


数据分片主要是将数据按照一定的规则分为几个完全不同的数据集合的方式成为数据分片。数据的切分可以是数据库内的,将数据库中的一张表切分为几个不同的数据库表。也可以是数据库级别的,将数据库中的表划分为多个表,这些表存储在不同的数据库服务器上。该部分主要用来介绍数据库级的数据分片。切分规则将具有相关的数据保存在同一个分片上可以提高数据查询效率。数据库分片的路由规则可以是应用程序或者数据库层和应用层之间的管理层进行分片。
分片的结构图:
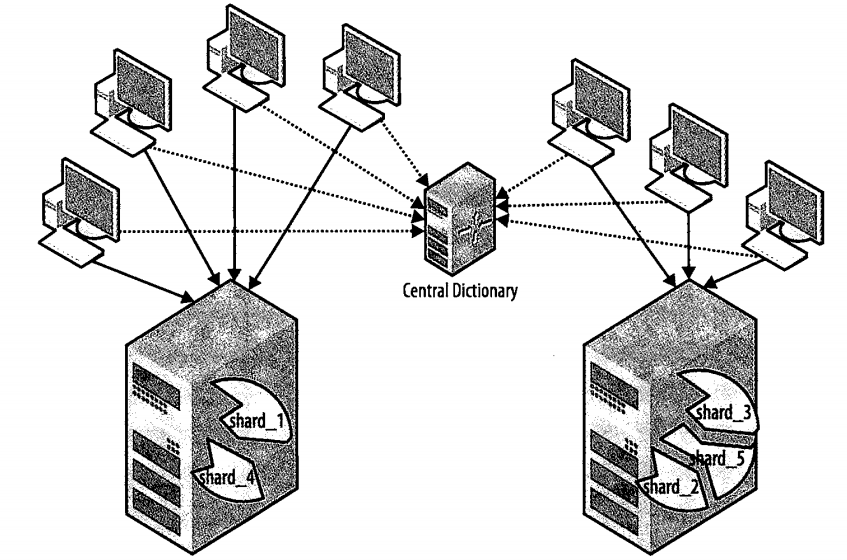
数据进行分片时需要考虑对以后的数据维护,一般在分片时满足以下集中情况:
1、要很容易的移动分片。
2、由于一个服务器上有多个分片,所以要比较容易的识别分片,并且分片命名要有规则。
3、可以单独复制分片到其他服务器。
数据分区
选择分区键
选择分区键需要考虑一下几个因素:
1、在哪里存储数据
2、从哪里取到希望得到的数据
一个好的分区键时一个数据库中一个分厂重要的实体主键,这些键值决定了分片单元。
在选择分区键的时候需要避免以下几种情况发生:
1、选择那些能够避免跨分片查询,能够使分片足够下,避免足够过大的分片导致问题。
2、尽量使分片分布均匀。
多个分区键
在有多个查询类型时,可以设置多个分区键对数据进行分片。
在节点上部署分片
数据在分区时需要将相关的数据保存在一个分片上,保证数据操作的高效性。数据分片需要一个合适的分片键,在选择分区键以后,可以通过两种模式实现数据分区:
静态分区模式
静态分区是通过哈希函数对分区键中的值进行哈希值计算,通过哈希值来判断数据存储的分片。或者通过id字段进行分区,id值在0~9999在分片1上,10000~19999在分片2上。但是静态分片不是很灵活,在对数据重新分片后,需要修改应用层的路由规则。
动态分区模式
通过一个数据中心存储分片与数据的关联关系,可以通过数据中心实现动态分配。但是在进行数据操作时,需要首先访问数据中心中的分片与数据的关系。动态分片比较灵活,在进行重新分片时,将数据重新重新分片后,对共享数据中心的分片信息重新配置即可。
混合分区模式
分片之间的均衡
移动分片
分片间移动数据
分片实例
静态分片
现在有一个需求,用户可以发表博文也可以对博文进行评论。相关的数据库表如下:
create table user(userid,password,name)
create table articles(article_id,author_id,published,body)
create table comments(comment_id,for_article,author_name,added,body)
人员信息如果在1亿条范围内,无需分片,但是随着发表的博文越来越多,需要对博文和回复进行分片处理,分片的命名可以以shard为基础,并加上分片号,如shard_123。为了能够高效的对数据操作,可以将同一个人员的所有博文保存在同一个分片上,将同一篇博文的相关回复保存在同一个分片上。分片键可以为用户id(userId)也可以为博文id(articleid)。
通过用户id获取分片号,获取到分片号后对该用户的博文进行操作。
通过博文id获取分片号。对分片上的博文和回复进行操作。
动态分片
如果某一天的一个人发表了一些比较有趣的博文,引起了很多人的关注,导致该人所在的分片变得较“热”,从而使该分片上的数据查询和操作变得较慢,数据库性能下降。如果在静态分片的模式下要想实现数据分片在节点间移动,比较困难。此时需要借助动态分片实现数据的移动。
现在需要新加几个数据库表实现动态分片:
create table user(user_id,name,shard,primary key(user_id))
create table shard_to_node(shard,host,port,sock,Key(shard))
create table article_author(user_id,author_id,primary key(article_id))
在user数据库表中查询出该人员的博文和回复所在的分片,通过分片与节点的映射表shard_to_node查询出该分片所在的节点,通过返回的结果中的分片和节点信息对博文和回复进行查询。
