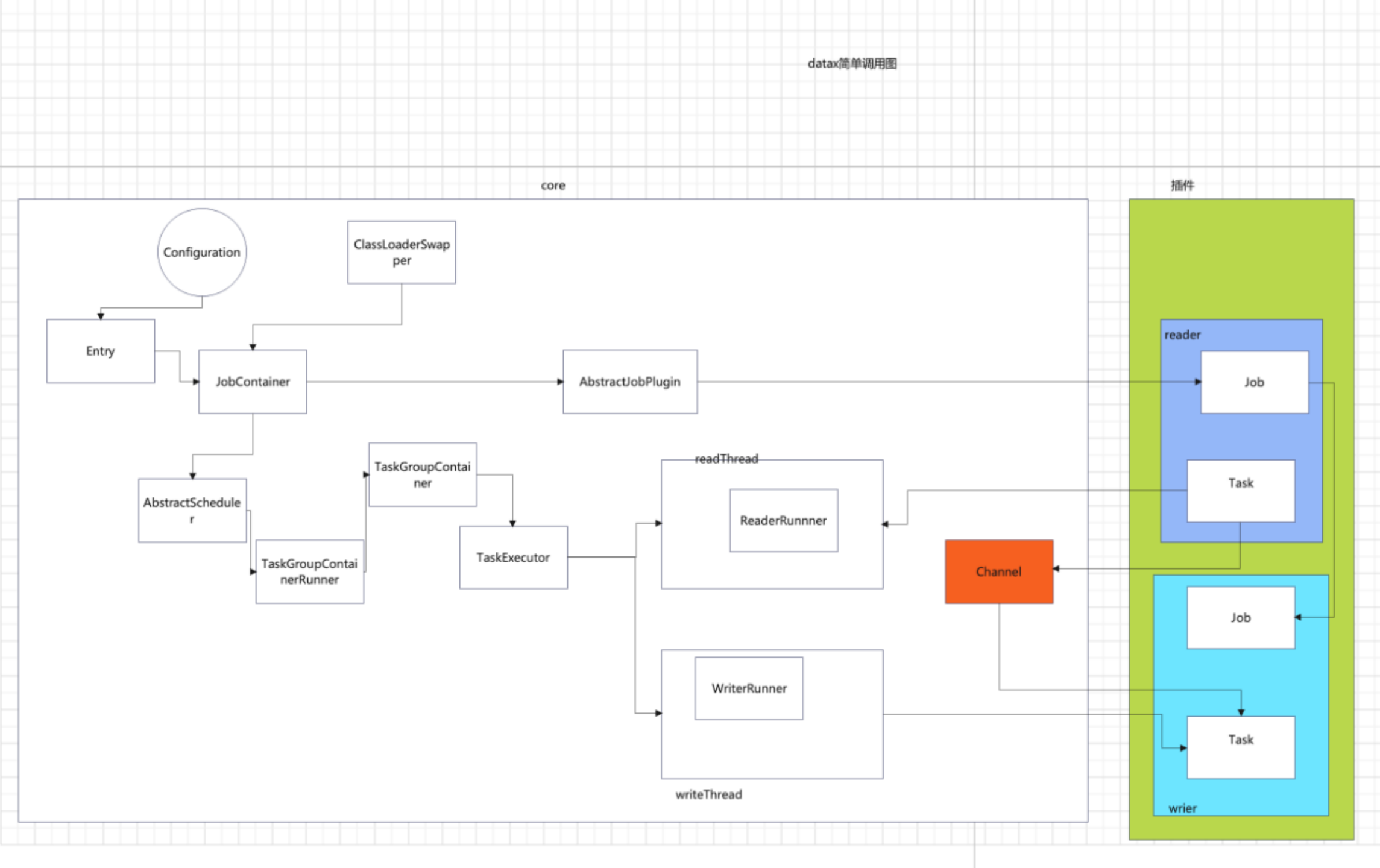
具体类和方法过程:
Engine
entry():
解析参数
start():
初始化JobContainer
调用JobContainer.start()方法,开启任务
JobContainer
start():
执行job的preHandle()、init()、schedule()...等方法,会切换jar加载器,执行插件的对应的方法。
其中schedule()方法执行调度,启动所有工作
schedule():
初始化StandAloneScheduler对象
调用StandAloneScheduler的schedule()方法
StandAloneScheduler:
schedule():
开启所有的任务组,开始执行任务:startAllTaskGroup()
startAllTaskGroup():
创建线程池,执行TaskGroupContainerRunner任务。
TaskGroupContainerRunner:
run():
调用TaskGroupContainer对象的start()方法
TaskGroupContainer:
start():
创建TaskExecutor对象,执行对应的doStart()方法
TaskExecutor:
doStart():
启动write线程和read线程,开始工作。
read线程执行ReaderRunner中的任务,write线程执行WriteRuner的任务。
ReaderRunner:
run():
获取TaskReader,调用init()、prepare()、startRead(recordSender)等方法
这些方法都是在插件中实现的方法。以TxtFileReader为例。
重点是startRead(recordSender)方法,将读出来的数据发送给writer。
TxtFileReader:
startRead():
获取文件流的内容
调用工具类UnstructuredStorageReaderUtil.readFromStream()将文件流的内容通过RecordSender发送给writer
UnstructuredStorageReaderUtil
readFromStream():
进行各种格式的流的包装
读取每一行,调用RecordSender.sendToWrtiter()方法,将record发送给writer。
RecordExchanger:
sendToWriter():
调用channel的push()方法,将record放到channel中
MemoryChannel:
push():
将record放到自己的阻塞队列ArrayBlockingQueue中
==》到这,reader就读取到数据,放到阻塞队列中,writer就从这个阻塞队列来取数据。
在reader线程启动ReaderRunner任务的同时,writer线程也启动了WriterRunner任务,只要reader线程的ReaderRunner往阻塞队列中扔数据,writer线程就通过WriterRunner从阻塞队列中取数据,然后写到配置的某处。
WriterRunner:
run():
获取taskWriter
调用Task.Writer对象的init()、prepare()、startWrite(recordReceiver)等方法,这些方法都是由自定义插件实现的方法。
关键是startWrite(recordReceiver)方法,从RecordReceiver获取到数据,然后写入到用户配置的指定位置。
以RbdmsWriter的startWrite()方法为例
RdbmsWriter:
startWrite():
调用RecordReceiver对象的getFromReader()方法,获取Record
将每行加入缓存中,批量插入数据库
RecordReceiver接口===》RecordExchange类:
getFromReader():
调用channel的pull()方法,获取一行记录,并返回。
MemoryChannle
pull():
从阻塞队列中获取一条记录,并返回
自此,Writer线程拿到Reader线程的数据,完成同步工作。
每一步都封装了很多业务逻辑和判断,涉及到各种统计信息。待分析.....

