
前端开发需要了解的浏览器通识
浏览器通识
一、浏览器架构
1、单进程浏览器时代
2007年之前,市面上浏览器都是单进程的,在同一个进程里会存在网络、插件、JavaScript运行环境、渲染引擎和页面等。
缺点
- 不稳定:一个节点崩溃,整个浏览器崩溃
- 不流畅:运行在同一个线程,需要重上到下一次完成
- 不安全:通过浏览器的漏洞来获取系统权限,可以对你的电脑做一些恶意的事情
2、多进程浏览器时代
新的Chrome浏览器包括:
- 1个浏览器(Browser)主进程:界面显示、用户交互、子进程管理,同时提供存储等功能
- 1个 GPU 进程:UI界面都选择采用GPU来绘制
- 1个网络(NetWork)进程:网络资源加载
- 多个渲染进程:将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页
- 多个插件进程:负责插件的运行
浏览器是多进程的优点 - 一个页面崩溃不会影响到整个浏览器
- 多进程可以充分利用现代 CPU 多核的优势。
- 方便使用沙盒模型隔离插件等进程,提高浏览器的稳定性。
3、Chrome 打开一个页面需要启动多少进程?分别有哪些进程?
- 打开 1 个页面至少需要 1 个网络进程、1 个浏览器进程、1 个 GPU 进程以及 1 个渲染进程,共 4 个;
- 最新的 Chrome 浏览器包括:1 个浏览器(Browser)主进程、1 个 GPU 进程、1 个网络(NetWork)进程、多个渲染进程和多个插件进程。
二、javascript单线程
1、为什么采用单线程
主要用途是与用户互动,以及操作DOM。如果JavaScript是多线程的,会带来很多复杂的问题。
Web Worker:为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行。但是子线程完全受主线程控制,且不得操作DOM
2、浏览器内核中线程之间的关系
- GUI渲染线程和JS引擎线程互斥
- JS阻塞页面加载:js如果执行时间过长就会阻塞页面
3、进程和线程又是什么呢
进程:是 CPU 资源分配的最小单位(是能拥有资源和独立运行的最小单位)。
线程:是 CPU 调度的最小单位(是建立在进程基础上的一次程序运行单位)。
4、任务队列
JS 是单线程的,同步执行任务会造成浏览器的阻塞,所以我们将 JS 分成一个又一个的任务,通过不停的循环来执行事件队列中的任务。
- 单线程就意味着,所有任务都要排队执行,前一个任务结束,才会执行后一个任务。
- 如果当前线程空闲,并且队列为空,那每次加入队列的函数将立即执行。
三、渲染机制
1. 浏览器如何渲染网页
浏览器渲染一共有五步
- 处理 HTML 并构建 DOM 树。
- 处理 CSS构建 CSSOM 树。
- 将 DOM 与 CSSOM 合并成一个渲染树。
- 根据渲染树来布局,计算每个节点的位置。
- 调用 GPU 绘制,合成图层,显示在屏幕上
第四步和第五步是最耗时的部分,这两步合起来,就是我们通常所说的渲染
- 在构建 CSSOM 树时,会阻塞渲染,直至 CSSOM树构建完成
- 当 HTML 解析到 script 标签时,会暂停构建 DOM,完成后才会从暂停的地方重新开始
四、缓存机制
1、常见 http 缓存的类型
- 私有/浏览器/本地缓存
- 代理缓存
2、缓存的好处
- 减少了冗余的数据传输,减少网费
- 减少服务器端的压力
W3. eb 缓存能够减少延迟与网络阻塞,进而减少显示某个资源所用的时间 - 加快客户端加载网页的速度
3、浏览器缓存总结
浏览器缓存分为强缓存和协商缓存。
强缓存
对一个网站而言,CSS、JavaScript、图片等静态资源更新的频率都比较低,而这些文件又几乎是每次HTTP请求都需要的,如果将这些文件缓存在浏览器中,可以极好的改善性能。
通过设置http头中的cache-control和expires的属性,可设定浏览器缓存,将静态内容设为永不过期,或者很长时间后才过期。
1、Cache-Control
Cache-Control属性是在服务器端配置的,不同的服务器有不同的配置,apache、nginx、IIS、tomcat等配置都不尽相同。
以Apache为例,在http.conf中做如下配置:
<filesMatch ”.(jpg|jpeg|png|gif|ico)$”>
Header set Cache Control max-age=16768000,public
</filesMatch>
<filesMatch ”.(css|js)$”>
Header set Cache Control max-age=2628000,public
</filesMatch>
问题:浏览器缓存的资源,若又想更新资源,如何实现?
解决:通过修改该资源的名称来实现。修改了资源名称,浏览器会当做不同的资源。
Cache-Control相关属性
no-cache:不使用本地缓存。
no-store:直接禁止游览器缓存数据,
public:可以被所有的用户缓存,
private:只能被终端用户的浏览器缓存,
max-age:从当前请求开始,
must-revalidate,当缓存过期时,
2、Expires
Expires属性也是在服务端配置的,具体的配置也根据服务器而定。
问题:可能存在客户端时间跟服务端时间不一致的问题。
解决:建议Expires结合Cache-Control一起使用。
Cache-Control: public
Expires: Wed, Jan 10 2018 00:27:04 GMT
过程
- 第一次浏览器发送请求给服务器时,此时浏览器还没有本地缓存副本,服务器返回资源给浏览器,响应码是200 OK,浏览器收到资源后,把资源和对应的响应头一起缓存下来
- 第二次浏览器准备发送请求给服务器时候,浏览器会先检查上一次服务端返回的响应头信息中的Cache-Control,它的值是一个相对值,单位为秒,表示资源在客户端缓存的最大有效期,过期时间为第一次请求的时间减去Cache-Control的值,过期时间跟当前的请求时间比较,如果本地缓存资源没过期,那么命中缓存,不再请求服务器
- 如果没有命中,浏览器就会把请求发送给服务器,进入缓存协商阶段。
协商缓存
览器在第一次访问页面时向服务器请求资源,并缓存起来,下次再访问时会判断在缓存中是否已有该资源且有没有更新过,如果已有该资源且未更新过,则直接从浏览器缓存中读取。
原理:
通过HTTP 请求头中的 If-Modified-Since(If-No-Match) 和响应头中的Last-Modified(ETag)来实现
HTTP请求把 If-Modified-Since(If-No-Match)传给服务器
服务器将其与Last-Modified(ETag)对比,若相同,则文件没有被改动过,则返回304,直接浏览器缓存中读取资源即可。
缓存位置
- Service Worker
- Memory Cache
- Disk Cache
- Push Cache
Service Worker
离线缓存: 这个应用场景比如PWA,它借鉴了Web Worker思路,由于它脱离了浏览器的窗体,因此无法直接访问DOM。它能完成的功能比如:离线缓存、消息推送和网络代理,其中离线缓存就是Service Worker Cache。
Memory Cache
内存缓存:从效率上讲它是最快的,从存活时间来讲又是最短的,当渲染进程结束后,内存缓存也就不存在了。
Disk Cache
存储在磁盘中的缓存:从存取效率上讲是比内存缓存慢的,优势在于存储容量和存储时长。
Push Cache
推送缓存:这算是浏览器中最后一道防线吧,它是HTTP/2的内容
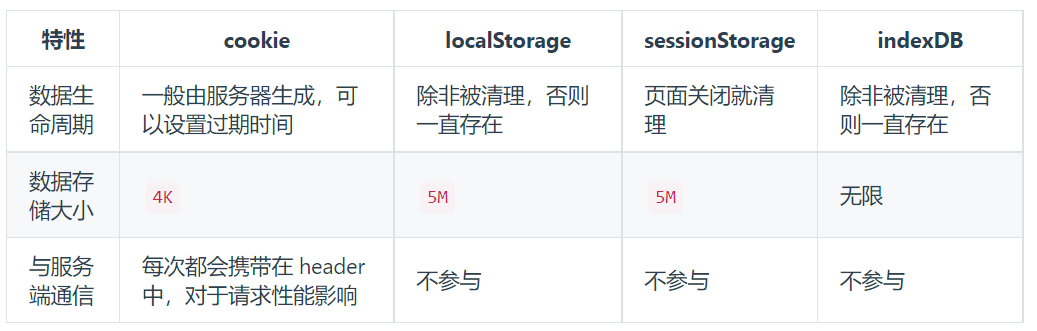
六、浏览器存储
- 短暂性存储:我们只需要将数据存在内存中,只在运行时可用
- 持久性存储:可以分为 浏览器端 与 服务器端
- 浏览器:
- cookie: 通常用于存储用户身份,登录状态等
- localStorage / sessionStorage: 长久储存/窗口关闭删除, 体积限制为 4~5M
- indexDB:浏览器提供的本地数据库
- 服务器:
- 分布式缓存 redis
- 数据库
- 浏览器:
存储大小:
cookie数据大小不能超过4k
sessionStorage和localStorage虽然也有存储大小的限制,但比cookie大得多,可以达到5M或更大
有效期时间:
localStorage 存储持久数据,浏览器关闭后数据不丢失除非主动删除数据
sessionStorage 数据在当前浏览器窗口关闭后自动删除
cookie 设置的cookie过期时间之前一直有效,即使窗口或浏览器关闭
七、跨域处理方案
八、安全
九、PWA渐进式web应用--离线存储
十、DOM节点操作
JavaScript之BOM和DOM及其兼容操作详细总结
(1)创建新节点
createDocumentFragment() //创建一个DOM片段
createElement() //创建一个具体的元素
createTextNode() //创建一个文本节点
(2)添加、移除、替换、插入
appendChild(node)
removeChild(node)
replaceChild(new,old)
insertBefore(new,old)
(3)查找
getElementById();
getElementsByName();
getElementsByTagName();
getElementsByClassName();
querySelector();
querySelectorAll();
(4)属性操作
getAttribute(key);
setAttribute(key, value);
hasAttribute(key);
removeAttribute(key);
十一、页面加载过程
-
当我们打开网址的时候,浏览器会从服务器中获取到 HTML 内容
-
浏览器获取到 HTML 内容后,就开始从上到下解析 HTML 的元素
-
<head>元素内容会先被解析,此时浏览器还没开始渲染页面 -
当浏览器解析到这里时(步骤 3),会暂停解析并下载 JavaScript 脚本
-
当 JavaScript 脚本下载完成后,浏览器的控制权转交给 JavaScript 引擎。当脚本执行完成后,控制权会交回给渲染引擎,渲染引擎继续往下解析 HTML 页面
-
此时
<body>元素内容开始被解析,浏览器开始渲染页面]
js延迟加载的方式有哪些
- 将 js 脚本放在文档的底部,来使 js 脚本尽可能的在最后来加载执行
- 给 js 脚本添加 defer 属性,这个属性会让脚本的加载与文档的解析同步解析,然后在文档解析完成后再执行这个脚本文件,这样的话就能使页面的渲染不被阻塞。多个设置了 defer 属性的脚本按规范来说最后是顺序执行的,但是在一些浏览器中可能不是这样
- 给 js 脚本添加 async属性,这个属性会使脚本异步加载,不会阻塞页面的解析过程,但是当脚本加载完成后立即执行 js脚本,这个时候如果文档没有解析完成的话同样会阻塞。多个 async 属性的脚本的执行顺序是不可预测的,一般不会按照代码的顺序依次执行
- 动态创建 DOM 标签的方式,我们可以对文档的加载事件进行监听,当文档加载完成后再动态的创建 script 标签来引入 js 脚本

十二、输入url到展示过程
基础版本
- 浏览器根据请求的URL交给DNS域名解析,找到真实IP,向服务器发起请求;
- 服务器交给后台处理完成后返回数据,浏览器接收文件(HTML、JS、CSS、图象等);
- 浏览器对加载到的资源(HTML、JS、CSS等)进行语法解析,建立相应的内部数据结构(如HTML的DOM);
- 载入解析到的资源文件,渲染页面,完成。
-
从浏览器接收url到开启网络请求线程(这一部分可以展开浏览器的机制以及进程与线程之间的关系)
-
开启网络线程到发出一个完整的HTTP请求(这一部分涉及到dns查询,TCP/IP请求,五层因特网协议栈等知识)
-
从服务器接收到请求到对应后台接收到请求(这一部分可能涉及到负载均衡,安全拦截以及后台内部的处理等等)
-
后台和前台的HTTP交互(这一部分包括HTTP头部、响应码、报文结构、cookie等知识,可以提下静态资源的cookie优化,以及编码解码,如gzip压缩等)
-
单独拎出来的缓存问题,HTTP的缓存(这部分包括http缓存头部,ETag,catch-control等)
-
浏览器接收到HTTP数据包后的解析流程(解析html-词法分析然后解析成dom树、解析css生成css规则树、合并成render树,然后layout、painting渲染、复合图层的合成、GPU绘制、外链资源的处理、loaded和DOMContentLoaded等)
-
CSS的可视化格式模型(元素的渲染规则,如包含块,控制框,BFC,IFC等概念)
-
JS引擎解析过程(JS的解释阶段,预处理阶段,执行阶段生成执行上下文,VO,作用域链、回收机制等等)
-
其它(可以拓展不同的知识模块,如跨域,web安全,hybrid模式等等内容)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号