


选择优化的数据类型
数据类型优化原则
1、更小的通常更好,更小的数据类型通常占用更小的磁盘、内存和CPU缓存。
2、简单就好,简单数据类型通常需要更少的CPU周期
3、尽量避免NULL,因为可为null的列使得索引、索引统计和值比较更为复杂。可为NULL的列会使用更多的存储空间。
整型
先从最基本的数据类型整型说起,首先用一张表格归纳一下:
| 数据类型 | 字节数 | 带符号最小值 | 带符号最大值 | 不带符号最小值 | 不带符号最大值 |
| TINYINT | 1 | -128 | 127 | 0 | 255 |
| SMALLINT | 2 | -32768 | 32767 | 0 | 65535 |
| MEDIUMINT | 3 | -8388608 | 8388607 | 0 | 16777215 |
| INT | 4 | -2147483648 | 2147483647 | 0 | 4294967295 |
| BIGINT | 8 | -9223372036854775808 | 9223372036854775807 | 0 | 18446744073709551616 |
即使是带符号的BIGINT,其实也已经是一个天文数字了,什么概念,9223372036854775807我们随便举下例子:
- 以byte为例可以表示8589934592GB-->8388608TB-->8192PB
- 以毫秒为例可以表示292471208年
所以从实际开发的角度,我们一定要为合适的列选取合适的数据类型,即到底用不用得到这种数据类型?举个例子:
- 一个枚举字段明明只有0和1两个枚举值,选用TINYINT就足够了,但在开发场景下却使用了BIGINT,这就造成了资源浪费
- 简单计算一下,假使该数据表中有100W数据,那么总共浪费了700W字节也就是6.7M左右,如果更多的表这么做了,那么浪费的更多
要知道,MySQL本质上是一个存储,以Java为例,可以使用byte类型的地方使用了long类型问题不大,因为绝大多数的对象在程序中都是短命对象,方法执行完毕这块内存区域就被释放了,7个字节实际上不存在浪不浪费一说。但是MySQL作为一个存储,8字节的BIGINT放那儿就放那儿了,占据的空间是实实在在的。
整型(N)形式
在形如TINYINT(M)、MEDIUMINT(M)、INTEGER(M)或BIGINT(M)的数据类型定义中,M代表需要显示的数字的位数,该值大小并不会对数据类型所能承载的值范围有影响。对于宽度M的设定,如果该列的数据位数没有达到M位,那么会从左使用空格补齐,如果该列数据已经超出M位,也不会影响数据的正常显示。数据的宽度补齐默认使用空格,在列声明时,添加ZEROFILL可以使用0进行补齐,如下建表语句使用ZEROFILL进行填充:

查看表内容时,其补齐如下图所示:
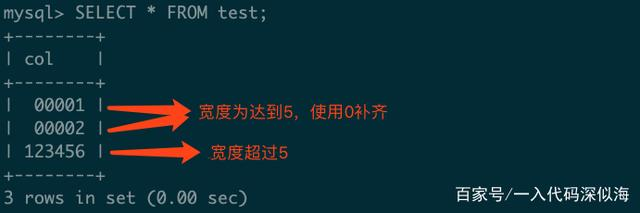
在开发中,我们会碰到有些定义整型的写法是int(11),这种写法从我个人开发的角度看我认为是没有多大用,不过作为一个知识点做一下讲解吧。
int(N)我们只需要记住两点:
- 无论N等于多少,int永远占4个字节
- N表示的是显示宽度,不足的用0补足,超过的无视长度而直接显示整个数字,但这要整型设置了unsigned zerofill才有效
实数类型
浮点型
整型之后,下面是浮点型,在MySQL中浮点型有两种,分别为float、double,它们三者用一张表格总结一下:
| 数据类型 | 字节数 | 备注 |
| float | 4 | 单精度浮点型 |
| double | 8 | 双精度浮点型 |
下面还是用SQL来简单看一下float和double型数据,以float为例,double同理:
create table test_float (
num float(5, 2)
) engine=innodb charset=utf8;
insert into test_float values(1.233);
insert into test_float values(1.237);
insert into test_float values(10.233);
insert into test_float values(100.233);
insert into test_float values(1000.233);
insert into test_float values(10000.233);
insert into test_float values(100000.233);
select * from test_float;
显示结果为:

从这个结果我们总结一下float(M,D)、double(M、D)的用法规则:
- D表示浮点型数据小数点之后的精度,假如超过D位则四舍五入,即1.233四舍五入为1.23,1.237四舍五入为1.24
- M表示浮点型数据总共的位数,D=2则表示总共支持五位,即小数点前只支持三位数,所以我们并没有看到1000.23、10000.233、100000.233这三条数据的插入,因为插入都报错了
当我们不指定M、D的时候,会按照实际的精度来处理。
定点型
介绍完float、double两种浮点型,我们介绍一下定点型的数据类型decimal类型,有了浮点型为什么我们还需要定点型?写一段SQL看一下就明白了:
create table test_decimal (
float_num float(10, 2),
double_num double(20, 2),
decimal_num decimal(20, 2)
) engine=innodb charset=utf8;
insert into test_decimal values(1234567.66, 1234567899000000.66, 1234567899000000.66);
insert into test_decimal values(1234567.66, 12345678990000000.66, 12345678990000000.66);
运行结果为:

看到float、double类型存在精度丢失问题,即写入数据库的数据未必是插入数据库的数据,而decimal无论写入数据中的数据是多少,都不会存在精度丢失问题,这就是我们要引入decimal类型的原因,decimal类型常见于银行系统、互联网金融系统等对小数点后的数字比较敏感的系统中。
最后讲一下decimal和float/double的区别,个人总结主要体现在两点上:
- float/double在db中存储的是近似值,而decimal则是以字符串形式进行保存的
- decimal(M,D)的规则和float/double相同,但区别在float/double在不指定M、D时默认按照实际精度来处理而decimal在不指定M、D时默认为decimal(10, 0)
字符串类型
| MySQL数据类型 | 含义 |
| char(n) | 固定长度,最多255个字符 |
| varchar(n) | 可变长度,最多65535个字符 |
| tinytext | 可变长度,最多255个字符 |
| text | 可变长度,最多65535个字符 |
| mediumtext | 可变长度,最多2的24次方-1个字符 |
| longtext | 可变长度,最多2的32次方-1个字符 |
1.char(n)和varchar(n)中括号中n代表字符的个数,并不代表字节个数,所以当使用了中文的时候(UTF8)意味着可以插入m个中文,但是实际会占用m*3个字节。
2.同时char和varchar最大的区别就在于char不管实际value都会占用n个字符的空间,而varchar只会占用实际字符应该占用的空间+1,并且实际空间+1<=n。
3.超过char和varchar的n设置后,字符串会被截断。
4.char的上限为255字节,varchar的上限65535字节,text的上限为65535。
5.char在存储的时候会截断尾部的空格,varchar和text不会。
6.varchar会使用1-3个字节来存储长度,text不会。
varchar类型的变化
MySQL 数据库的varchar类型在4.1以下的版本中的最大长度限制为255,其数据范围可以是0~255或1~255(根据不同版本数据库来定)。在 MySQL5.0以上的版本中,varchar数据类型的长度支持到了65535,也就是说可以存放65532个字节的数据,起始位和结束位占去了3个字 节,也就是说,在4.1或以下版本中需要使用固定的TEXT或BLOB格式存放的数据可以使用可变长的varchar来存放,这样就能有效的减少数据库文 件的大小。
MySQL 数据库的varchar类型在4.1以下的版本中,nvarchar(存储的是Unicode数据类型的字符)不管是一个字符还是一个汉字,都存为2个字节 ,一般用作中文或者其他语言输入,这样不容易乱码 ;varchar: 汉字是2个字节,其他字符存为1个字节 ,varchar适合输入英文和数字。
4.0版本以下,varchar(20),指的是20字节,如果存放UTF8汉字时,只能存6个(每个汉字3字节) ;5.0版本以上,varchar(20),指的是20字符,无论存放的是数字、字母还是UTF8汉字(每个汉字3字节),都可以存放20个,最大大小是65532字节 ;varchar(20)在Mysql4中最大也不过是20个字节,但是Mysql5根据编码不同,存储大小也不同,具体有以下规则:
a) 存储限制
varchar 字段是将实际内容单独存储在聚簇索引之外,内容开头用1到2个字节表示实际长度(长度超过255时需要2个字节),因此最大长度不能超过65535。
b) 编码长度限制
字符类型若为gbk,每个字符最多占2个字节,最大长度不能超过32766;
字符类型若为utf8,每个字符最多占3个字节,最大长度不能超过21845。
若定义的时候超过上述限制,则varchar字段会被强行转为text类型,并产生warning。
c) 行长度限制
导致实际应用中varchar长度限制的是一个行定义的长度。 MySQL要求一个行的定义长度不能超过65535。若定义的表长度超过这个值,则提示
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. You have to change some columns to TEXT or BLOBs。
varchar最大长度限制规则
1、限制规则
字段的限制在字段定义的时候有以下规则:
a) 存储限制
varchar 字段是将实际内容单独存储在聚簇索引之外,内容开头用1到2个字节表示实际长度(长度超过255时需要2个字节),因此最大长度不能超过65535。
b) 编码长度限制
字符类型若为gbk,每个字符最多占2个字节,最大长度不能超过32766;
字符类型若为utf8,每个字符最多占3个字节,最大长度不能超过21845。
对于英文比较多的论坛 ,使用GBK则每个字符占用2个字节,而使用UTF-8英文却只占一个字节。
若定义的时候超过上述限制,则varchar字段会被强行转为text类型,并产生warning。
c) 行长度限制
导致实际应用中varchar长度限制的是一个行定义的长度。 MySQL要求一个行的定义长度不能超过65535。若定义的表长度超过这个值,则提示
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. You have to change some columns to TEXT or BLOBs。
2、计算例子
举两个例说明一下实际长度的计算。
a) 若一个表只有一个varchar类型,如定义为
create table t4(c varchar(N)) charset=gbk;
则此处N的最大值为(65535-1-2)/2=32766。
减1的原因是实际行存储从第二个字节开始’;
减2的原因是varchar头部的2个字节表示长度;
除2的原因是字符编码是gbk。
b) 若一个表定义为
create table t4(c int, c2 char(30), c3 varchar(N)) charset=utf8;
则此处N的最大值为 (65535-1-2-4-30*3)/3=21812
减1和减2与上例相同;
减4的原因是int类型的c占4个字节;
减30*3的原因是char(30)占用90个字节,编码是utf8。
如果被varchar超过上述的b规则,被强转成text类型,则每个字段占用定义长度为11字节,当然这已经不是“varchar”了。
char和varchar类型
CHAR(M)定义的列的长度为固定的,M取值可以为0~255之间,当保存CHAR值时,在它们的右边填充空格以达到指定的长度。当检索到CHAR值时,尾部的空格被删除掉。在存储或检索过程中不进行大小写转换。CHAR存储定长数据很方便,CHAR字段上的索引效率级高,比如定义char(10),那么不论你存储的数据是否达到了10个字节,都要占去10个字节的空间,不足的自动用空格填充。
VARCHAR(M)定义的列的长度为可变长字符串,M取值可以为0~65535之间,(VARCHAR的最大有效长度由最大行大小和使用的字符集确定。整体最大长度是65,532字节)。VARCHAR值保存时只保存需要的字符数,另加一个字节来记录长度(如果列声明的长度超过255,则使用两个字节)。VARCHAR值保存时不进行填充。当值保存和检索时尾部的空格仍保留,符合标准SQL。varchar存储变长数据,但存储效率没有CHAR高。如果一个字段可能的值是不固定长度的,我们只知道它不可能超过10个字符,把它定义为 VARCHAR(10)是最合算的。VARCHAR类型的实际长度是它的值的实际长度+1。为什么"+1"呢?这一个字节用于保存实际使用了多大的长度。从空间上考虑,用varchar合适;从效率上考虑,用char合适,关键是根据实际情况找到权衡点。
CHAR和VARCHAR最大的不同就是一个是固定长度,一个是可变长度。由于是可变长度,因此实际存储的时候是实际字符串再加上一个记录字符串长度的字节(如果超过255则需要两个字节)。如果分配给CHAR或VARCHAR列的值超过列的最大长度,则对值进行裁剪以使其适合。如果被裁掉的字符不是空格,则会产生一条警告。如果裁剪非空格字符,则会造成错误(而不是警告)并通过使用严格SQL模式禁用值的插入。
最后看一下常用到的字符型,说到MySQL字符型,我们最熟悉的应该就是char和varchar了,关于char和varchar的对比,我总结一下:
- char是固定长度字符串,其长度范围为0~255且与编码方式无关,无论字符实际长度是多少,都会按照指定长度存储,不够的用空格补足;varchar为可变长度字符串,在utf8编码的数据库中其长度范围为0~21844
- char实际占用的字节数即存储的字符所占用的字节数,varchar实际占用的字节数为存储的字符+1或+2或+3
- MySQL处理char类型数据时会将结尾的所有空格处理掉而varchar类型数据则不会
关于第一点、第二点,稍后专门开一个篇幅解释,关于第三点,写一下SQL验证一下:
create table test_string (
char_value char(5),
varchar_value varchar(5)
) engine=innodb charset=utf8;
insert into test_string values('a', 'a');
insert into test_string values(' a', ' a');
insert into test_string values('a ', 'a ');
insert into test_string values(' a ', ' a ');
使用length函数来看一下结果:

验证了我们的结论,char类型数据并不会取最后的空格。
varchar型数据占用空间大小及可容纳最大字符串限制探究
接上一部分,我们这部分来探究一下varchar型数据实际占用空间大小是如何计算的以及最大可容纳的字符串为多少,首先要给出一个结论:这部分和具体编码方式有关,且MySQL版本我现在使用的是5.7,当然5.0之后的都是可以的。
先写一段SQL创建表,utf8的编码格式:
create table test_varchar (
varchar_value varchar(100000)
) engine=innodb charset=utf8;
执行报错:
Column length too big for column 'varchar_value' (max = 21845); use BLOB or TEXT instead
按照提示,我们把大小改为21845,执行依然报错:
Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
改为21844就不会有问题,因此在utf8编码下我们可以知道varchar(M),M最大=21844。那么gbk呢:
create table test_varchar (
varchar_value varchar(100000)
) engine=innodb charset=gbk;
同样的报错:
Column length too big for column 'varchar_value' (max = 32767); use BLOB or TEXT instead
把大小改为32766,也是和utf8编码格式一样的报错:
Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
可见gbk的编码格式下,varchar(M)最大的M=32765,那么为什么会有这样的区别呢,分点详细解释一下:
- MySQL要求一个行的定义长度不能超过65535即64K
- 对于未指定varchar字段not null的表,会有1个字节专门表示该字段是否为null
- varchar(M),当M范围为0<=M<=255时会专门有一个字节记录varchar型字符串长度,当M>255时会专门有两个字节记录varchar型字符串的长度,把这一点和上一点结合,那么65535个字节实际可用的为65535-3=65532个字节
- 所有英文无论其编码方式,都占用1个字节,但对于gbk编码,一个汉字占两个字节,因此最大M=65532/2=32766;对于utf8编码,一个汉字占3个字节,因此最大M=65532/3=21844,上面的结论都成立
- 举一反三,对于utfmb4编码方式,1个字符最大可能占4个字节,那么varchar(M),M最大为65532/4=16383,可以自己验证一下
同样的,上面是表中只有varchar型数据的情况,如果表中同时存在int、double、char这些数据,需要把这些数据所占据的空间减去,才能计算varchar(M)型数据M最大等于多少。
varchar、text和blob
最后讲一讲text和blob两种数据类型,它们的设计初衷是为了存储大数据使用的,因为之前说了,MySql单行最大数据量为64K。
先说一下text,text和varchar是一组既有区别又有联系的数据类型,其联系在于当varchar(M)的M大于某些数值时,varchar会自动转为text:
- M>255时转为tinytext
- M>500时转为text
- M>20000时转为mediumtext
所以过大的内容varchar和text没有区别,同事varchar(M)和text的区别在于:
- 单行64K即65535字节的空间,varchar只能用63352/65533个字节,但是text可以65535个字节全部用起来
- text可以指定text(M),但是M无论等于多少都没有影响
- text不允许有默认值,varchar允许有默认值
varchar和text两种数据类型,使用建议是能用varchar就用varchar而不用text(存储效率高),varchar(M)的M有长度限制,之前说过,如果大于限制,可以使用mediumtext(16M)或者longtext(4G)。
至于text和blob,简单过一下就是text存储的是字符串而blob存储的是二进制字符串,简单说blob是用于存储例如图片、音视频这种文件的二进制数据的。
日期类型
接着我们看一下MySQL中的日期类型,MySQL支持五种形式的日期类型:date、time、year、datetime、timestamp,用一张表格总结一下这五种日期类型:
| 数据类型 | 字节数 | 格式 | 备注 |
| date | 3 | yyyy-MM-dd | 存储日期值 |
|
time |
3 | HH:mm:ss | 存储时分秒 |
| year | 1 | yyyy | 存储年 |
| datetime | 8 | yyyy-MM-dd HH:mm:ss | 存储日期+时间 |
| timestamp | 4 | yyyy-MM-dd HH:mm:ss | 存储日期+时间,可作时间戳 |
下面我们还是用SQL来验证一下:
create table test_time (
date_value date,
time_value time,
year_value year,
datetime_value datetime,
timestamp_value timestamp
) engine=innodb charset=utf8;
insert into test_time values(now(), now(), now(), now(), now());
看一下插入后的结果:

MySQL的时间类型的知识点比较简单,这里重点关注一下datetime与timestamp两种类型的区别:
- 上面列了,datetime占8个字节,timestamp占4个字节
- 由于大小的区别,datetime与timestamp能存储的时间范围也不同,datetime的存储范围为1000-01-01 00:00:00——9999-12-31 23:59:59,timestamp存储的时间范围为19700101080001——20380119111407
- datetime默认值为空,当插入的值为null时,该列的值就是null;timestamp默认值不为空,当插入的值为null的时候,mysql会取当前时间
- datetime存储的时间与时区无关,timestamp存储的时间及显示的时间都依赖于当前时区
在实际工作中,一张表往往我们会有两个默认字段,一个记录创建时间而另一个记录最新一次的更新时间,这种时候可以使用timestamp类型来实现:
create_time timestamp default current_timestamp comment "创建时间", update_time timestamp default current_timestamp on update current_timestamp comment "修改时间",
数据类型属性
上面大概总结了MySQL中的数据类型,当然了,上面的总结肯定是不全面的,如果要非常全面的总结这些内容,好几篇文章都不够的。下面就再来总结一些常用的属性。
1.auto_increment
auto_increment能为新插入的行赋一个唯一的整数标识符。为列赋此属性将为每个新插入的行赋值为上一次插入的ID+1。
MySQL要求将auto_increment属性用于作为主键的列。此外,每个表只允许有一个auto_increment列。例如:
id smallint not null auto_increment primary key
2.binary
binary属性只用于char和varchar值。当为列指定了该属性时,将以区分大小写的方式排序。与之相反,忽略binary属性时,将使用不区分大小写的方式排序。例如:
hostname char(25) binary not null
3.default
default属性确保在没有任何值可用的情况下,赋予某个常量值,这个值必须是常量,因为MySQL不允许插入函数或表达式值。此外,此属性无法用于BLOB或TEXT列。如果已经为此列指定了NULL属性,没有指定默认值时默认值将为NULL,否则默认值将依赖于字段的数据类型。例如:
subscribed enum('0', '1') not null default '0'
4.index
如果所有其他因素都相同,要加速数据库查询,使用索引通常是最重要的一个步骤。索引一个列会为该列创建一个有序的键数组,每个键指向其相应的表行。以后针对输入条件可以搜索这个有序的键数组,与搜索整个未索引的表相比,这将在性能方面得到极大的提升。
create table employees ( id varchar(9) not null, firstname varchar(15) not null, lastname varchar(25) not null, email varchar(45) not null, phone varchar(10) not null, index lastname(lastname), primary key(id) );
我们也可以利用MySQL的create index命令在创建表之后增加索引:
create index lastname on employees (lastname(7));
这一次只索引了名字的前7个字符,因为可能不需要其它字母来区分不同的名字。因为使用较小的索引时性能更好,所以应当在实践中尽量使用小的索引。
5.not null
如果将一个列定义为not null,将不允许向该列插入null值。建议在重要情况下始终使用not null属性,因为它提供了一个基本验证,确保已经向查询传递了所有必要的值。
6.null
为列指定null属性时,该列可以保持为空,而不论行中其它列是否已经被填充。记住,null精确的说法是“无”,而不是空字符串或0。
7.primary key
primary key属性用于确保指定行的唯一性。指定为主键的列中,值不能重复,也不能为空。为指定为主键的列赋予auto_increment属性是很常见的,因为此列不必与行数据有任何关系,而只是作为一个唯一标识符。主键又分为以下两种:
(1)单字段主键
如果输入到数据库中的每行都已经有不可修改的唯一标识符,一般会使用单字段主键。注意,此主键一旦设置就不能再修改。
(2)多字段主键
如果记录中任何一个字段都不可能保证唯一性,就可以使用多字段主键。这时,多个字段联合起来确保唯一性。如果出现这种情况,指定一个auto_increment整数作为主键是更好的办法。
8.unique
被赋予unique属性的列将确保所有值都有不同的值,只是null值可以重复。一般会指定一个列为unique,以确保该列的所有值都不同。例如:
email varchar(45) unique
9.zerofill
zerofill属性可用于任何数值类型,用0填充所有剩余字段空间。例如,无符号int的默认宽度是10;因此,当“零填充”的int值为4时,将表示它为0000000004。例如:
orderid int unsigned zerofill not null
缓存表和汇总表
缓存表
主要用于优化搜索和检索查询语句,将原始表的部分字段列存储到缓存表。
汇总表
主要用于数据的统计操作。
物化视图
视图实际上是预先计算并且存储在磁盘上的表,不需要查询原始数据来更新视图,原始表中每一条数据的变化都会反应到物化视图中。
计数器表
加快ALTER TABLE的速度
ALTER TABLE原理
MySQL在执行表结构变化的操作是通过创建一个空表,并将旧表数据插入新表,删除旧表,新表替换掉旧表。例如添加新字段到表中
ALTER TABLE tasks ADD COLUMN complete DECIMAL(2,1) NULL AFTER description;
通过SHOW STATUS指令显示这个语句做了1000次读和1000写操作,也就是说将旧表数据拷贝到了新表。
只修改.frm文件
有一部分字段属性的变更不会引起新表与旧表的变化,这部分操作只需要改动.frm文件即可。
移除(不是增加)一个列的AUTO_INCREMENT属性
增加、移除或者变更ENUM和SET常量。
操作步骤如下
1、创建一张相同结构的表,并进行所需要的修改。
2、执行FLUSH TABLES WITH READ LOCK。
3、新表与旧表交换.frm文件。
4、执行 UNLOCK TABLES对表解锁。
