解析_1_xpath基本使用
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
<body>
<ul>
<li id="l1" class="c1">北京</li>
<li id="2l">上海</li>
<li >深圳</li>
<li >武汉</li>
</ul>
<ul>
<li id="i1" class="c1">大连</li>
<li class="c2">锦州</li>
<li>沈阳</li>
</ul>
</body>
</html>
"""
.-''-.
.--. _..._ .' .-. )
|__| .' '. / .' / /
.--..-,.--. . .-. . (_/ / /
| || .-. | | ' ' | / /
| || | | | _ _ | | | | / / _ _
| || | | || ' / | | | | | . ' | ' / |
| || | '-.' | .' | | | | | / / _.-').' | .' |
|__|| | / | / | | | | | .' ' _.'.-'' / | / |
| | | `'. | | | | | / /.-'_.' | `'. |
|_| ' .'| '/| | | | / _.' ' .'| '/
`-' `--' '--' '--'( _.-' `-' `--'
Created on 2023/4/3 21:38.
@Author: haifei
"""
import time
from lxml import etree
'''
xpath解析两种方式
1、本地文件
etree.parse
2、服务器响应的数据(response.read().decode('utf-8')) <---主用
etree.HTML()
xpath基本语法:
1.路径查询
//:查找所有子孙节点,不考虑层级关系
/ :找直接子节点
2.谓词查询
//div[@id]
//div[@id="maincontent"]
3.属性查询
//@class
4.模糊查询
//div[contains(@id, "he")]
//div[starts‐with(@id, "he")]
5.内容查询
//div/h1/text()
6.逻辑运算(用的情况比较少)
//div[@id="head" and @class="s_down"]
//title | //price
'''
tree = etree.parse('./解析_1_xpath基本使用.html')
print(tree)
li_list = tree.xpath('//body/ul/li')
print(li_list)
print(len(li_list))
li_list2 = tree.xpath('//body//li')
print(li_list2)
print(len(li_list2))
li_list = tree.xpath('//li[@id]')
print(li_list)
print(len(li_list))
li_list = tree.xpath('//li[@id]/text()')
print(li_list)
li_list = tree.xpath('//li[@id="l1"]/text()')
print(li_list)
li = tree.xpath('//li[@id="l1"]/@class')
print(li)
li_list = tree.xpath('//li[contains(@id,"l")]/text()')
print(li_list)
li_list = tree.xpath('//li[starts-with(@id,"i")]/text()')
print(li_list)
li_list = tree.xpath('//li[@id="l1" and @class="c1"]/text()')
print(li_list)
li_list = tree.xpath('//li[@id="l1"]/text() | //li[@class="c2"]/text()')
print(li_list)
if __name__ == '__main__':
start = time.time()
print('It takes', time.time() - start, "seconds.")
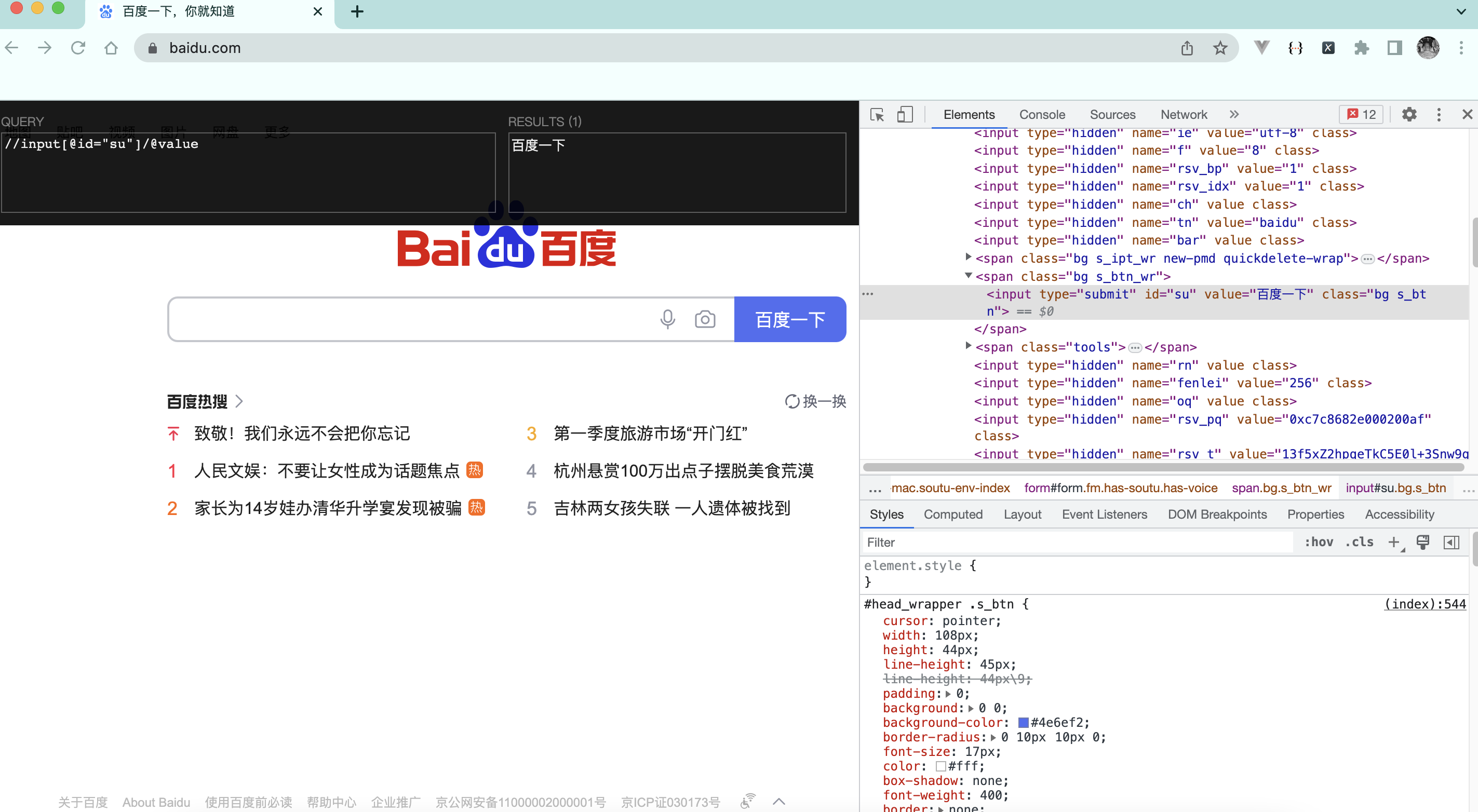
解析_2_获取百度首页百度一下四个大字
"""
.-''-.
.--. _..._ .' .-. )
|__| .' '. / .' / /
.--..-,.--. . .-. . (_/ / /
| || .-. | | ' ' | / /
| || | | | _ _ | | | | / / _ _
| || | | || ' / | | | | | . ' | ' / |
| || | '-.' | .' | | | | | / / _.-').' | .' |
|__|| | / | / | | | | | .' ' _.'.-'' / | / |
| | | `'. | | | | | / /.-'_.' | `'. |
|_| ' .'| '/| | | | / _.' ' .'| '/
`-' `--' '--' '--'( _.-' `-' `--'
Created on 2023/4/3 22:40.
@Author: haifei
"""
import time
from lxml import etree
from urllib import request
url = 'https://www.baidu.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
_request = request.Request(url=url, headers=headers)
response = request.urlopen(_request)
content = response.read().decode('utf-8')
tree = etree.HTML(content)
print(tree.xpath('//input[@id="su"]/@value'))
result = tree.xpath('//input[@id="su"]/@value')[0]
print(result)
if __name__ == '__main__':
start = time.time()
print('It takes', time.time() - start, "seconds.")


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!