Dataloader类
Dataloader类
DataLoader是Pytorch中用来处理模型输入数据的一个工具类。结合了数据集(dataset) 和 采样器(sampler),并在数据集上提供单线程或多线程(num_workers )的可迭代对象。官网定义如下:
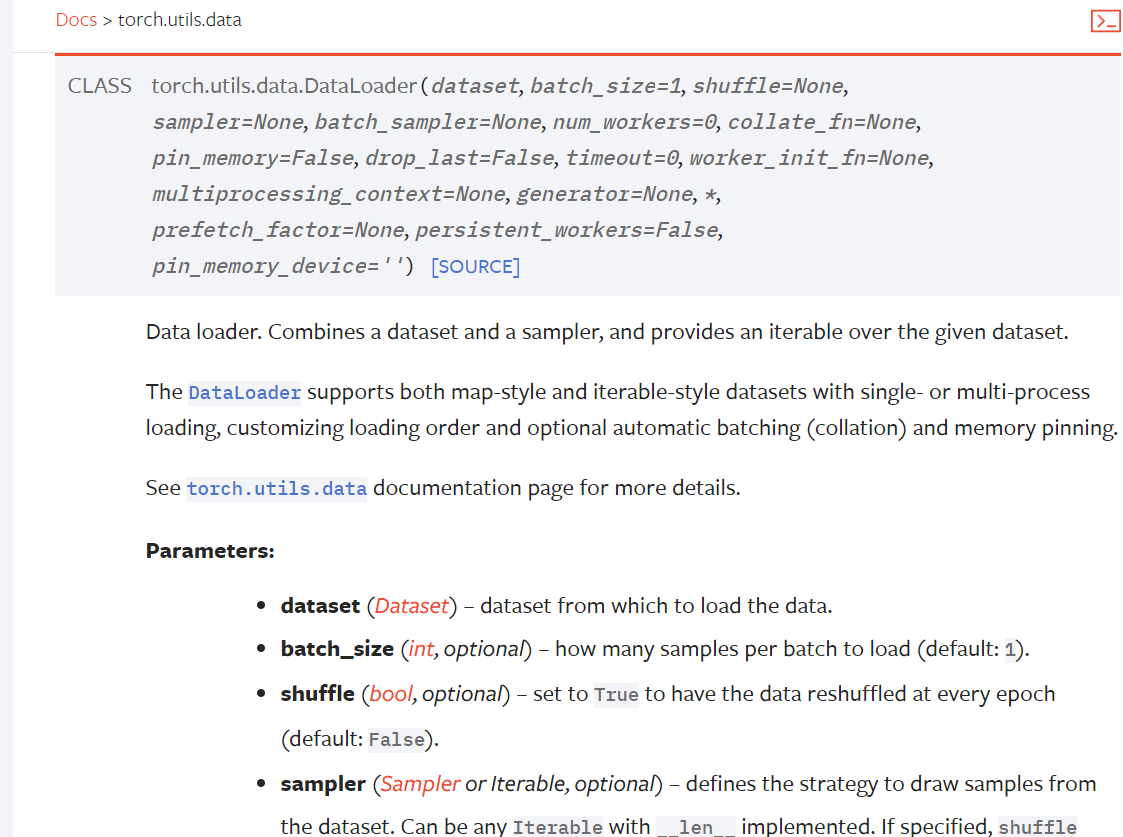
主要参数说明:
dataset:使用的数据集(可以是自定义的数据集);
batch_size:每次取样的大小,默认1;
shuffle:每轮取样时数据集顺序是否打乱,默认False,一般设置为True;
epoch:表示一轮,将数据集中的所有数据进行取样结束算一轮;
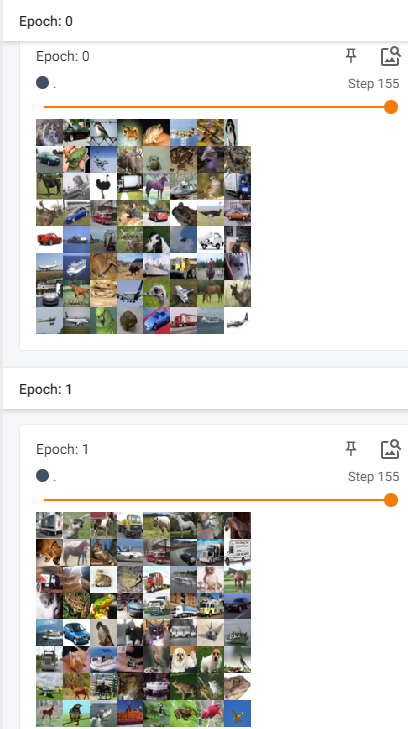
左侧为False不打乱两轮的每一步的取样(epoch 0和epoch 1)结果都相同,右侧为True打乱顺序

sampler:采样的策略,默认随机采样
num_workers:表示加载数据时采用单个进程还是多个进程进行加载,默认为0使用主进程进行加载(在Windows下大于0时有时会出现问题,当出现BrokenPipeError时可以考虑设为0来解决问题);
drop_last:当取样时数据集中数量不足取样数时是否舍去剩下的数据,默认False不舍去;
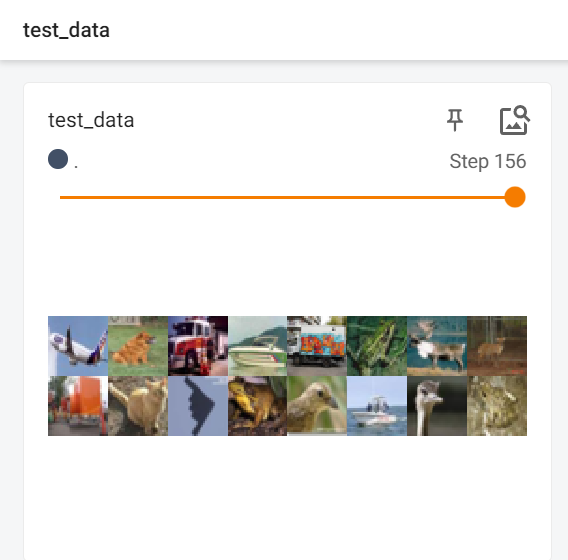
左侧drop_last为False,右侧为True

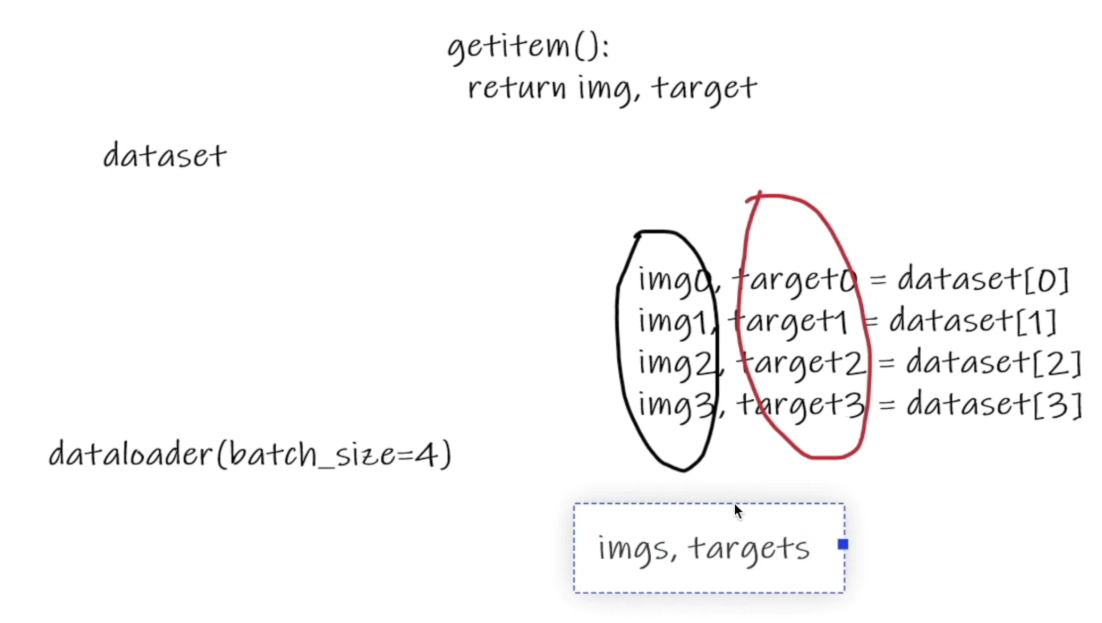
dataset 与 dataloader
import torchvision.datasets
# 准备的测试数据集
from torch.utils.data import DataLoader
test_data = torchvision.datasets.CIFAR10("./dataset2", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)
# 定义test_loader时,batch_size=64,表示一次从数据集中取出64个数据图像(64个的图像放一起打包,标签放一起打包)
for data in test_loader:
imgs, targets = data
print(imgs.shape)
print(targets)
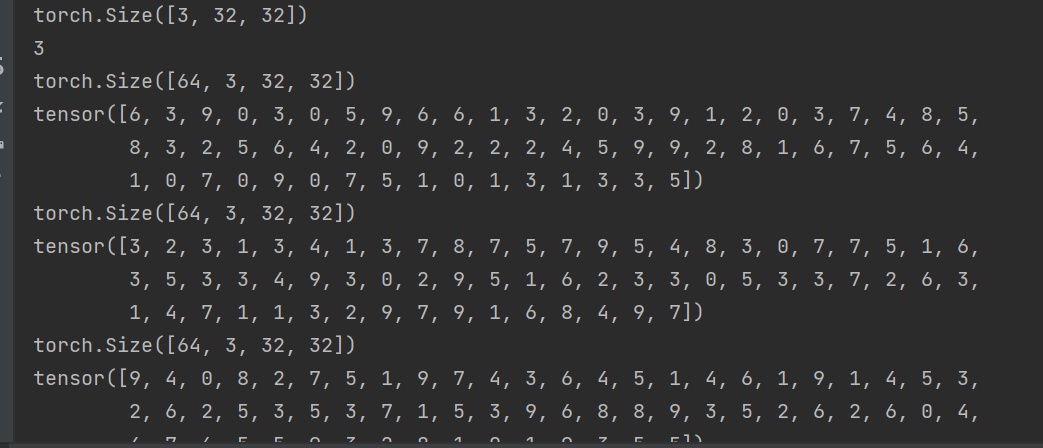
前两行为测试集中第一张图片及target的输出:3表示RGB三通道,图片大小是32×32的,第二行3表示标签类别
后面为batch_size=64时的输出结果:64表示batch_size的大小,后面三个数字和一张图片时的含义相同,下面为64个图片的targets
import torchvision.datasets
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset2", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
writer = SummaryWriter("logs")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
# 注意此处是images不是image
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具