requests: 基本使用、get、post、代理、cookie案例、超级鹰打码api
1、requests_1_基本使用
"""
.-''-.
.--. _..._ .' .-. )
|__| .' '. / .' / /
.--..-,.--. . .-. . (_/ / /
| || .-. | | ' ' | / /
| || | | | _ _ | | | | / / _ _
| || | | || ' / | | | | | . ' | ' / |
| || | '-.' | .' | | | | | / / _.-').' | .' |
|__|| | / | / | | | | | .' ' _.'.-'' / | / |
| | | `'. | | | | | / /.-'_.' | `'. |
|_| ' .'| '/| | | | / _.' ' .'| '/
`-' `--' '--' '--'( _.-' `-' `--'
Created on 2023/5/21 12:30.
@Author: haifei
"""
import time
import requests
'''
requests的一个类型和六个属性
类型 :models.Response
r.text : 获取网站源码
r.encoding :访问或定制编码方式
r.url :获取请求的url
r.content :响应的字节类型
r.status_code :响应的状态码
r.headers :响应的头信息
'''
url = 'http://www.baidu.com'
response = requests.get(url)
print(type(response)) # <class 'requests.models.Response'>
# 与urllib的区别:response = urllib.request.urlopen(url) # <class 'http.client.HTTPResponse'>
# 以字符串形式返回网页源码
print(response.text) # 百度首页网页内容,中文有乱码
# 设置响应的编码格式 解决乱码问题
response.encoding = 'utf-8'
print(response.text)
print(response.url) # http://www.baidu.com/
print(response.content) # 返回二进制格式网页源码
print(response.status_code) # 返回响应的状态码 200
print(response.headers) # 返回响应头
# 总结-难点:1隐藏域,2验证码
if __name__ == '__main__':
start = time.time()
print('It takes', time.time() - start, "seconds.")
2. requests_2_get请求&与urllib的对比
"""
.-''-.
.--. _..._ .' .-. )
|__| .' '. / .' / /
.--..-,.--. . .-. . (_/ / /
| || .-. | | ' ' | / /
| || | | | _ _ | | | | / / _ _
| || | | || ' / | | | | | . ' | ' / |
| || | '-.' | .' | | | | | / / _.-').' | .' |
|__|| | / | / | | | | | .' ' _.'.-'' / | / |
| | | `'. | | | | | / /.-'_.' | `'. |
|_| ' .'| '/| | | | / _.' ' .'| '/
`-' `--' '--' '--'( _.-' `-' `--'
Created on 2023/5/21 12:59.
@Author: haifei
"""
import time
import requests
'''
urllib
(1) 一个类型以及六个方法
(2)get请求
(3)post请求 百度翻译
(4)ajax的get请求
(5)ajax的post请求
(6)cookie登陆 微博/qq空间
(7)代理
requests
(1)一个类型以及六个属性
(2)get请求
(3)post请求
(4)代理
(5)cookie 验证码
'''
# url = 'https://www.baidu.com/s?'
url = 'https://www.baidu.com/s' # 可以不带?
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
data = {
'wd': '北京'
}
# url 请求资源路径
# params 参数
# kwargs 字典
response = requests.get(url=url, params=data, headers=headers)
response.encoding = 'utf-8' # 或者'utf8'也行
content = response.text
print(content)
# 总结:
# (1)参数使用params传递
# (2)参数无需urlencode编码
# (3)不需要请求对象的定制
# (4)请求资源路径中的?可以加也可以不加
if __name__ == '__main__':
start = time.time()
print('It takes', time.time() - start, "seconds.")
3. requests_3_post请求
"""
.-''-.
.--. _..._ .' .-. )
|__| .' '. / .' / /
.--..-,.--. . .-. . (_/ / /
| || .-. | | ' ' | / /
| || | | | _ _ | | | | / / _ _
| || | | || ' / | | | | | . ' | ' / |
| || | '-.' | .' | | | | | / / _.-').' | .' |
|__|| | / | / | | | | | .' ' _.'.-'' / | / |
| | | `'. | | | | | / /.-'_.' | `'. |
|_| ' .'| '/| | | | / _.' ' .'| '/
`-' `--' '--' '--'( _.-' `-' `--'
Created on 2023/5/21 13:24.
@Author: haifei
"""
import time
import requests
import json
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
url = "https://fanyi.baidu.com/sug"
data = {
'kw': 'eye'
}
# url 请求地址
# data 请求参数
# kwargs 字典
response = requests.post(url=url, data=data, headers=headers)
content = response.text
print(content)
obj = json.loads(content) # 解决编码问题
print(obj)
# 总结:
# (1)post请求 是不需要编解码
# (2)post请求的参数是data
# (3)不需要请求对象的定制
if __name__ == '__main__':
start = time.time()
print('It takes', time.time() - start, "seconds.")
4. requests_4_代理
"""
.-''-.
.--. _..._ .' .-. )
|__| .' '. / .' / /
.--..-,.--. . .-. . (_/ / /
| || .-. | | ' ' | / /
| || | | | _ _ | | | | / / _ _
| || | | || ' / | | | | | . ' | ' / |
| || | '-.' | .' | | | | | / / _.-').' | .' |
|__|| | / | / | | | | | .' ' _.'.-'' / | / |
| | | `'. | | | | | / /.-'_.' | `'. |
|_| ' .'| '/| | | | / _.' ' .'| '/
`-' `--' '--' '--'( _.-' `-' `--'
Created on 2023/5/21 13:37.
@Author: haifei
"""
import time
import requests
url = 'http://www.baidu.com/s?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
data = {
'wd': 'ip'
}
proxy = {
'http': '58.20.184.187:9091' # 快代理网站-免费代理
}
# response = requests.post(url=url, params=data, headers=headers)
response = requests.post(url=url, params=data, headers=headers, proxies=proxy)
response.encoding = 'utf8'
content = response.text
with open('./daili.html', 'w', encoding='utf8') as fp:
fp.write(content)
if __name__ == '__main__':
start = time.time()
print('It takes', time.time() - start, "seconds.")
5. requests_5_cookie登陆古诗文网






"""
.-''-.
.--. _..._ .' .-. )
|__| .' '. / .' / /
.--..-,.--. . .-. . (_/ / /
| || .-. | | ' ' | / /
| || | | | _ _ | | | | / / _ _
| || | | || ' / | | | | | . ' | ' / |
| || | '-.' | .' | | | | | / / _.-').' | .' |
|__|| | / | / | | | | | .' ' _.'.-'' / | / |
| | | `'. | | | | | / /.-'_.' | `'. |
|_| ' .'| '/| | | | / _.' ' .'| '/
`-' `--' '--' '--'( _.-' `-' `--'
Created on 2023/5/21 13:46.
@Author: haifei
"""
import time
import requests
'''
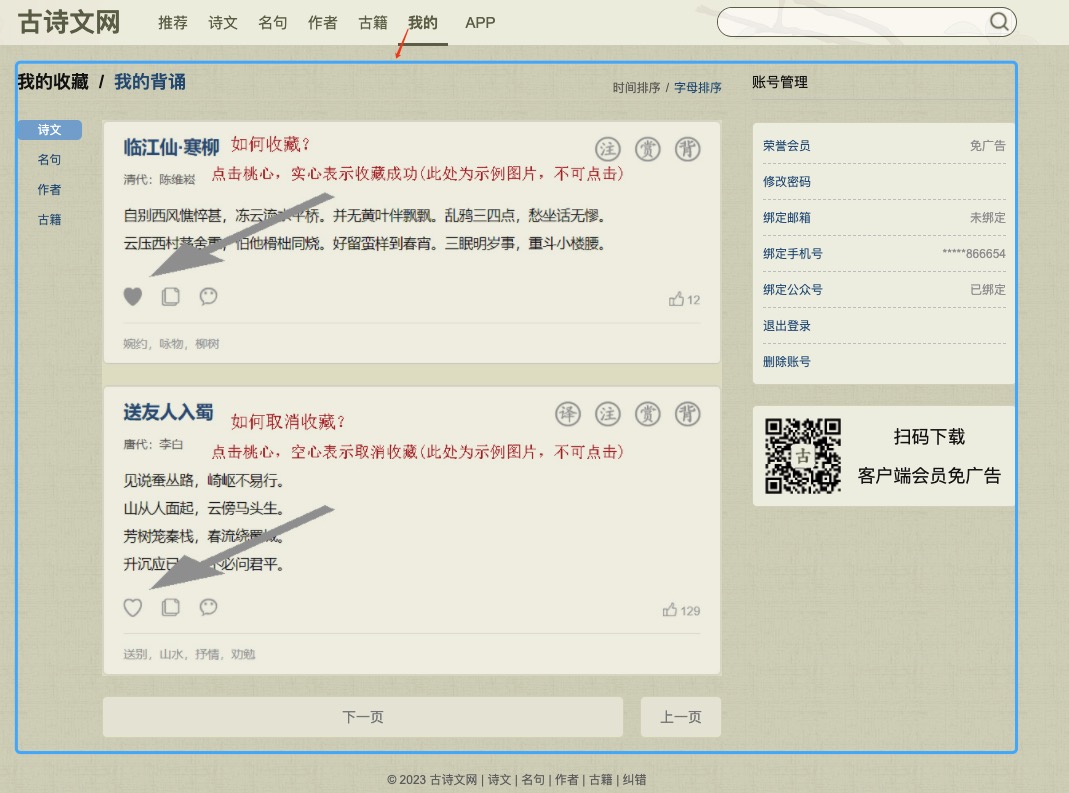
古诗文网https://so.gushiwen.cn/
需求:绕过登陆,直接可以进入"我的"界面
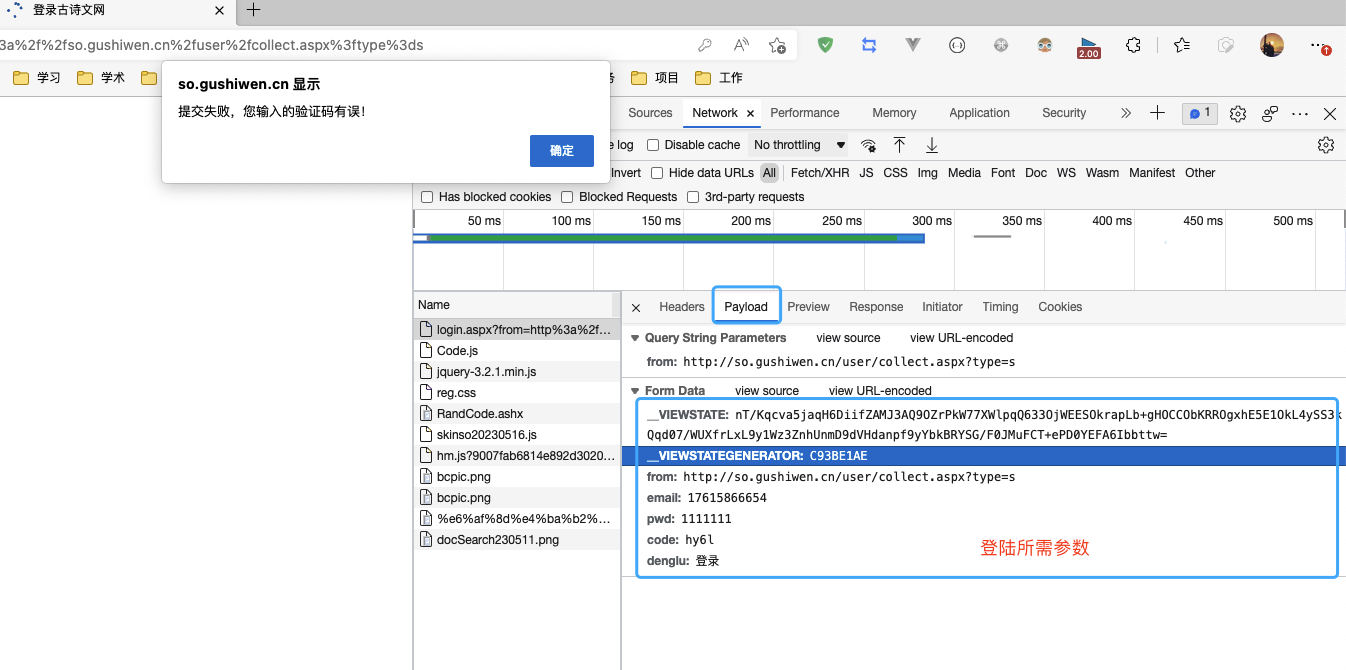
难点:登陆有随机验证码
__VIEWSTATE: nT/Kqcva5jaqH6DiifZAMJ3AQ9OZrPkW77XWlpqQ633OjWEESOkrapLb+gHOCCObKRROgxhE5E1OkL4ySS3kQqd07/WUXfrLxL9y1Wz3ZnhUnmD9dVHdanpf9yYbkBRYSG/F0JMuFCT+ePD0YEFA6Ibbttw=
__VIEWSTATEGENERATOR: C93BE1AE
from: http://so.gushiwen.cn/user/collect.aspx?type=s
email: 17615866654
pwd: 1111111
code: hy6l
denglu: 登录
重试几次错误密码登陆,抓接口发现:__VIEWSTATE和__VIEWSTATEGENERATOR和code是变量
结局方案:
(1)__VIEWSTATE和__VIEWSTATEGENERATOR:隐藏在在页面的源码中,所以我们需要获取页面的源码,然后进行解析就可以获取了
(2)随机验证码:下载验证码图片进行解析
'''
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx' # 登陆页面的路径
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 获取登陆页面的源码接口:get请求
response = requests.get(url=url, headers=headers)
content = response.text
# print(content)
# 解析网页源码,获取__VIEWSTATE和__VIEWSTATEGENERATOR的值
from bs4 import BeautifulSoup # 用xpath或者bs4都行
soup = BeautifulSoup(content, 'lxml')
VIEWSTATE = soup.select('#__VIEWSTATE')[0].attrs.get('value')
VIEWSTATEGENERATOR = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
print(VIEWSTATE)
print(VIEWSTATEGENERATOR)
# 获取验证码图片
code = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn' + code
# 下载验证码图片到本地,人工识别(此处可以替换为深度学习模型自动识别或者ocr)
# 下节课会讲"超级鹰"打码平台,接口自动识别验证码
# import urllib.request
# urllib.request.urlretrieve(url=code_url, filename='code.jpg')
# session = requests.session()
# 上面三行有坑。解决:requests里面有一个方法session() 通过session的返回值 就能使用请求变成一个对象
session = requests.session()
response_code = session.get(code_url) # 验证码的url的内容
# 注意此时要使用二进制数据 因为我们要使用的是图片的下载
content_code = response_code.content
# wb的模式就是将二进制数据写入到文件
with open('code.jpg', 'wb')as fp:
fp.write(content_code)
code_name = input('请输入你的验证码: ')
# 点击登陆接口:post请求
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data_post = {
'__VIEWSTATE': VIEWSTATE,
'__VIEWSTATEGENERATOR': VIEWSTATEGENERATOR,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '17615866666',
'pwd': '111', # 测试时填写正确密码
'code': code_name,
'denglu': '登录',
}
# response_post = requests.post(url=url_post, data=data_post, headers=headers)
response_post = session.post(url=url_post, data=data_post, headers=headers)
content_post = response_post.text
with open('./gushiwen.html', 'w', encoding='utf-8') as fp:
fp.write(content_post)
if __name__ == '__main__':
start = time.time()
print('It takes', time.time() - start, "seconds.")
6. "超级鹰"打码平台py-api
#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def PostPic_base64(self, base64_str, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
'file_base64':base64_str
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
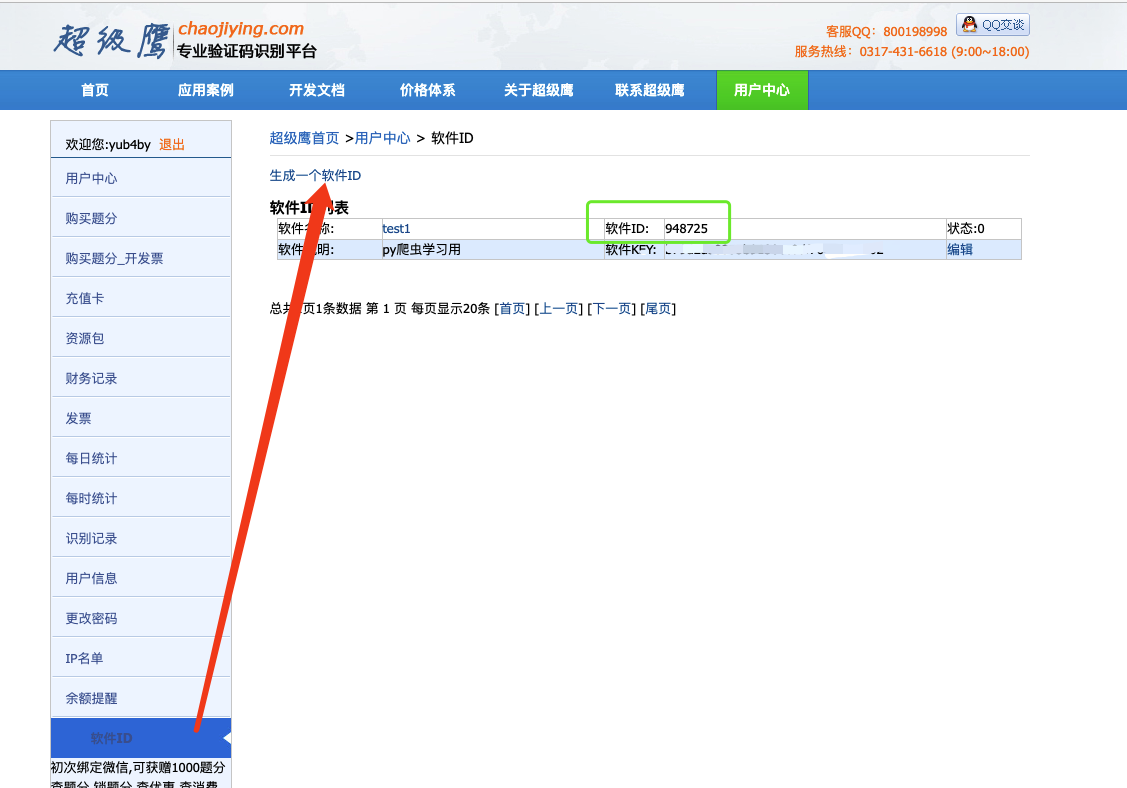
chaojiying = Chaojiying_Client('yub4by', '测试填正确密码', '948725') #用户中心>>软件ID 生成一个替换 96001
im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print(chaojiying.PostPic(im, 1902)) #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
print(chaojiying.PostPic(im, 1902).get('pic_str'))
#print chaojiying.PostPic(base64_str, 1902) #此处为传入 base64代码


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2021-05-21 JavaSE-6.2【基础知识练习案例*10】
2021-05-21 JavaSE-6.1【idea-debug使用及案例】
2021-05-21 JavaSE-5.4【案例:数组遍历、数组最值】
2021-05-21 JavaSE-5.3【方法的参数传递】
2021-05-21 JavaSE-5.2【方法重载案例】
2021-05-21 JavaSE-5.1【方法/函数:定义和调用、有参无参、有返无返、重载、参数传递】
2021-05-21 JavaSE-4.2【数组静态初始化、数组常见异常、数组遍历及应用】