scrapy:快速入门
1. 安装

2. 项目创建与运行


3. 项目组织架构

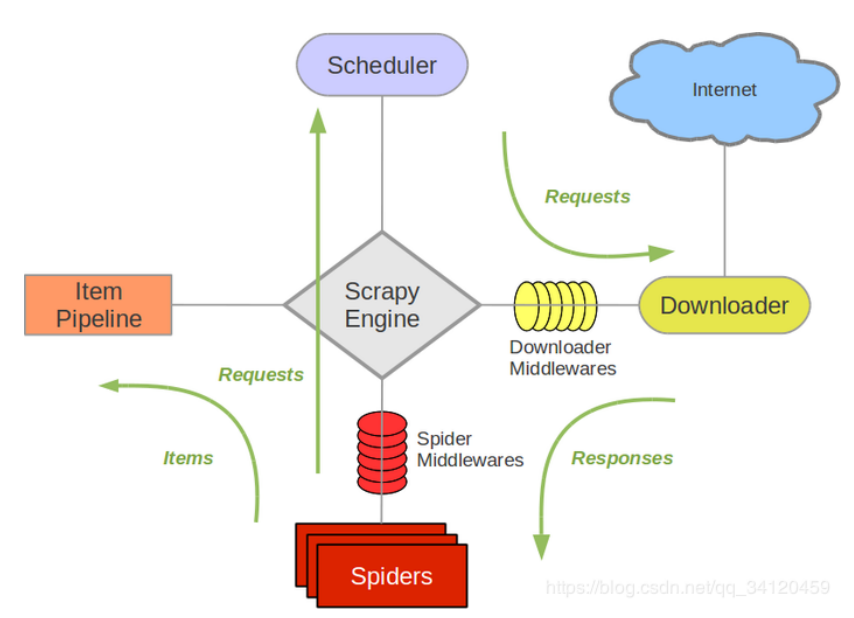
4. 工作原理
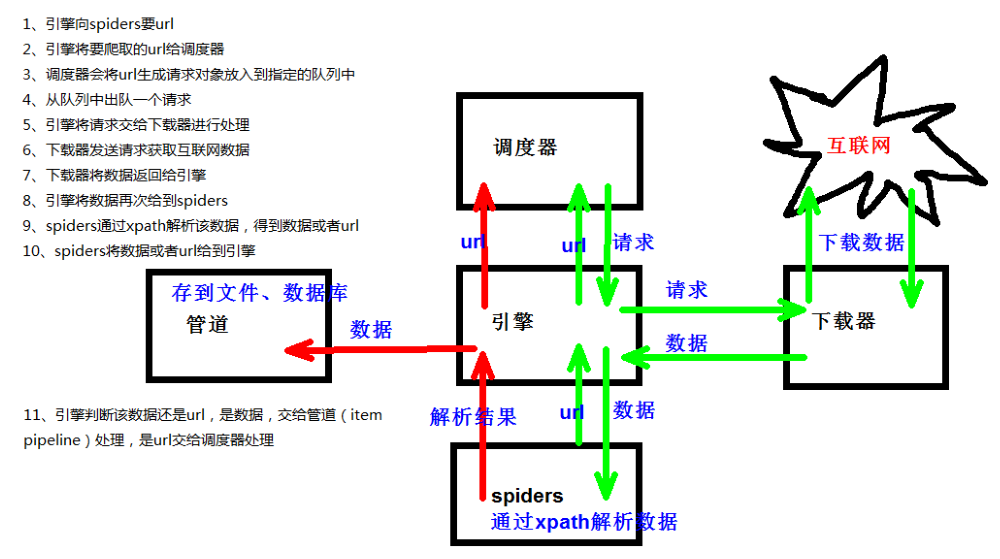
5. 案例-百度首页
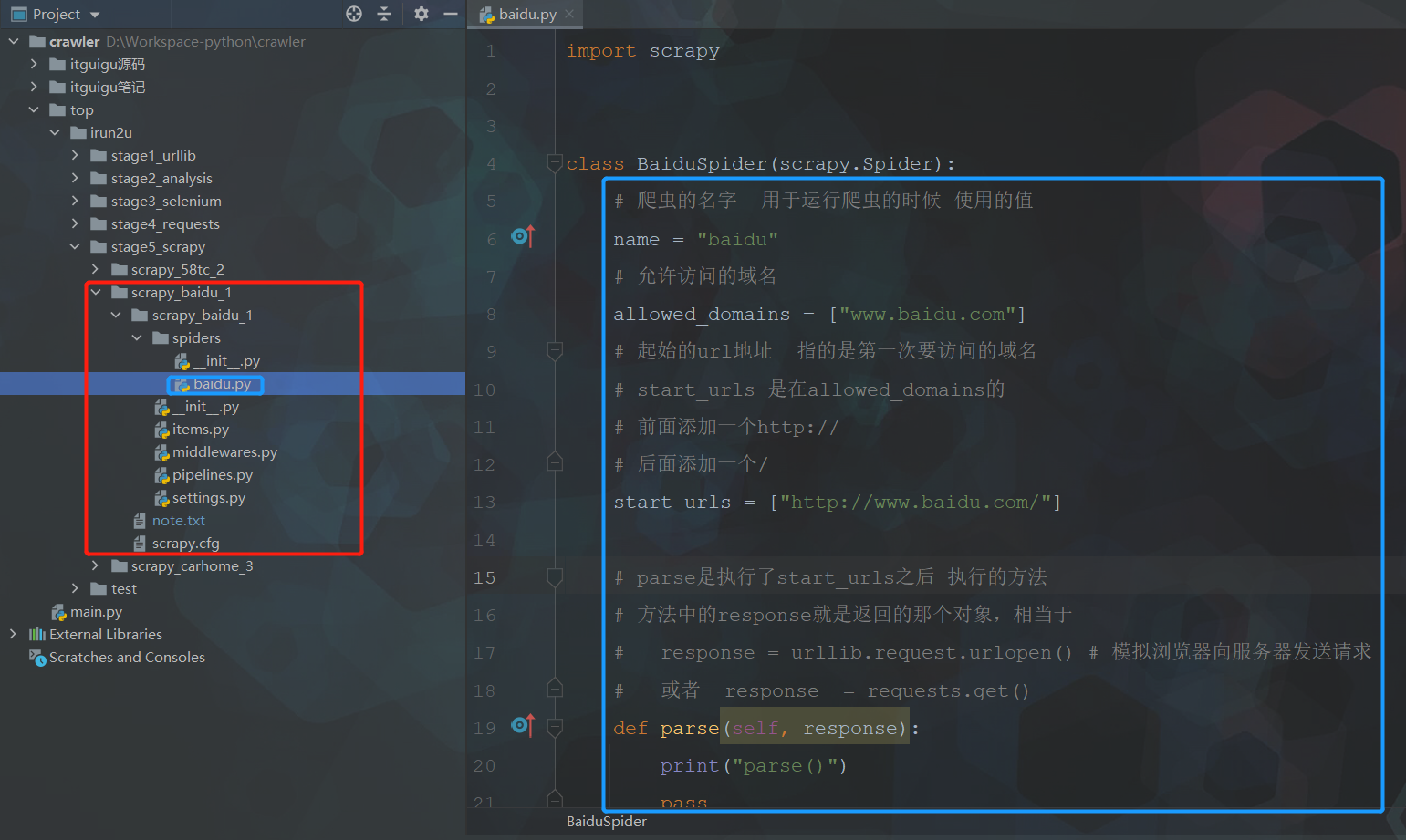
-
创建爬虫的项目 【scrapy startproject 项目的名字】
注意:项目的名字不允许使用数字开头 也不能包含中文 -
创建爬虫文件
要在spiders文件夹中去创建爬虫文件
【cd 项目的名字\项目的名字\spiders】
cd scrapy_baidu_091\scrapy_baidu_091\spiders
创建爬虫文件
【scrapy genspider 爬虫文件的名字 要爬取网页】
eg:scrapy genspider baidu http://www.baidu.com
一般情况下不需要添加http协议 因为start_urls的值是根据allowed_domains
修改的 所以添加了http的话 那么start_urls就需要我们手动去修改了 -
运行爬虫代码
【scrapy crawl 爬虫的名字】
eg:scrapy crawl baidu -
[可选]scrapy shell 调试
进入到scrapy shell的终端 直接在window的终端中输入【scrapy shell 域名】
如果想看到一些高亮 或者 自动补全 那么可以安装ipython pip install ipython
例如scrapy shell www.baidu.com
6. 案例-58同城
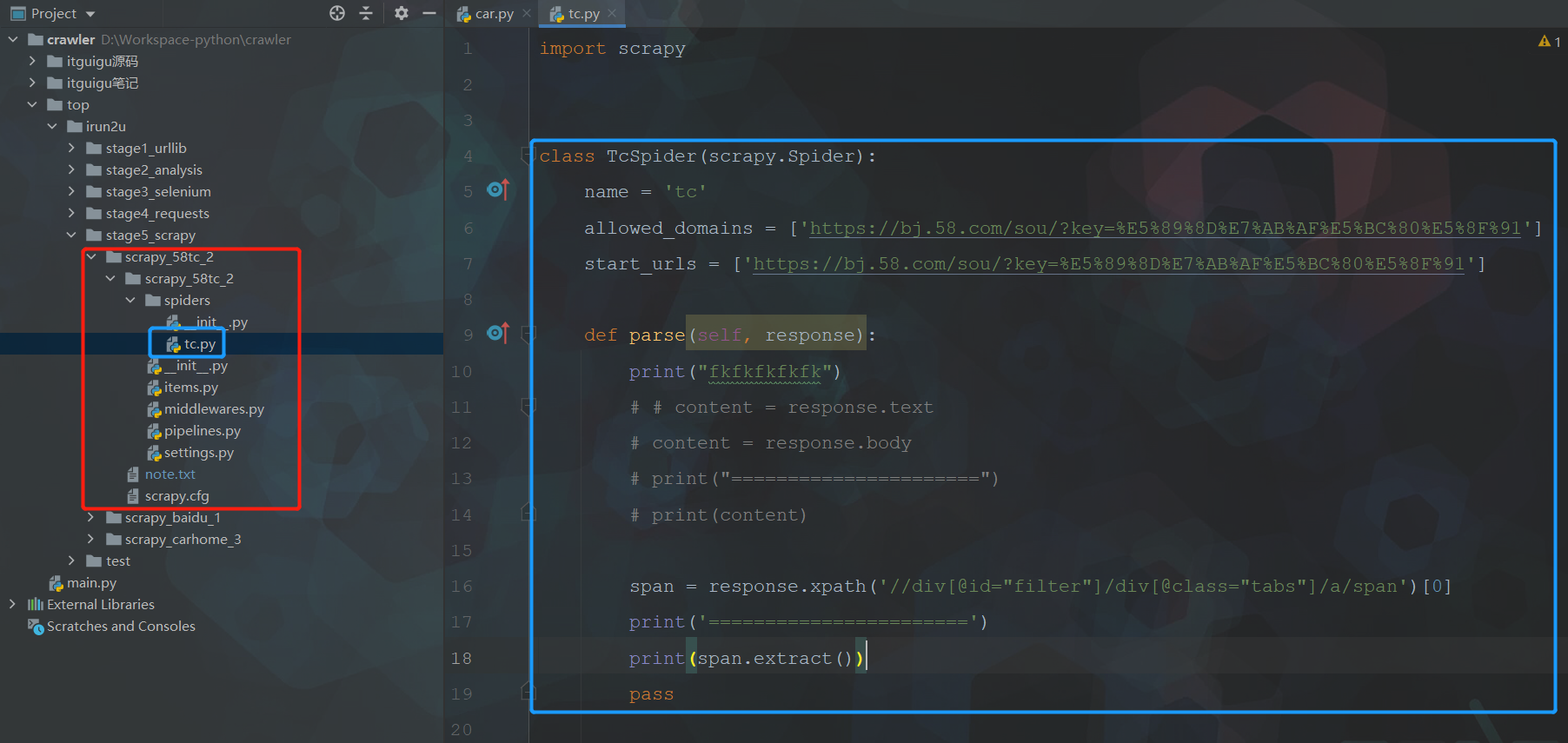
-
scrapy项目的结构
项目名字
项目名字
spiders文件夹 (存储的是爬虫文件)
init
自定义的爬虫文件(核心功能文件)
init
items 定义数据结构的地方 爬取的数据都包含哪些
middleware 中间件 代理
pipelines 管道 用来处理下载的数据
settings 配置文件 robots协议 ua定义等 -
response的属性和方法
response.text 获取的是响应的字符串
response.body 获取的是二进制数据
response.xpath 可以直接是xpath方法来解析response中的内容
response.extract() 提取seletor对象的data属性值
response.extract_first() 提取的seletor列表的第一个数据
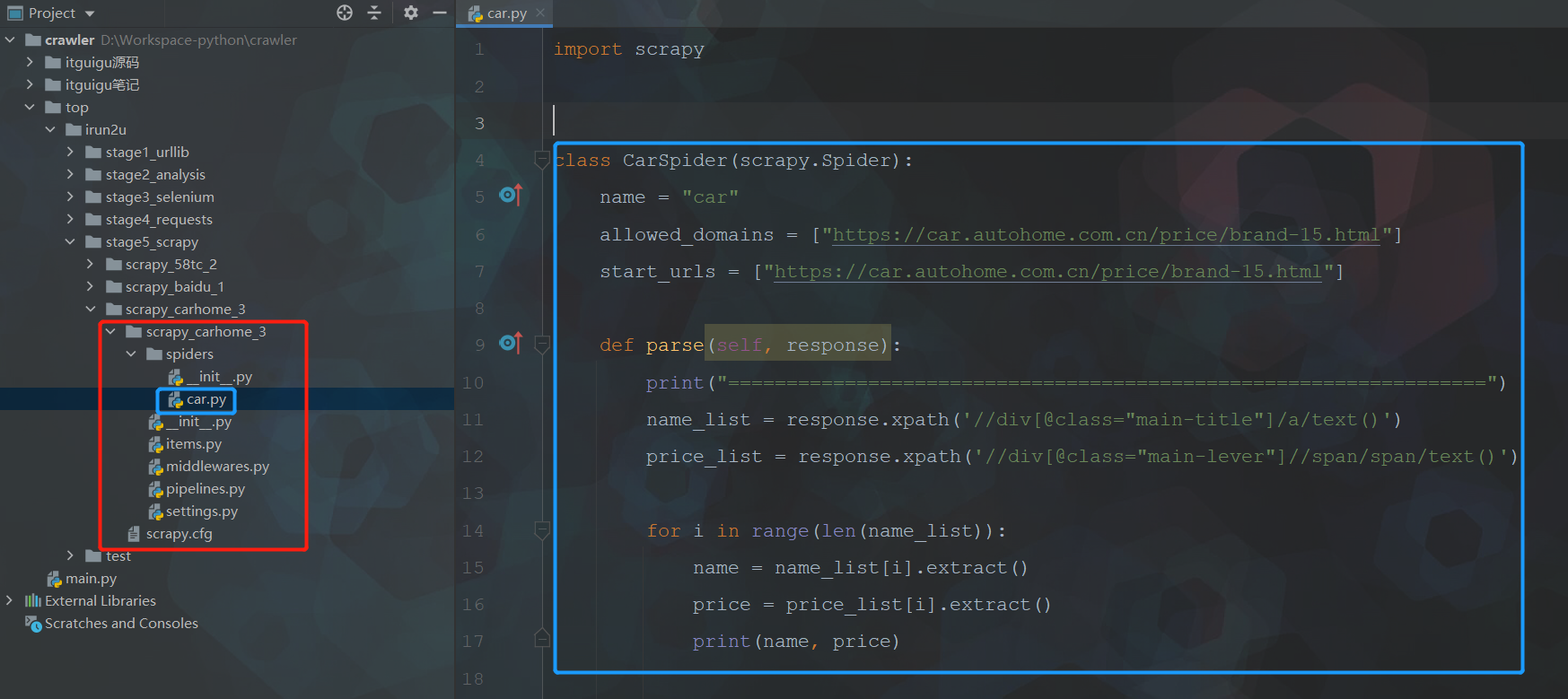
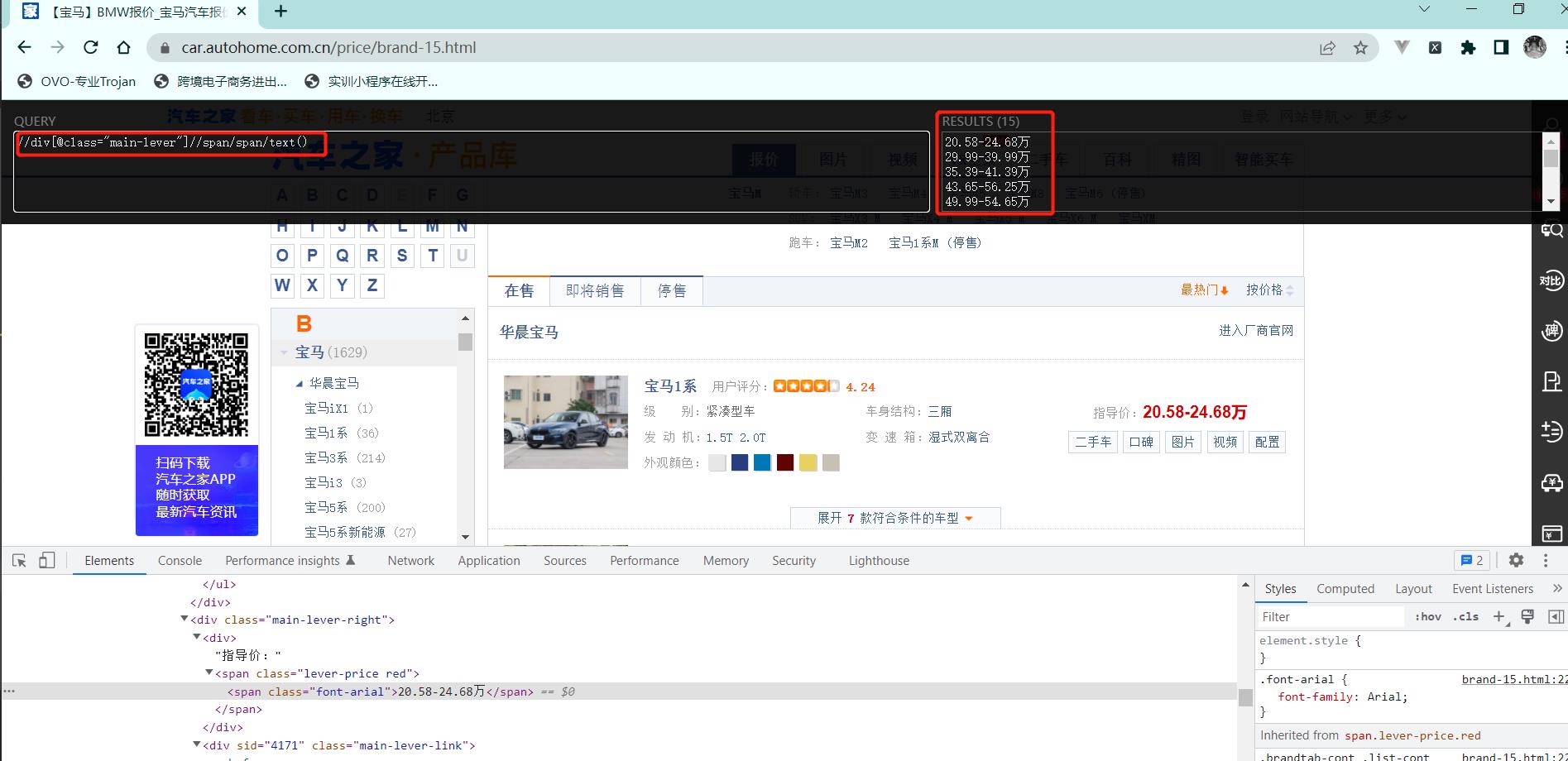
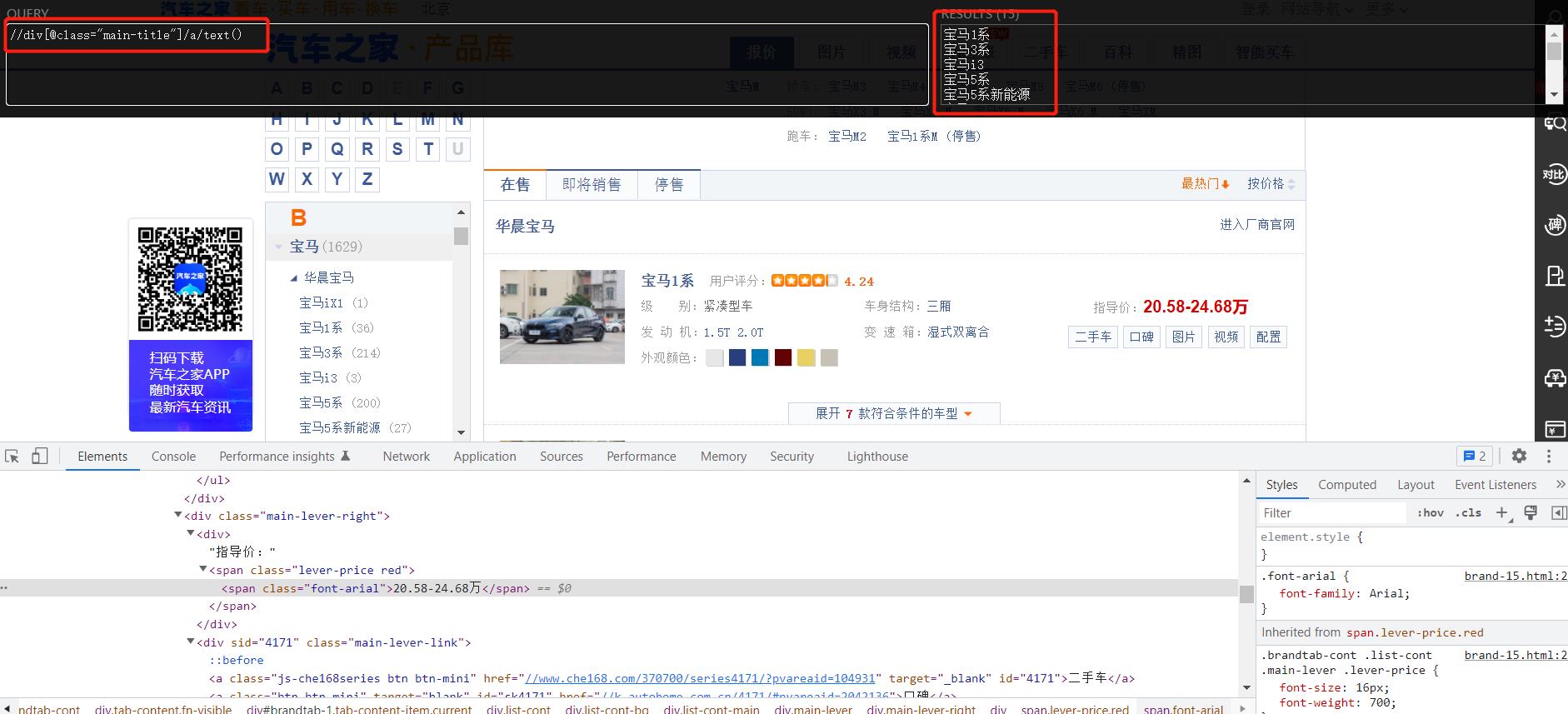
7. 案例-汽车之家


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!