浅用chatgpt
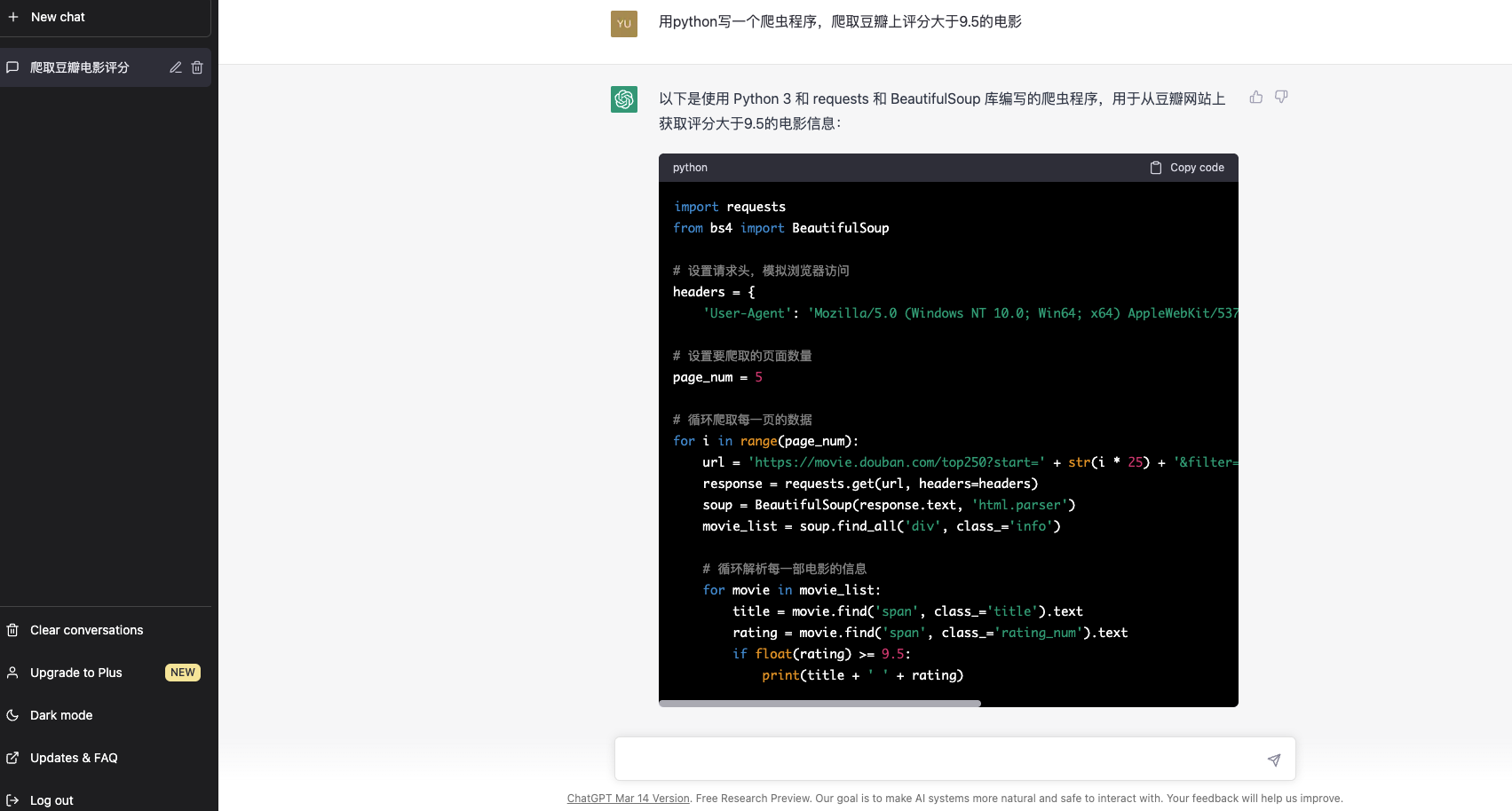
import requests
from bs4 import BeautifulSoup
# 设置请求头,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
# 设置要爬取的页面数量
page_num = 5
# 循环爬取每一页的数据
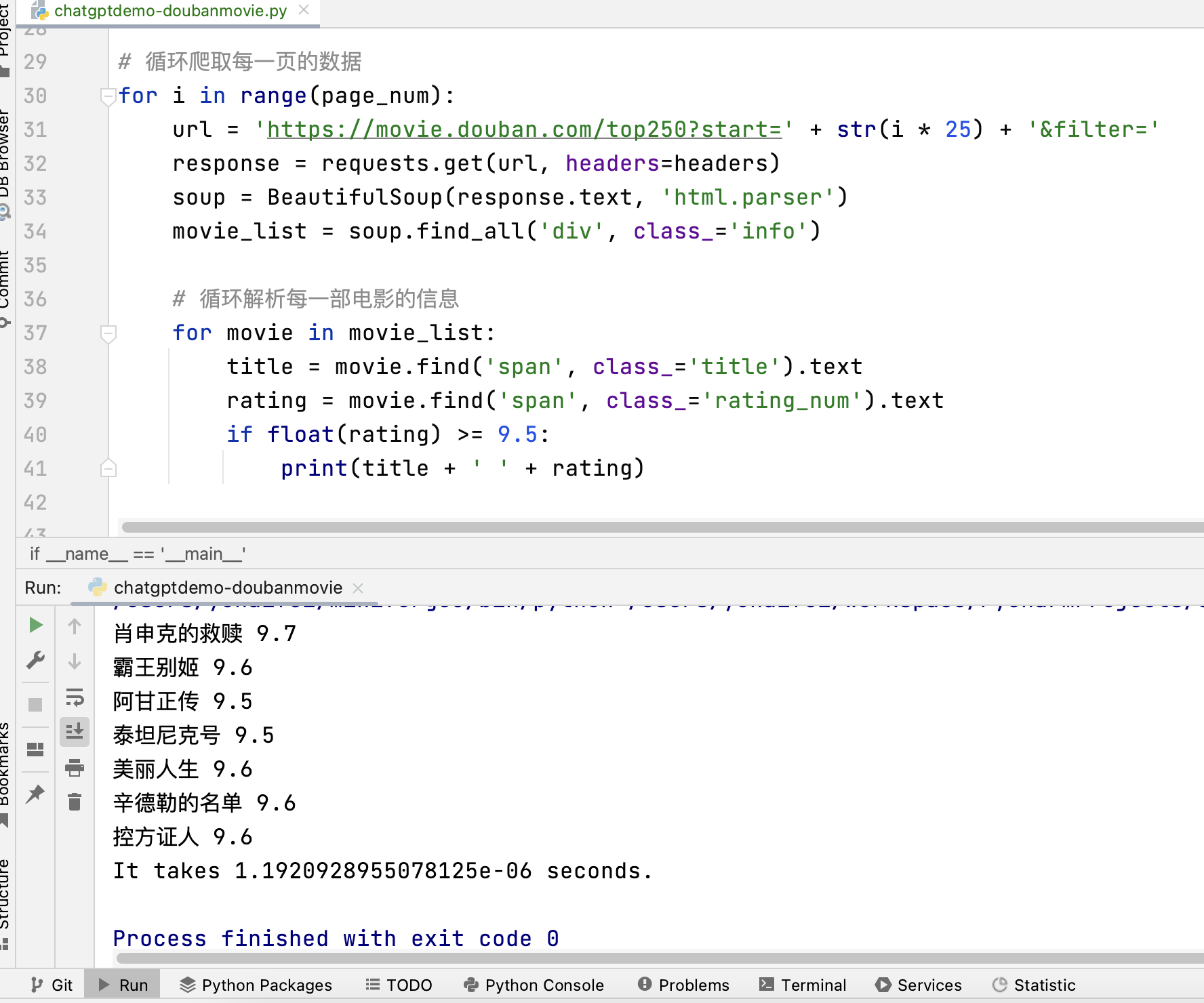
for i in range(page_num):
url = 'https://movie.douban.com/top250?start=' + str(i * 25) + '&filter='
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
movie_list = soup.find_all('div', class_='info')
# 循环解析每一部电影的信息
for movie in movie_list:
title = movie.find('span', class_='title').text
rating = movie.find('span', class_='rating_num').text
if float(rating) >= 9.5:
print(title + ' ' + rating)





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2022-03-27 HM-SpringCloud微服务系列6.2【搜索结果处理】