

web端查看ES集群信息命令
在使用ES的过程中,我们时常要关注着集群的状态。
ES查看集群的状态实际上也是使用RESTful的接口,而且一般用的是GET方法,所以本文演示就直接用浏览器演示就好了。
curl和kibana下Dev tools的console方法都是一样的。
- crul
curl -X get [请求的链接]
- kibana
GET [请求的链接]
也许,我们查看集群状态频率最高的是下面这个。
http://[主机IP]:[ES端口]
通常我们启动服务器之后,就可以通过这个简单的方式来验证服务器是否启动成功。
从下面返加的JSON我们可以得到该节点的节点名,所属集群名,ES版本号,lucene版本号
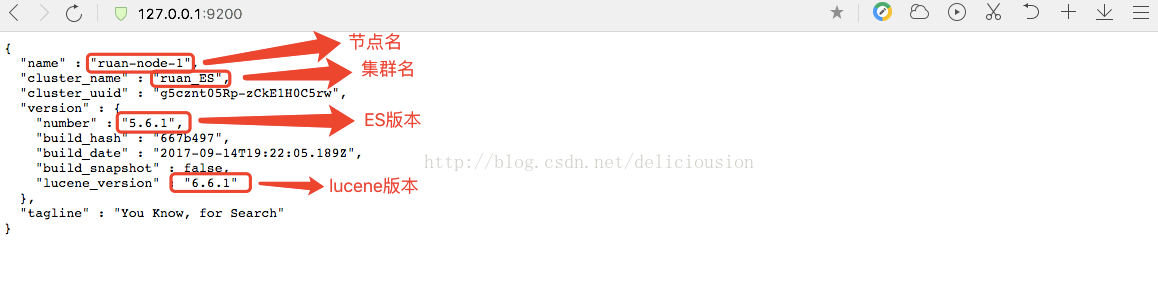
本次演示的集群有两个节点,属于本地单台机器的两个节点。
主机IP和端口如下
127.0.0.1:9200
127.0.0.1:9201
所以我们从另外一个节点进入,情况是一样的。
因此在下面演示过程中,端口号使用9200与9201无异,我选择9200端口进行演示。
下面演示利用其它URL来监控和查看集群状态。
1.查看集群的健康状态。
http://127.0.0.1:9200/_cat/health?v
URL中_cat表示查看信息,health表明返回的信息为集群健康信息,?v表示返回的信息加上头信息,跟返回JSON信息加上?pretty同理,就是为了获得更直观的信息,当然,你也可以不加,不要头信息,特别是通过代码获取返回信息进行解释,头信息有时候不需要,写shell脚本也一样,经常要去除一些多余的信息。
通过这个链接会返回下面的信息,下面的信息包括:
集群的状态(status):red红表示集群不可用,有故障。yellow黄表示集群不可靠但可用,一般单节点时就是此状态。green正常状态,表示集群一切正常。
节点数(node.total):节点数,这里是2,表示该集群有两个节点。
数据节点数(node.data):存储数据的节点数,这里是2。数据节点在Elasticsearch概念介绍有。
分片数(shards):这是12,表示我们把数据分成多少块存储。
主分片数(pri):primary shards,这里是6,实际上是分片数的两倍,因为有一个副本,如果有两个副本,这里的数量应该是分片数的三倍,这个会跟后面的索引分片数对应起来,这里只是个总数。
激活的分片百分比(active_shards_percent):这里可以理解为加载的数据分片数,只有加载所有的分片数,集群才算正常启动,在启动的过程中,如果我们不断刷新这个页面,我们会发现这个百分比会不断加大。

2.查看集群的索引数
http://127.0.0.1:9200/_cat/indices?v
通过该连接返回了集群中的所有索引,其中.kibana是kibana连接后在es建的索引,school是我自己添加的。
这些信息,包括
索引健康(health),green为正常,yellow表示索引不可靠(单节点),red索引不可用。与集群健康状态一致。
状态(status),表明索引是否打开。
索引名称(index),这里有.kibana和school。
uuid,索引内部随机分配的名称,表示唯一标识这个索引。
主分片(pri),.kibana为1,school为5,加起来主分片数为6,这个就是集群的主分片数。
文档数(docs.count),school在之前的演示添加了两条记录,所以这里的文档数为2。
已删除文档数(docs.deleted),这里统计了被删除文档的数量。
索引存储的总容量(store.size),这里school索引的总容量为6.4kb,是主分片总容量的两倍,因为存在一个副本。
主分片的总容量(pri.store.size),这里school的主分片容量是7kb,是索引总容量的一半。

3.查看集群所在磁盘的分配状况
http://127.0.0.1:9200/_cat/allocation?v
通过该连接返回了集群中的各节点所在磁盘的磁盘状况
返回的信息包括:
分片数(shards),集群中各节点的分片数相同,都是6,总数为12,所以集群的总分片数为12。
索引所占空间(disk.indices),该节点中所有索引在该磁盘所点的空间。
磁盘使用容量(disk.used),已经使用空间41.6gb
磁盘可用容量(disk.avail),可用空间4.3gb
磁盘总容量(disk.total),总共容量45.9gb
磁盘便用率(disk.percent),磁盘使用率90%。
4.查看集群的节点
http://127.0.0.1:9200/_cat/nodes?v
通过该连接返回了集群中各节点的情况。这些信息中比较重要的是master列,带*星号表明该节点是主节点。带-表明该节点是从节点。
另外还是heap.percent堆内存使用情况,ram.percent运行内存使用情况,cpu使用情况。
5.查看集群的其它信息。
http://127.0.0.1:9200/_cat/
通过上面的链接,其实,我们就相当于获得查看集群信息的目录。
=^.^= /_cat/allocation /_cat/shards /_cat/shards/{index} /_cat/master /_cat/nodes /_cat/tasks /_cat/indices /_cat/indices/{index} /_cat/segments /_cat/segments/{index} /_cat/count /_cat/count/{index} /_cat/recovery /_cat/recovery/{index} /_cat/health /_cat/pending_tasks /_cat/aliases /_cat/aliases/{alias} /_cat/thread_pool /_cat/thread_pool/{thread_pools} /_cat/plugins /_cat/fielddata /_cat/fielddata/{fields} /_cat/nodeattrs /_cat/repositories /_cat/snapshots/{repository} /_cat/templates
6.http创建空索引
需要添加http请求的head信息,指定为json

PUT /haoke
添加body
{ "settings": { "index": { "number_of_shards": "2", "number_of_replicas": "0" } } }
number_of_shards : 分片数
number_of_replicas: 副本数
6.1 创建带有类型、映射的索引
PUT /mytest
或
PUT /mytest?pretty
需要添加http请求的head信息,指定为json
添加body, json格式
{ "settings": { "index": { "number_of_shards": 3, "number_of_replicas": 2 } }, "mappings": { "properties": { "news_id": { "type": "long" }, "news_title": { "type": "text" }, "news_content": { "type": "text" }, "create_time": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss" }, "money": { "type": "scaled_float", "scaling_factor": 100 } } } }
定义字段
text:文本类型(会被es分词器进行分词)
keyword:文本类型(不被分词)
scaled_float:浮点型数据类型,
scaling_factor 因子
date:时间类型,可用format约束时间格式("yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" epoch_millis为时间戳)
7、删除索引
DELETE /haoke
不给请求体,返回 {"acknowledged": true}
8. 插入数据
POST /{索引}/{索引类型}/{id} id如果不传,会自动生成
例:
POST /haoke/user/1001
指定body
{ "id": 1001, "name": "张三", "age": 20, "sex": "男" }
查看结果:

说明:非结构化的索引,不需要事先创建,直接插入数据默认创建索引。
不指定id插入数据:
POST /haoke/user/
指定body
{ "id": 1002, "name": "张三", "age": 20, "sex": "男" }

更新数据:
在Elasticsearch中,文档数据是不可修改的,但是可以通过覆盖的方式进行更新,步骤如下:
1. 从旧文档中检索JSON
2. 修改它
3. 删除旧文档
4. 索引新文档
PUT /haoke/user/1001
指定body, 将性别修改为 “女”
{ "id": 1001, "name": "李四", "age": 30, "sex": "女" }

局部更新,与全部更新机制相同,只是多了_update标识
POST /haoke/user/1001/_update
指定body
{ "doc": { "age": 23 } }
查看 
9、 删除数据
发起delete请求即可
DELETE /haoke/user/1001

需要注意的是,result表示已经删除,version也增加了,如果删除一条不存在的数据,会响应404。 说明:删除一个文档不会立即从磁盘上移除,它只是被标记成已删除。Elasticsearch将会在你之后添加更多索引的时候才会在后台进行删除内容的清理。
10、搜索数据
根据id搜索数据
GET /haoke/user/6NAVEXEBVAiLr6jRjciF

11、搜索全部数据(默认返回10条数据)
GET /haoke/user/_search
如果是搜索10000条数据,指定size
POST /haoke/_doc/_search
指定http头信息
添加body
{ "size":10000, "query": { "match_all": {} } }
12、关键字搜素数据,查询年龄等于20的用户
GET /haoke/user/_search?q=age:20
13、 DSL搜索
14、删除所有数据
POST /haoke/_delete_by_query
传入body
{ "query": { "match_all": {} } }
返回:
{ "took": 1828, "timed_out": false, "total": 2983, "deleted": 2983, "batches": 3, "version_conflicts": 0, "noops": 0, "retries": { "bulk": 0, "search": 0 }, "throttled_millis": 0, "requests_per_second": -1.0, "throttled_until_millis": 0, "failures": [] }
ref: https://www.cnblogs.com/roadlandscape/p/12568550.html
