scrapy是广度优先还是深度优先?
深度优先是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续追踪链接
广度优先,有人也叫宽度优先,是指将新下载网页发现的链接直接插入到待抓取URL队列的末尾,也就是指网络爬虫会先抓取起始页中的所有网页,然后在选择其中的一个连接网页,继续抓取在此网页中链接的所有网页
经过官方文档查询,因为scrapy使用的是后进先出队列,基本可以看成是深度优先(DFO)。如果需要设置广度优先(BFO),可以在settings中添加以下代码。另外当DEPTH_PRIORITY为正值时越靠广度优先,负值则越靠深度优先,默认值为0
广度优先,有人也叫宽度优先,是指将新下载网页发现的链接直接插入到待抓取URL队列的末尾,也就是指网络爬虫会先抓取起始页中的所有网页,然后在选择其中的一个连接网页,继续抓取在此网页中链接的所有网页
经过官方文档查询,因为scrapy使用的是后进先出队列,基本可以看成是深度优先(DFO)。如果需要设置广度优先(BFO),可以在settings中添加以下代码。另外当DEPTH_PRIORITY为正值时越靠广度优先,负值则越靠深度优先,默认值为0
以下设置Scrapy广度优先,爬取最新数据
# 爬虫允许的最大深度,可以通过meta查看当前深度;0表示无深度 DEPTH_LIMIT = 3 # 爬取时,0表示深度优先Lifo(默认);1表示广度优先FiFo # 后进先出,深度优先 # DEPTH_PRIORITY = 0 # SCHEDULER_DISK_QUEUE = 'scrapy.squeues.PickleLifoDiskQueue' # SCHEDULER_MEMORY_QUEUE = 'scrapy.squeues.LifoMemoryQueue' # 先进先出,广度优先 DEPTH_PRIORITY = 1 SCHEDULER_DISK_QUEUE = 'scrapy.squeues.PickleFifoDiskQueue' SCHEDULER_MEMORY_QUEUE = 'scrapy.squeues.FifoMemoryQueue'
Scrapy默认通过深度优先算法实现

深度优先输出:A、B、D、E、I、C、F、G、H(递归实现)
广度优先输出:A、B、C、D、E、F、G、H、I(队列实现)
# 深度优先算法实现 # 递归实现 def depth tree(tree_node): if tree_node is not None: print(tree_node._data) if tree_node.left is not None: return depth_tree(tree_node._left) if tree_node._right is not None: return depth_tree(tree_node._right)
# 广度优先算法实现 def level_queue(root): # 利用队列实现树的广度优先遍历 if root is None: return my_queue =[] node: root my_queue.append(node) while my_queue: node = my_queue.pop(0) print(node,elem) if node.lchild is not None: my_queue.append(node.lchild) if node.rchild is not None: my_queue.append(node.rchild)
scrapy 设置爬取深度
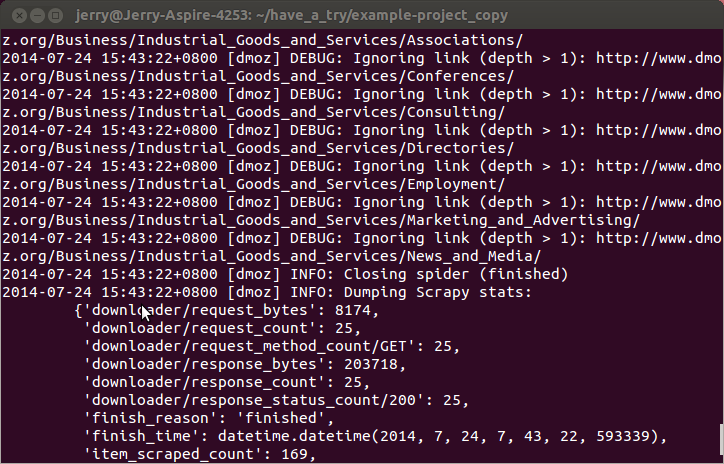
通过在settings.py中设置DEPTH_LIMIT的值可以限制爬取深度,这个深度是与start_urls中定义url的相对值。也就是相对url的深度。例如定义url为:http://www.domz.com/game/,DEPTH_LIMIT=1那么限制爬取的只能是此url下一级的网页。深度大于设置值的将被ignore。
如图: