客户端模拟: selenium等
1. 为什么要学习selenium
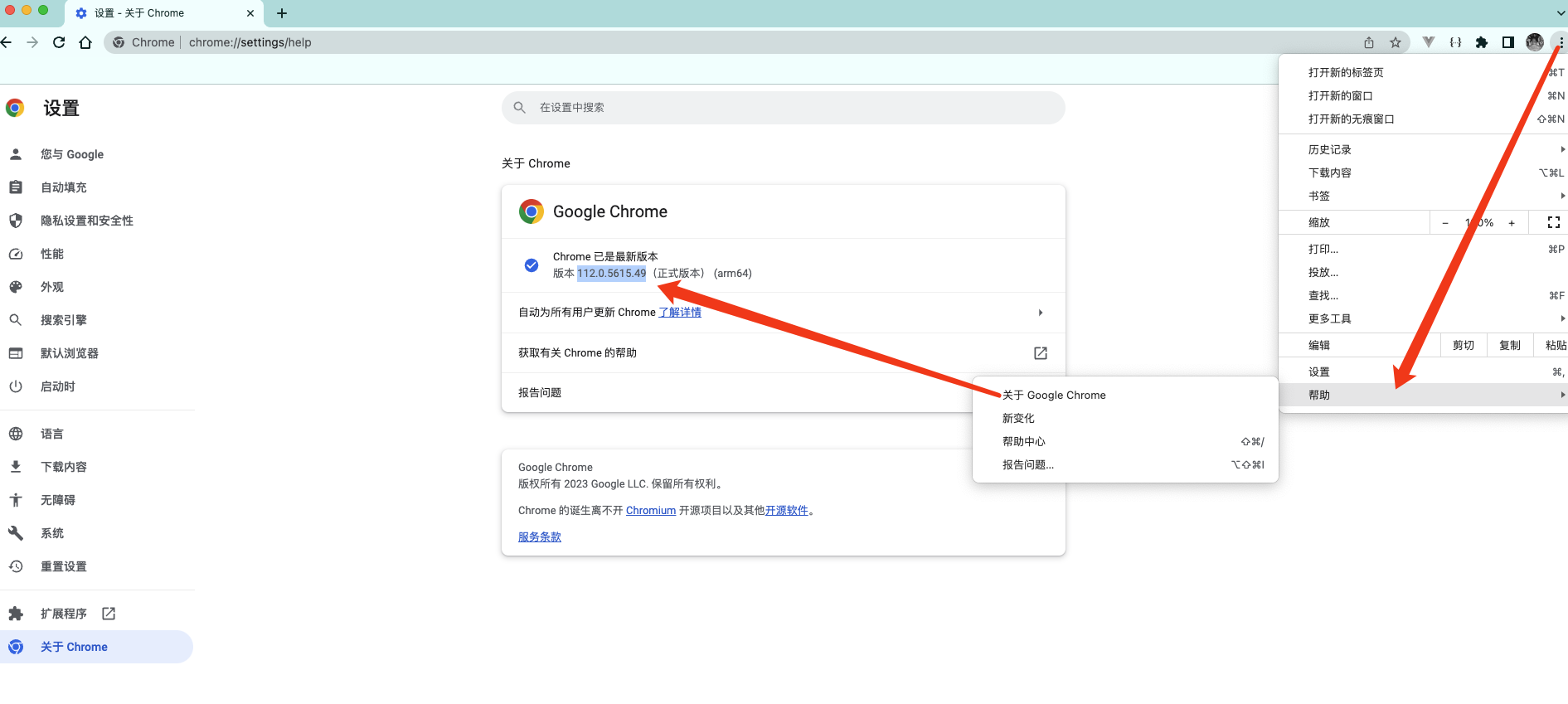
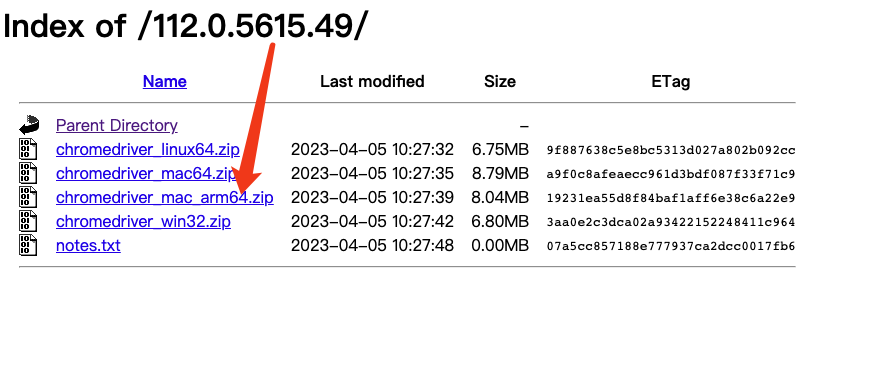
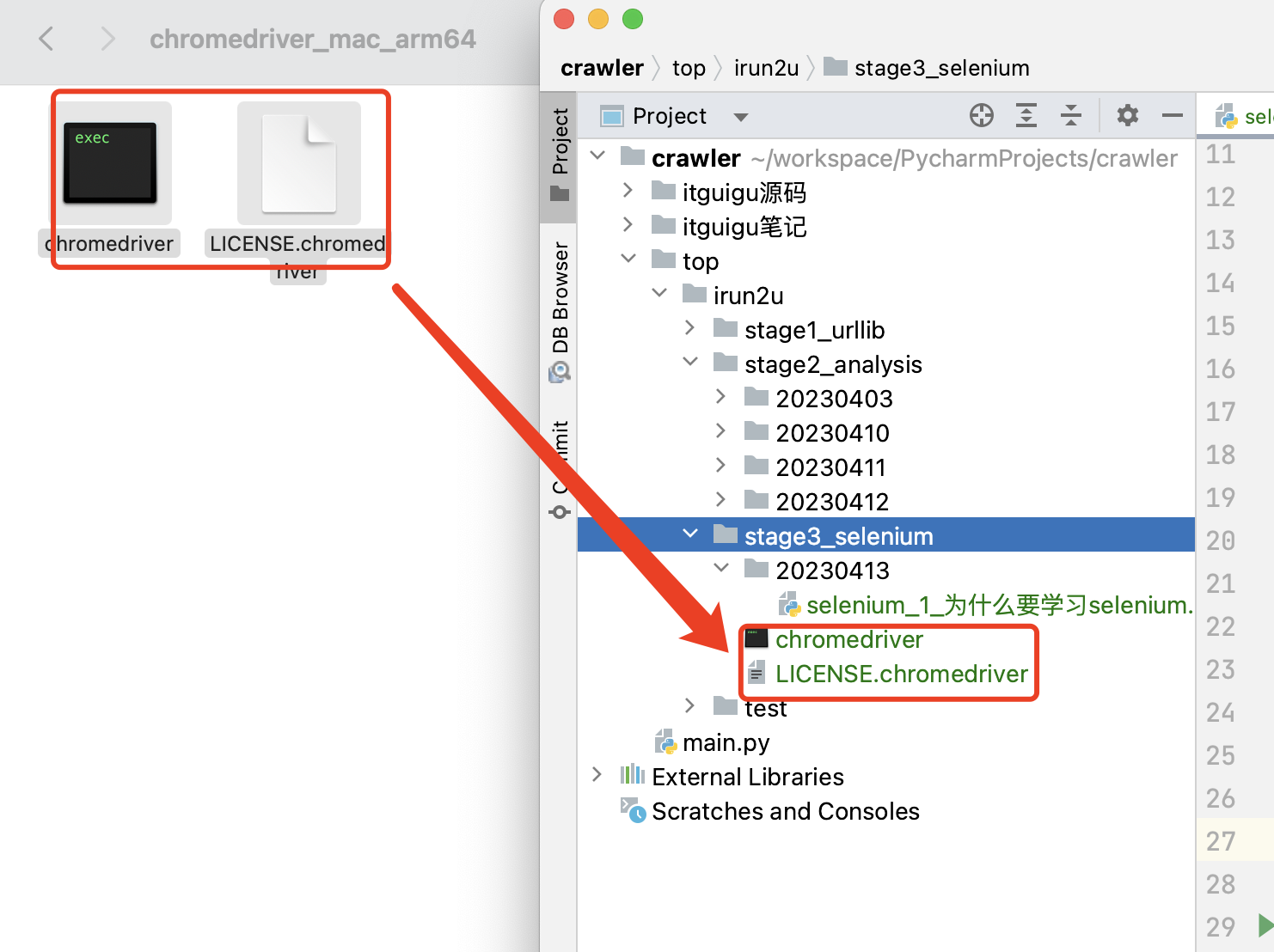
2. 安装selenium

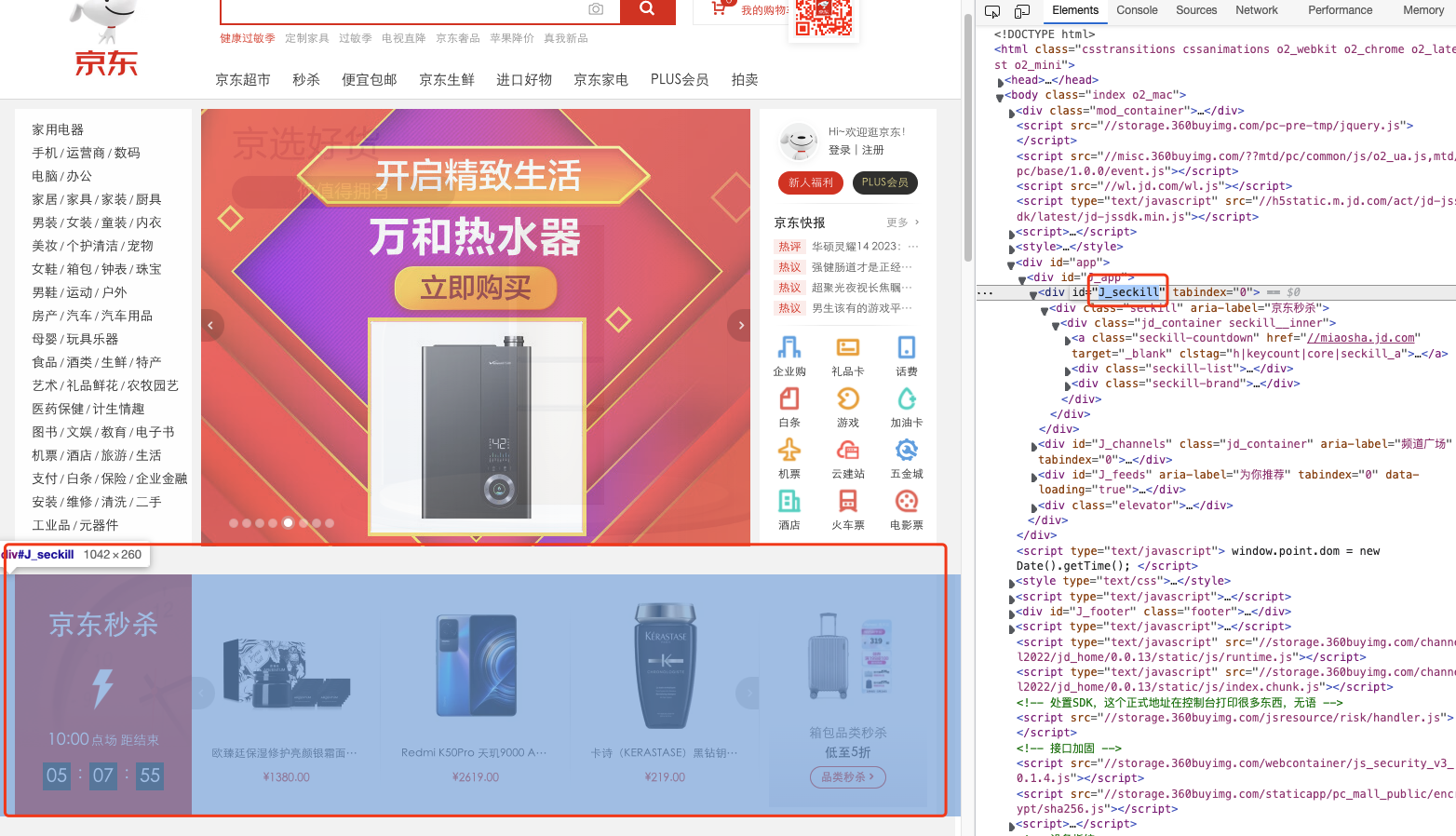
3. selenium使用
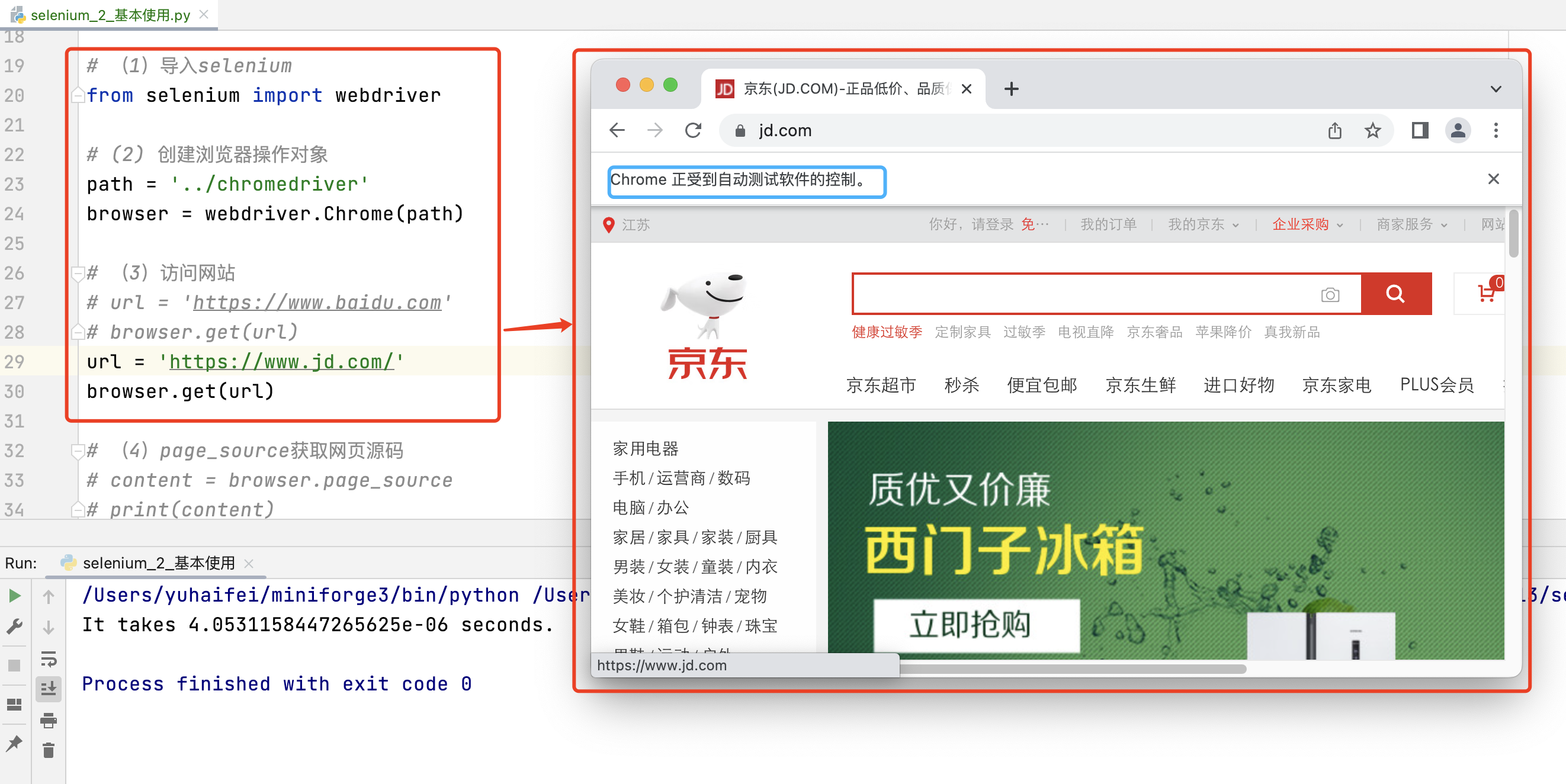
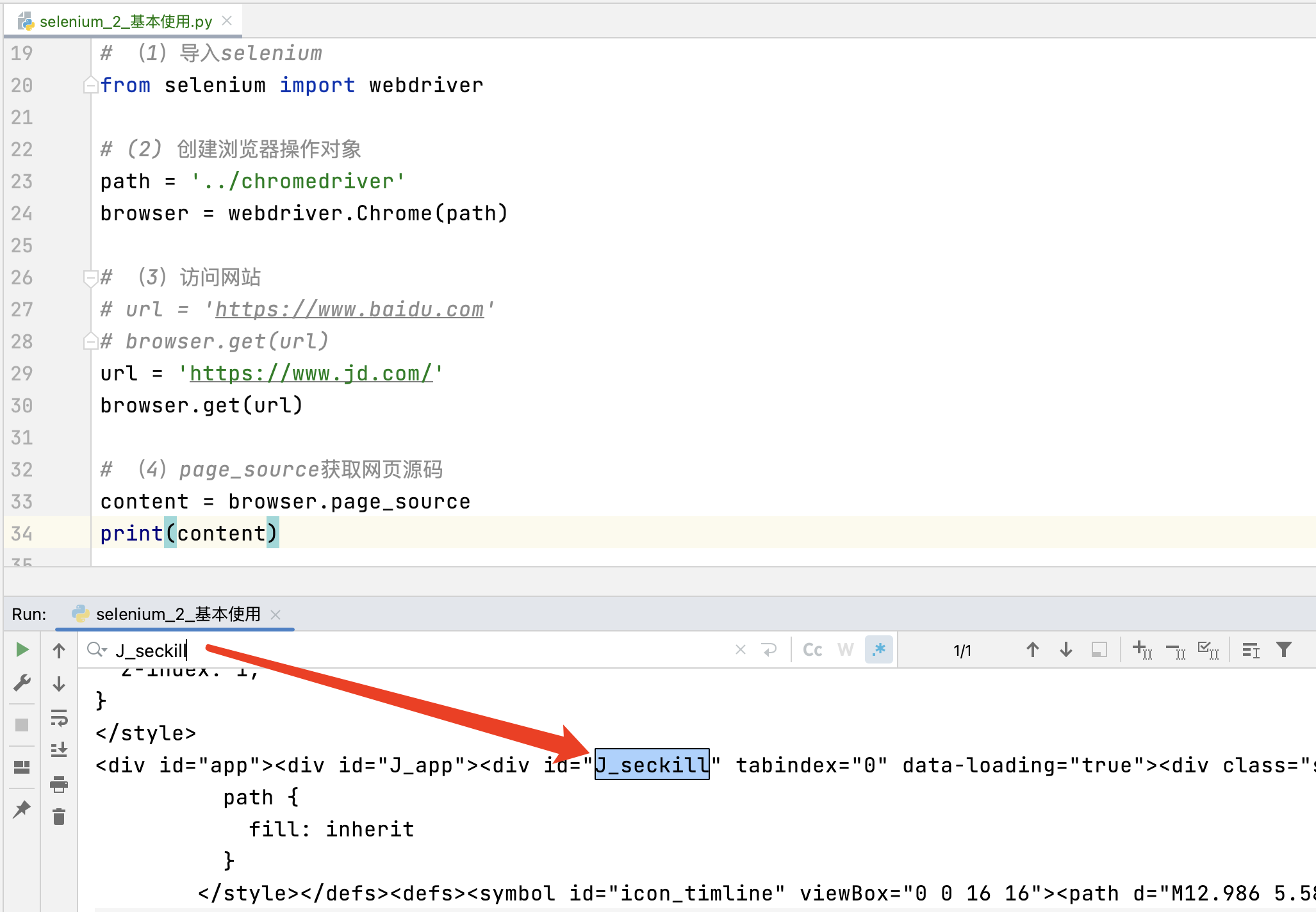
3.1 基本使用
"""
.-''-.
.--. _..._ .' .-. )
|__| .' '. / .' / /
.--..-,.--. . .-. . (_/ / /
| || .-. | | ' ' | / /
| || | | | _ _ | | | | / / _ _
| || | | || ' / | | | | | . ' | ' / |
| || | '-.' | .' | | | | | / / _.-').' | .' |
|__|| | / | / | | | | | .' ' _.'.-'' / | / |
| | | `'. | | | | | / /.-'_.' | `'. |
|_| ' .'| '/| | | | / _.' ' .'| '/
`-' `--' '--' '--'( _.-' `-' `--'
Created on 2023/4/13 21:37.
@Author: haifei
"""
import time
# (1)导入selenium
from selenium import webdriver
# (2) 创建浏览器操作对象
path = '../chromedriver'
browser = webdriver.Chrome(path)
# (3)访问网站
# url = 'https://www.baidu.com'
# browser.get(url)
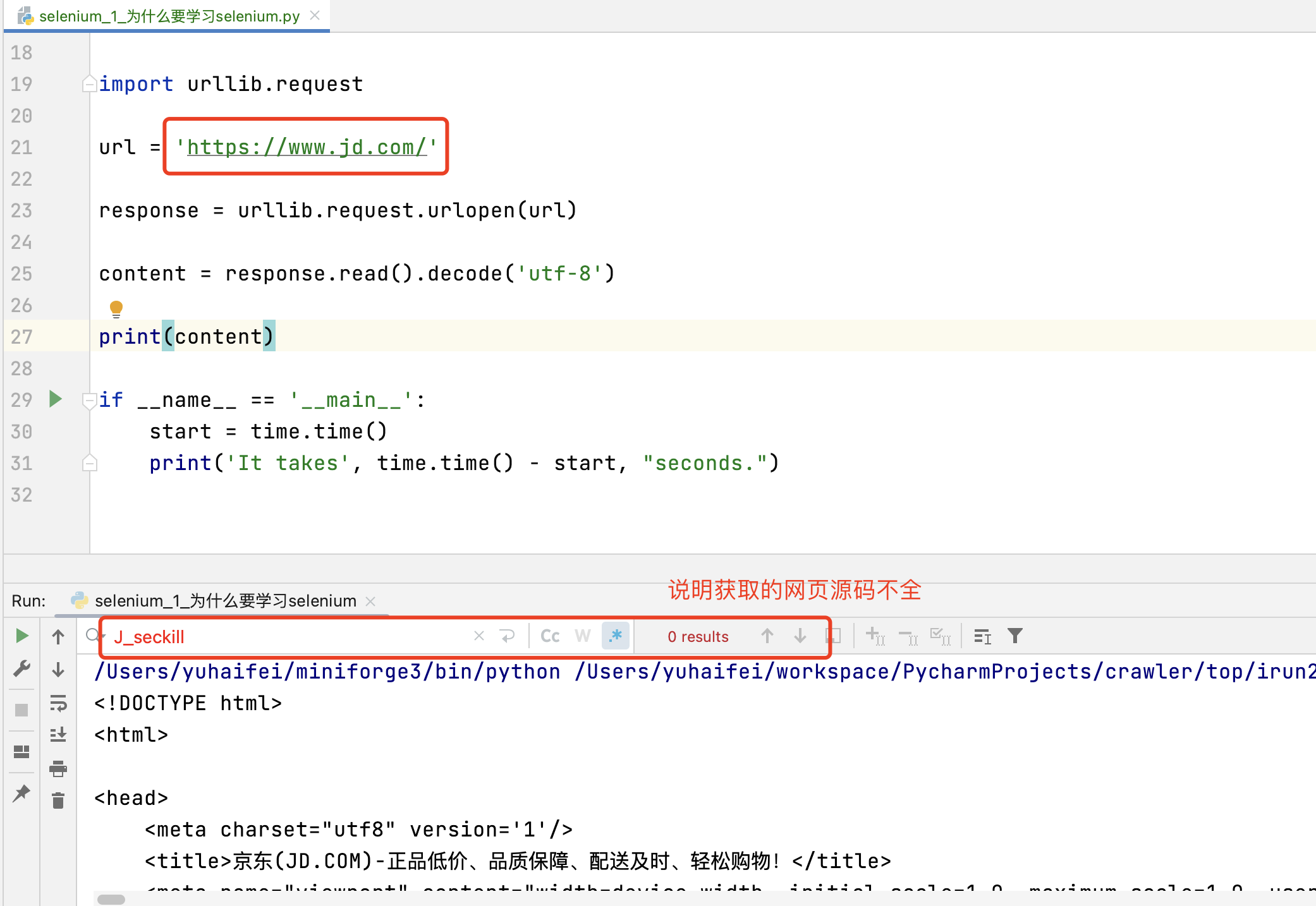
url = 'https://www.jd.com/'
browser.get(url)
# (4)page_source获取网页源码
content = browser.page_source
print(content)
if __name__ == '__main__':
start = time.time()
print('It takes', time.time() - start, "seconds.")
3.2 元素定位
"""
.-''-.
.--. _..._ .' .-. )
|__| .' '. / .' / /
.--..-,.--. . .-. . (_/ / /
| || .-. | | ' ' | / /
| || | | | _ _ | | | | / / _ _
| || | | || ' / | | | | | . ' | ' / |
| || | '-.' | .' | | | | | / / _.-').' | .' |
|__|| | / | / | | | | | .' ' _.'.-'' / | / |
| | | `'. | | | | | / /.-'_.' | `'. |
|_| ' .'| '/| | | | / _.' ' .'| '/
`-' `--' '--' '--'( _.-' `-' `--'
Created on 2023/4/13 21:45.
@Author: haifei
"""
import time
from selenium import webdriver
path = '../chromedriver'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
# 元素定位
# 根据id来找到对象
button = browser.find_element_by_id('su')
print(button)
# 根据标签属性的属性值来获取对象的
button = browser.find_element_by_name('wd')
print(button)
# 根据xpath语句来获取对象
# button = browser.find_element_by_xpath('//input[@id="su"]') # 单个结果
button = browser.find_elements_by_xpath('//input[@id="su"]') # 多个结果,返回列表
print(button)
# 根据标签的名字来获取对象
# button = browser.find_element_by_tag_name('input')
button = browser.find_elements_by_tag_name('input')
print(button)
# 使用的bs4的语法来获取对象
# button = browser.find_element_by_css_selector('#su')
button = browser.find_elements_by_css_selector('#su')
print(button)
# 获取为链接文本的对象
button = browser.find_element_by_link_text('贴吧')
# button = browser.find_elements_by_link_text('贴吧')
print(button)
if __name__ == '__main__':
start = time.time()
print('It takes', time.time() - start, "seconds.")
3.3 元素信息获取
"""
.-''-.
.--. _..._ .' .-. )
|__| .' '. / .' / /
.--..-,.--. . .-. . (_/ / /
| || .-. | | ' ' | / /
| || | | | _ _ | | | | / / _ _
| || | | || ' / | | | | | . ' | ' / |
| || | '-.' | .' | | | | | / / _.-').' | .' |
|__|| | / | / | | | | | .' ' _.'.-'' / | / |
| | | `'. | | | | | / /.-'_.' | `'. |
|_| ' .'| '/| | | | / _.' ' .'| '/
`-' `--' '--' '--'( _.-' `-' `--'
Created on 2023/4/13 21:56.
@Author: haifei
"""
import time
from selenium import webdriver
path = '../chromedriver'
browser = webdriver.Chrome(path)
url = 'http://www.baidu.com'
browser.get(url)
# 获取"百度一下"按钮
input = browser.find_element_by_id('su')
# 获取标签的属性
print(input.get_attribute('class')) # bg s_btn
# 获取标签的名字
print(input.tag_name) # input
# 获取[标签夹着的]元素文本
a = browser.find_element_by_link_text('新闻') # 新闻
print(a.text)
if __name__ == '__main__':
start = time.time()
print('It takes', time.time() - start, "seconds.")
3.4 自动交互案例
"""
.-''-.
.--. _..._ .' .-. )
|__| .' '. / .' / /
.--..-,.--. . .-. . (_/ / /
| || .-. | | ' ' | / /
| || | | | _ _ | | | | / / _ _
| || | | || ' / | | | | | . ' | ' / |
| || | '-.' | .' | | | | | / / _.-').' | .' |
|__|| | / | / | | | | | .' ' _.'.-'' / | / |
| | | `'. | | | | | / /.-'_.' | `'. |
|_| ' .'| '/| | | | / _.' ' .'| '/
`-' `--' '--' '--'( _.-' `-' `--'
Created on 2023/4/13 22:04.
@Author: haifei
"""
import time
from selenium import webdriver
'''
适用场景:西瓜视频官网 瀑布式异步刷新 下滑自动请求更多视频(无需点击下一页)
案例效果:模拟人工在浏览器百度搜索"周杰伦",并浏览到下一页,最后返回上页并退出浏览器
'''
path = '../chromedriver'
browser = webdriver.Chrome(path)
url = 'http://www.baidu.com'
browser.get(url)
time.sleep(2) # 延迟两秒
# 获取文本框的对象
input = browser.find_element_by_id('kw')
# 在文本框中输入周杰伦
input.send_keys('周杰伦')
time.sleep(2)
# 获取百度一下的按钮
button = browser.find_element_by_id('su')
# 点击按钮
button.click()
time.sleep(2)
# 滑到底部
js_bottom = 'document.documentElement.scrollTop=100000' # 固定写法
browser.execute_script(js_bottom)
time.sleep(2)
# 获取下一页的按钮
next = browser.find_element_by_xpath('//a[@class="n"]') # 可以先用xpath去页面查一下,确定该按钮在当前页面中的唯一性
# 点击下一页
next.click()
time.sleep(2)
# 回到上一页
browser.back() # 后退
time.sleep(2)
browser.forward() # 前进
time.sleep(3)
# 退出,自动关闭浏览器
browser.quit()
if __name__ == '__main__':
start = time.time()
print('It takes', time.time() - start, "seconds.")
4. Phantomjs
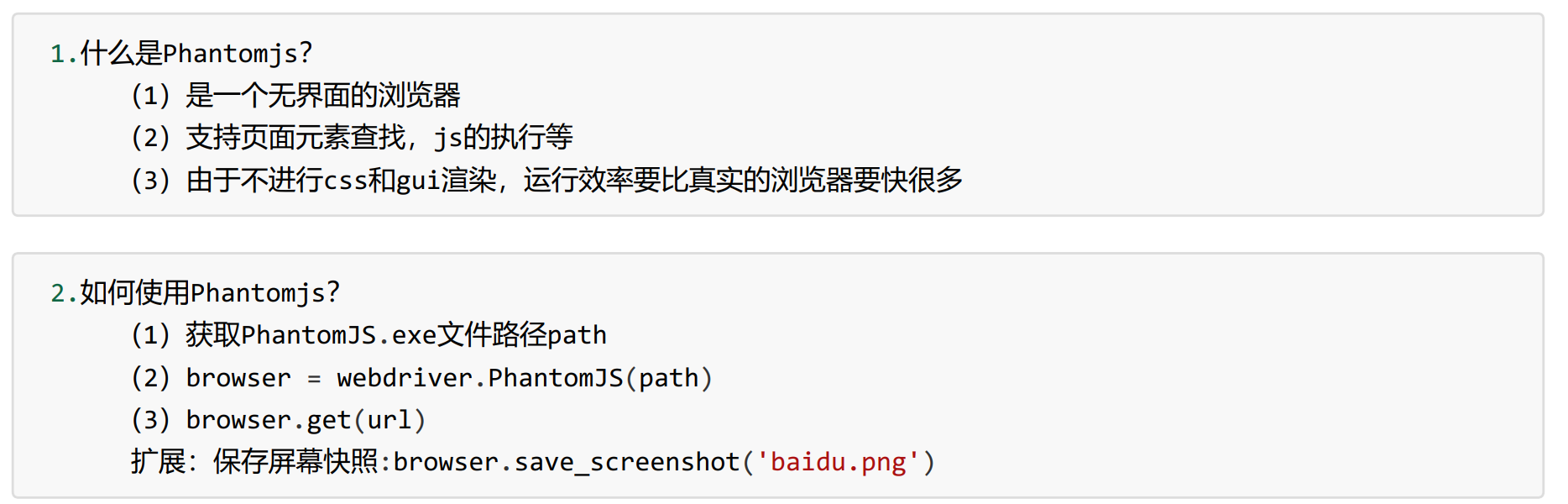
5. Chrome handless



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2022-04-13 HM-SpringCloud微服务系列9.4【高可用】
2022-04-13 HM-SpringCloud微服务系列9.3.2【实践:TCC模式、SAGA模式】