一,设置表自增id从1开始
alter table papa_group(表名称) AUTO_INCREMENT=1
二,查看每个字段的重复次数
select drugLicense,count(*) as count from drug_instruction20181211 group by drugLicense having count>1;
三,去重复
1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断 SELECT * FROM people WHERE peopleId IN ( SELECT peopleId FROM people GROUP BY peopleId HAVING count(peopleId) > 1 ) 2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有rowid最小的记录 DELETE FROM people WHERE peopleName IN ( SELECT * FROM ( SELECT peopleName FROM people GROUP BY peopleName HAVING count(peopleName) > 1 ) a ) AND peopleId NOT IN ( SELECT * FROM ( SELECT min(peopleId) FROM people GROUP BY peopleName HAVING count(peopleName) > 1 ) b ) 3、查找表中多余的重复记录(多个字段) SELECT * FROM drug_bid_bj WHERE (drug_bid_bj.peopleId, drug_bid_bj.seq) IN ( SELECT peopleId, seq FROM drug_bid_bj GROUP BY peopleId, seq HAVING count(*) > 1 ) 4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录 DELETE FROM vitae WHERE (vitae.peopleId, vitae.seq) IN ( SELECT * FROM( SELECT peopleId, seq FROM vitae GROUP BY peopleId, seq HAVING count(*) > 1 ) a ) AND rowid NOT IN ( SELECT * FROM( SELECT min(rowid) FROM vitae GROUP BY peopleId, seq HAVING count(*) > 1 ) b ) 5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录 SELECT * FROM vitae a WHERE (a.peopleId, a.seq) IN ( SELECT peopleId, seq FROM vitae GROUP BY peopleId, seq HAVING count(*) > 1 ) AND rowid NOT IN ( SELECT min(rowid) FROM vitae GROUP BY peopleId, seq HAVING count(*) > 1 ) 6.消除一个字段的左边的第一位: UPDATE tableName SET [ Title ]= RIGHT ([ Title ],(len([ Title ]) - 1)) WHERE Title LIKE '村%' 7.消除一个字段的右边的第一位: UPDATE tableName SET [ Title ]= LEFT ([ Title ],(len([ Title ]) - 1)) WHERE Title LIKE '%村' 8.假删除表中多余的重复记录(多个字段),不包含rowid最小的记录 UPDATE vitae SET ispass =- 1 WHERE peopleId IN ( SELECT peopleId FROM vitae GROUP BY peopleId
四,中标数据去重
DELETE FROM drug_bid WHERE ( drug_bid.province, drug_bid.drugName, drug_bid.bidPrice, drug_bid.manufacturerName, drug_bid.specification, drug_bid.dosageForm, drug_bid.drugLicense ) IN ( SELECT * FROM ( SELECT province, drugName, bidPrice, manufacturerName, specification, dosageForm, drugLicense FROM drug_bid GROUP BY province, drugName, bidPrice, manufacturerName, specification, dosageForm, drugLicense HAVING count(*) > 1 ) a ) AND id NOT IN ( SELECT * FROM ( SELECT max(id) FROM drug_bid GROUP BY province, drugName, bidPrice, manufacturerName, specification, dosageForm, drugLicense HAVING count(*) > 1 ) b )
五,某个字段的出现次数
SELECT COUNT(province), province FROM drug_bid20180919 WHERE id > 164842 GROUP BY province
六,查询数据库 "mammothcode" 下所有表名以及表注释
/* 查询数据库 ‘mammothcode’ 所有表注释 */ SELECT TABLE_NAME,TABLE_COMMENT FROM information_schema.TABLES WHERE table_schema='mammothcode';
七,要查询表字段的注释
/* 查询数据库 ‘mammothcode’ 下表 ‘t_adminuser’ 所有字段注释 */ SELECT COLUMN_NAME,column_comment FROM INFORMATION_SCHEMA.Columns WHERE table_name='t_adminuser' AND table_schema='mammothcode'
八,一次性查询数据库 "mammothcode" 下表注释以及对应表字段注释
SELECT t.TABLE_NAME,t.TABLE_COMMENT,c.COLUMN_NAME,c.COLUMN_TYPE,c.COLUMN_COMMENT FROM information_schema.TABLES t,INFORMATION_SCHEMA.Columns c WHERE c.TABLE_NAME=t.TABLE_NAME AND t.`TABLE_SCHEMA`='mammothcode'
九,使用存储过程,对上面sql语句进行存储,sql如下:
DELIMITER//
DROP PROCEDURE IF EXISTS findComment//
CREATE PROCEDURE findComment (dbName VARCHAR(50))
BEGIN
DECLARE stmt VARCHAR(65535);
#如果用户名长度大于0
IF LENGTH(dbName)>0 THEN
BEGIN
SET @sqlstr=CONCAT('SELECT t.TABLE_NAME,t.TABLE_COMMENT,c.COLUMN_NAME,c.COLUMN_TYPE,c.COLUMN_COMMENT FROM information_schema.TABLES t,INFORMATION_SCHEMA.Columns c WHERE c.TABLE_NAME=t.TABLE_NAME AND t.`TABLE_SCHEMA`=','''',dbName,'''');
END;
ELSE
BEGIN
SET @sqlstr=CONCAT('SELECT ','''','数据库名不能为空','''', 'AS ','''','提示','''');
END;
END IF;
PREPARE stmt FROM @sqlstr;
EXECUTE stmt;
END//
DELIMITER ;
# 调用存储过程:
CALL findComment('xiyinli_test');
上面的存储过程还可以简化:在存储过程中直接查询当前使用的数据库,如下:
DELIMITER//
DROP PROCEDURE IF EXISTS findComment//
CREATE PROCEDURE findComment ()
BEGIN
DECLARE stmt VARCHAR(65535);
#查询当前的 use-->database
SET @dbName=(SELECT DATABASE());
BEGIN
SET @sqlstr=CONCAT('SELECT t.TABLE_NAME,t.TABLE_COMMENT,c.COLUMN_NAME,c.COLUMN_TYPE,c.COLUMN_COMMENT FROM information_schema.TABLES t,INFORMATION_SCHEMA.Columns c WHERE c.TABLE_NAME=t.TABLE_NAME AND t.`TABLE_SCHEMA`=','''',@dbName,'''');
END;
PREPARE stmt FROM @sqlstr;
EXECUTE stmt;
END//
DELIMITER ;
调用:
CALL findComment();
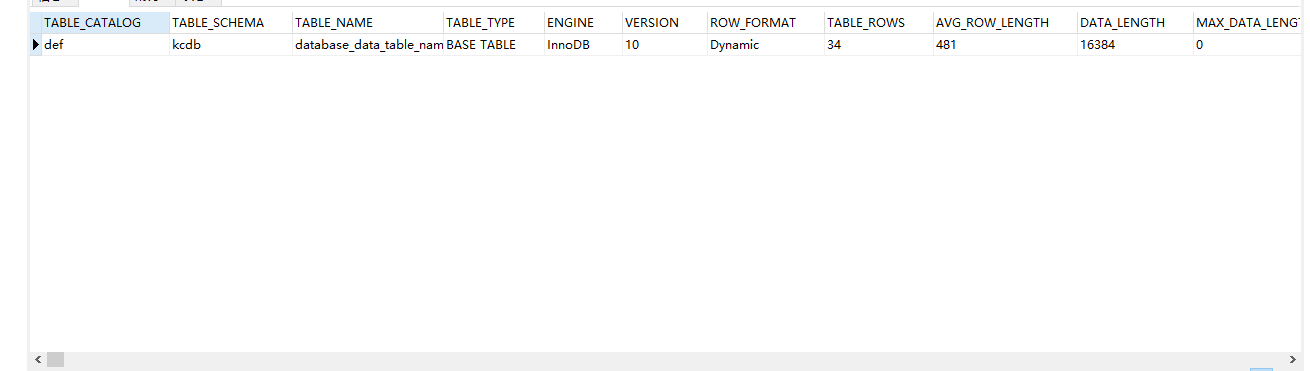
十,查看表信息
select * from information_schema.tables where table_schema = 'kcdb'(表所在的库) and table_name ='database_data_table_name_疾病'(表名称)
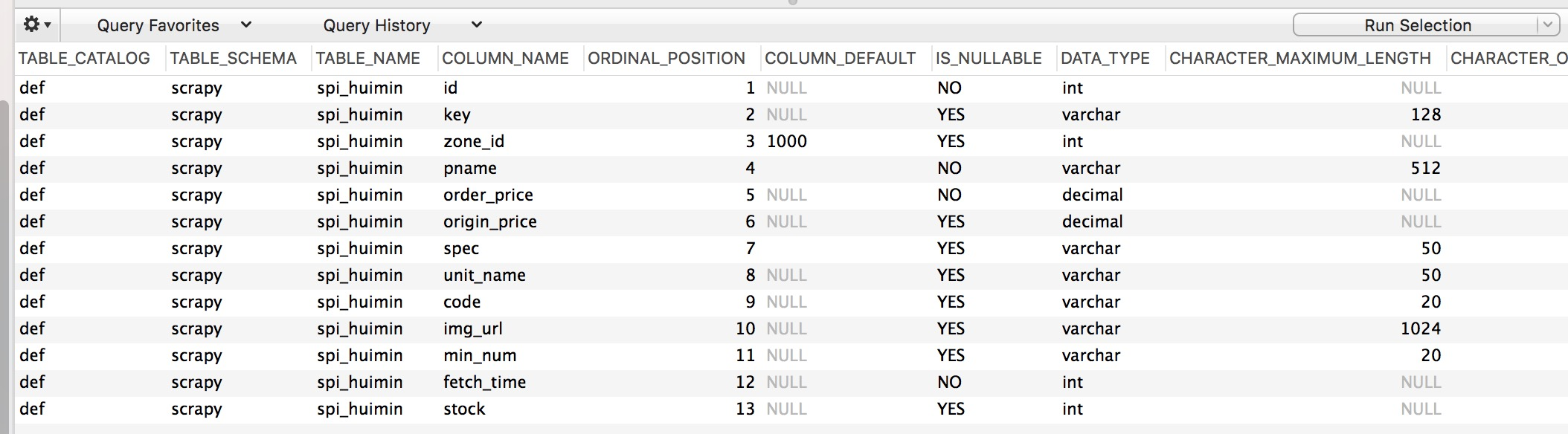
十一,查看表字段信息
select * from information_schema.columns where table_schema ='kcdb'(表所在的库) and table_name = 'database_data_table_name_疾病'(表名称)
十二.判断mysql当前连接是否有效
try:
self.cursor.ping()
except pymysql.MySQLError:
self.cursor.connect()
十三.数据库数据整理
import pymysql
import logging
import time
import re
# 添加日志
logging.basicConfig(
level=logging.INFO, # 定义输出到文件的log级别,大于此级别的都被输出
format='%(asctime)s %(filename)s %(levelname)s : %(message)s', # 定义输出log的格式
datefmt='%Y-%m-%d %H:%M:%S', # 时间
filename='error.log', # log文件名
filemode='a') # 写入模式“w”或“a”
class info(object):
def __init__(self):
self.strat_record = 0
self.end_record = 1000000001
self.db = pymysql.connect(host='localhost', port=3306, database='cfda', user='root', password='root',
charset='utf8')
# self.db = pymysql.connect(host='115.238.111.198', port=3306, database='spider_yu', user='spider',
# password='Kangce@0608',
# charset='utf8')
self.cursor = self.db.cursor()
while True:
self.parse_page()
def parse_page(self):
num = self.cursor.execute(
"select id, drug_instructions from drug_specification where id > {} limit 1000".format(self.strat_record))
if str(num) == str(0):
exit()
data_tuple = self.cursor.fetchall()
for data_one in data_tuple:
id = data_one[0]
drug_instructions = data_one[1].strip().replace("'", "‘")
self.strat_record = id
# 插入数据
self.cursor.execute(
'insert into catalogue() values()'.format())
self.db.commit()
# 查询数据
self.cursor.execute("select * from catalogue")
data = self.cursor.fetchone()
data = self.cursor.fetchall()
# 更新数据
self.cursor.execute("update catalogue set ''='{}', ''='{}' where id={}".format())
self.db.commit()
# 删除数据
self.cursor.execute("delete from catalogue where id={}".format())
self.db.commit()
if __name__ == '__main__':
info()
十四.删除数据,只增id从每个数据开始
DELETE from member WHERE member_id>19; ALTER TABLE member AUTO_INCREMENT=20;
十五,mysql查询区分大小写
1.SELECT * FROM TABLE NAME WHERE BINARY name='Clip'; # 查询的时候设置BINARY关键字 2.CREATE TABLE NAME(name VARCHAR(10) BINARY); # 创建表的时候该字段设置BINARY关键字 3.utf8_general_ci --不区分大小写 utf8_bin--区分大小写 # 在设置字符集排序规则的时候选择utf8_bin
十六,删除数据库中的所有表
SELECT
concat(
'DROP TABLE IF EXISTS ',
table_name,
';'
)
FROM
information_schema. TABLES
WHERE
table_schema = 'spider_app'; # spider_app是数据库名称
运行出的结果复制出来运行一边
十七,截断数据库中的所有表
SELECT
Concat(
'TRUNCATE TABLE ',
table_schema,
'.',
TABLE_NAME,
';'
)
FROM
INFORMATION_SCHEMA. TABLES
WHERE
table_schema IN ('db1_name', 'db2_name'); # 库名称
十八,从mysql中随机取几条数据
SELECT * FROM address WHERE id >= (SELECT floor(RAND() * (SELECT MAX(id) FROM address))) ORDER BY id LIMIT 0,10
十九 查询出的数据自动添加编号
SELECT (@i :=@i + 1) AS "编号", original_price, real_price, app_origin_id, app_name, app_name_cn, update_time FROM spider_app_source, (SELECT @i := 0) AS i WHERE ( app_origin_id = "305620" OR app_origin_id = "237930" OR app_origin_id = "383870" OR app_origin_id = "904310" OR app_origin_id = "710130" OR app_origin_id = "525360" OR app_origin_id = "434650" OR app_origin_id = "413150" OR app_origin_id = "732370" ) ORDER BY original_price ASC LIMIT 1000
二十 mysql根据id 随机返回10条数据
SELECT * FROM gov_list AS t1 JOIN (SELECT floor( rand() * (( SELECT max( id ) FROM gov_list ) - ( SELECT min( id ) FROM gov_list ) + 1 ) + ( SELECT min( id ) FROM gov_list )) AS id FROM gov_list LIMIT 10 ) AS t2 WHERE t1.id = t2.ide
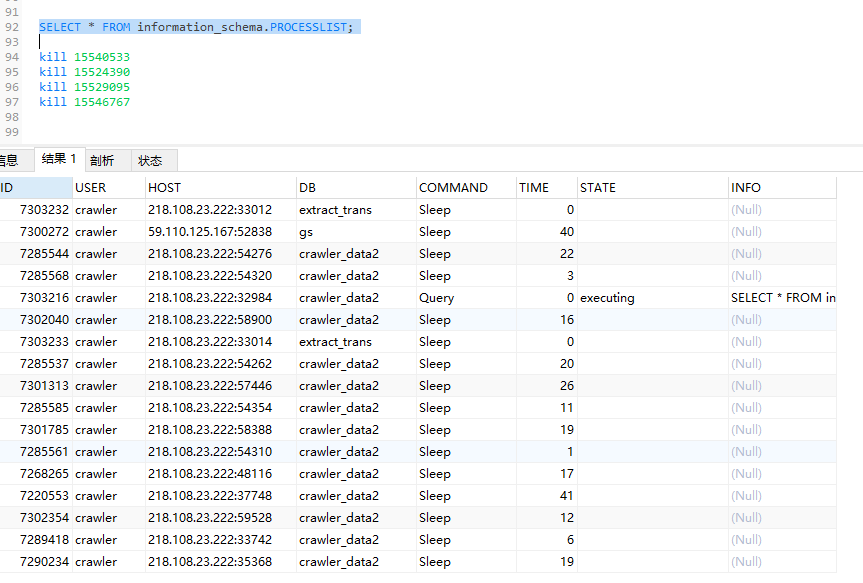
二十一 查询当前MySQL数据库实例中正在运行的进程列表
SELECT * FROM information_schema.PROCESSLIST; kill 15540533
当你执行这条SQL语句时,它会返回一个结果集,其中包含了每个正在运行的进程的信息,比如进程ID(`ID`)、用户(`USER`)、主机(`HOST`)、数据库(`DB`)、命令(`COMMAND`)、开始时间(`TIME`)等。
这个查询可以用来诊断问题,比如查找哪个查询正在消耗最多的资源,或者哪个连接已经长时间没有活动。通过观察 `COMMAND` 列,你可以识别出是查询(`Query`)、连接(`Connect`)、复制(`Slave`)等其他类型的操作。