


分词器介绍
当对一个文档(document是一系列field的集合)进行索引时,其中的每个field(document和file都是lucene中的概念)中的数据都会经历分析,分词和多步的分词过滤等操作。这一系列的动作是什么呢?直观的理解是,将一句话分成单个的单词,去掉句子当中的空白符号,去掉多余的词,进行同义词代换等等。
例】what a beautiful day? 会进行什么处理呢?what ,a 以及问号都将被去掉,最后处理结果为beautiful和day(也有可能是beautiful day)。
不仅仅是在索引的时候进行这些工作,查询的时候也要做这些工作,而且通常索引和查询使用同样的方法来进行处理。这样做的目的是为了保证索引与查询的正确匹配。下例说明了采取不同的处理时的不匹配情况。【例】ABCD索引分词为AB CD,查询时候分词为ABC D,显然查询的匹配结果为0。
词性转换
一种是将一个词扩展成它的多种形式,例如将run扩展成runs,running。另外一种是词性规约,例如将runns,running等都“收缩”成run。前者只需要在索引或查询的任意一端采用即可,后者需要在两端同时采用。
分析器(Analyzer)
分析器是包括连个部分:分词器和过滤器。分词器顾名思意就是将句子分词单个的词,过滤器就是对分词的结果进行筛选,例如中文中将“的”“呀”这些对句子主体意思影响不大的词删除。英语中类似的就是"is","a"等等。通常在索引和分词两端应该采用同样的分词器。solr自带了一些分词器,如果你需要使用自己公司的分词器,那么就需要修改solr模式(Solr schema)。
schema.xml 文件允许两种方式修改文本被分析的方式,通常只有field类型为 solr.TextField 的field的内容允许定制分析器。
方法一:使用任何 org.apache.lucene.analysis.Analyzer的子类进行设定。如:
<fieldtype name="nametext" class="solr.TextField"> <analyzer class="org.apache.lucene.analysis.WhitespaceAnalyzer"/> </fieldtype>
可以使用第三方中文分析器,如mmseg4j、IKAnalyzer、Ansj和paoding。
方法二:
指定一个TokenizerFactory ,后面跟一系列的TokenFilterFactories(它们将按照所列的顺序发生作用),Factories被用来创建分词器和分词过滤器,它们用于对分词器和分词过滤器的准备配置,这样做的目的是为了避免the overhead of creation via reflection。如
<fieldType name="front_gram" class="solr.TextField"
positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory" />
<filter class="solr.LowerCaseFilterFactory" />
<filter class="solr.EdgeNGramFilterFactory" minGramSize="1"
maxGramSize="40" slide="front" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory" />
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>
一、TokenizerFactories
solr.KeywordTokenizerFactory
不管什么内容,整句当成一个关键字
solr.LetterTokenizerFactory
根据字母来分词,抛弃非字母的部分,例如:"I can't" ==> "I", "can", "t"
solr.WhitespaceTokenizerFactory
根据空格来分词,例如:"I do" ==> "I", "do"
solr.LowerCaseTokenizerFactory
根据字母分词,并将所有字母转换成小写,抛弃非字母的部分,例如:"I can't" ==> "i", "can", "t"
solr.StandardTokenizerFactory
分词举例: "I.B.M. cat's can't" ==> ACRONYM: "I.B.M.", APOSTROPHE:"cat's", APOSTROPHE:"can't"说明:该分词器,会自动地给每个分词添加type,以便接下来的对type敏感的过滤器进行处理,目前仅仅只有StandardFilter对Token的类型是敏感的
二、TokenFilterFactory
solr.StandardFilterFactory
创建org.apache.lucene.analysis.standard.StandardFilter。
移除首字母简写中的点和Token后面的's。仅仅作用于有类的Token,他们是由StandardToken产生的。例如:"I.B.M. cat's can't"→“IBM”,“cat”,“cat't”
solr.LowerCaseFilterFactory
创建org.apache.lucene.analysis.LowerCaseFilter。
solr.TrimFilterFactory
创建org.apache.solr.analysis.TrimFilter
去掉Token两端的空白符,例:"Kittens! ","Duck"→"Kittens!","Duck"。
solr.StopFilterFactory
创建org.apache.lucene.analysis.StopFilter
去掉如下的通用词,多为虚词。
solr.KeepWordFilterFactory
创建org.apache.solr.analysis.KeepWordFilter
作用与solr.StopFilterFactory相反,保留词的列表也可以通过“word”属性进行指定。
solr.LengthFilterFactory
创建solr.LengthFilter
过滤掉长度在某个范围之外的词。
solr.PorterStemFilterFactory
创建org.apache.lucene.analysis.PorterStemFilter
采用Porter Stemming Algorithm算法去掉单词的后缀,例如将复数形式变成单数形式,第三人称动词变成第一人称,现在分词变成一般现在时的动词。
solr.EnglishPorterFilterFactory
创建solr.EnglishPorterFilter
关于句子主干的处理,其中的“protected”指定不允许修改的词的文件。
solr.SnowballPorterFilterFactory
关于不同语言的词干处理。
solr.WordDelimiterFilterFactory
关于分隔符的处理。
solr.SynonymFilterFactory
关于同义词的处理。
solr.RemoveDuplicatesTokenFilterFactory
避免重复处理
mmseg4j
详细介绍如下:
1、mmseg4j 用 Chih-Hao Tsai 的 MMSeg 算法(http://technology.chtsai.org/mmseg/ )实现的中文分词器,并实现 lucene 的 analyzer 和 solr 的TokenizerFactory 以方便在Lucene和Solr中使用。
2、MMSeg 算法有两种分词方法:Simple和Complex,都是基于正向最大匹配。Complex 加了四个规则过虑。官方说:词语的正确识别率达到了 98.41%。mmseg4j 已经实现了这两种分词算法。
1.5版的分词速度simple算法是 1100kb/s左右、complex算法是 700kb/s左右,(测试机:AMD athlon 64 2800+ 1G内存 xp)。
1.6版在complex基础上实现了最多分词(max-word)。“很好听” -> "很好|好听"; “中华人民共和国” -> "中华|华人|共和|国"; “中国人民银行” -> "中国|人民|银行"。
1.7-beta 版, 目前 complex 1200kb/s左右, simple 1900kb/s左右, 但内存开销了50M左右. 上几个版都是在10M左右。
MMSeg4j分词器简单使用实例:
package solrtest;
import java.io.File;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.LinkedList;
import java.util.List;
import java.util.UUID;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import com.chenlb.mmseg4j.Dictionary;
import com.chenlb.mmseg4j.analysis.ComplexAnalyzer;
import com.chenlb.mmseg4j.analysis.SimpleAnalyzer;
public class Mmseg4jTest {
public static void main(String[] args) throws IOException, Exception{
List<Phone> list = new LinkedList<Phone>();
for(int i=0;i<3;i++){
Phone phone = new Phone();
phone.setId(UUID.randomUUID().toString());
phone.setName("华为产品"+i);
phone.setPhoneType("荣耀"+(6+i));
phone.setPrice(""+(3000+i*1000));
list.add(phone);
}
try {
createIndex(list);
// searchIndex("华为");
} catch (Exception e) {
System.out.println(e);
}
}
public static void createIndex(List<Phone> list) throws IOException{
// mmseg4j字典路径
String path = new File("src/solrtest/mmseg4j").getAbsolutePath();
// Dictionary dictionary = Dictionary.getInstance(path);
//索引文件的存储位置,该类在Lucene中用于描述索引存放的位置信息
// String LUCENE_INDEX_DIR = new File("src/solrtest/mmseg4j").getAbsolutePath();
Directory directory = FSDirectory.open(Paths.get(path));
//
//创建分析器
Analyzer analyzer = new ComplexAnalyzer();
//创建配置器
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
/**
APPEND:总是追加,可能会导致错误,索引还会重复,导致返回多次结果
CREATE:清空重建(推荐)
CREATE_OR_APPEND【默认】:创建或追加
*/
indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
for(int i=0;i<list.size();i++){
Document document = new Document();
document.add(new TextField("id", list.get(i).getId(), Store.YES));
document.add(new TextField("name", list.get(i).getName(), Store.YES));
document.add(new TextField("phoneType", list.get(i).getPhoneType(), Store.YES));
document.add(new TextField("price", list.get(i).getPrice(), Store.YES));
indexWriter.addDocument(document);
}
indexWriter.commit();
indexWriter.close();
}
public static void searchIndex(String value) throws IOException, ParseException{
String path = new File("src/solrtest/mmseg4j").getAbsolutePath();
//索引文件的存储位置
Directory directory = FSDirectory.open(Paths.get(path));
//它只读取索引文档. 然后交给检索工具IndexSearcher 去完成查找. 根据传进Query检索条件进行检索查找后,
//会得到一个ScoreDoc类型的结果集, 然后读取它的Document信息, 就能获取检索结果的具体信息, 比如关键字包含在哪些内容中,
//已经这些内容文档的存放路径等等. 这样就算是完成整个检索过程了.
IndexReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSearch = new IndexSearcher(indexReader);
Analyzer analyzer = new ComplexAnalyzer();
//对于中文查询,需要分词
// QueryParser parser = new MultiFieldQueryParser(new String[] { "name" }, analyzer);
QueryParser parser = new MultiFieldQueryParser(new String[] { "title" }, analyzer);
parser.setDefaultOperator(QueryParser.AND_OPERATOR);
// 根据域和目标搜索文本创建查询器
Query query = parser.parse(value);
System.out.println("docid:"+query.toString(value));
//返回得分最高的
TopDocs topdocs=indexSearch.search(query, 3);
//排名靠前的n个符合条件的查询
ScoreDoc[] scoreDocs=topdocs.scoreDocs;
for(int i=0; i < scoreDocs.length; i++) {
int doc = scoreDocs[i].doc;
Document document = indexSearch.doc(doc);
System.out.println("docid:" + scoreDocs[i].doc);
System.out.println("scors:" + scoreDocs[i].score);
System.out.println("shardIndex:" + scoreDocs[i].shardIndex);
System.out.println("id:"+document.get("id")+",name:"+document.get("name")+",price:"+document.get("price"));
}
indexReader.close();
}
}
solr配置MMSeg4j分词器实例:
1、首先下载对应的jar包:mmseg4j-solr-2.4.0.jar,mmseg4j-analysis-1.9.1.jar,mmseg4j-core-1.10.0.jar。
2、将jar包拷贝到服务器solr的lib包下
3、配置schema.xml。
<fieldType name="text_ms" class="solr.TextField" positionIncrementGap="100" >
<analyzer type="index">
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" /><!--此处为分词器词典所处位置-->
</analyzer>
<analyzer type="query">
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" /><!--此处为分词器词典所处位置-->
</analyzer>
</fieldType>
IKAnalyzer
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IK Analyzer 3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
IK Analyzer 结构设计
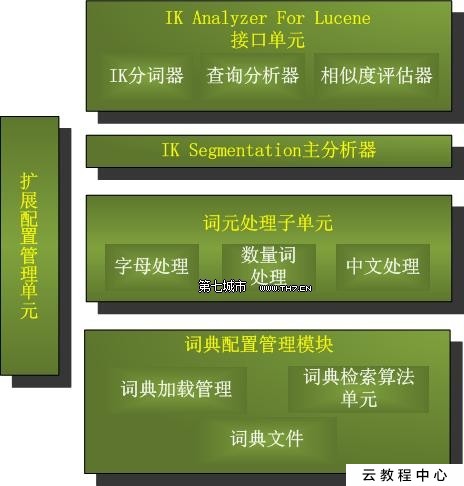
IK Analyzer 特性
- 采用了特有的“正向迭代最细粒度切分算法“,具有80万字/秒的高速处理能力
- 采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
- 优化的词典存储,更小的内存占用。支持用户词典扩展定义
- 针对Lucene全文检索优化的查询分析器IKQueryParser
分词效果示例
文本原文1:
IK-Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IKAnalyzer已经推出了3个大版本。
分词结果:
ik-analyzer | 是 | 一个 | 一 | 个 | 开源 | 的 | 基于 | java | 语言 | 开发 | 的 | 轻量级 | 量级 | 的 | 中文 | 分词 | 工具包 | 工具 | 从 | 2006 | 年 | 12 | 月 | 推出 | 1.0 | 版 | 开始 | ikanalyzer | 已经 | 推出 | 出了 | 3 | 个大 | 个 | 版本
文本原文2:
永和服装饰品有限公司
分词结果:
永和 | 和服 | 服装 | 装饰品 | 装饰 | 饰品 | 有限 | 公司
IK Analyzer分词器简单使用实例:
package solrtest;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.LinkedList;
import java.util.List;
import java.util.UUID;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.similarities.Similarity;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class IKTest {
public static void main(String[] args) throws IOException, ParseException{
List<Phone> list = new LinkedList<Phone>();
for(int i=0;i<3;i++){
Phone phone = new Phone();
phone.setId(UUID.randomUUID().toString());
phone.setName("华为荣耀");
phone.setPhoneType("note"+(6+i));
phone.setPrice(""+(3000+i*1000));
list.add(phone);
}
// createIndex(list);
searchIndex("华为");
}
public static void createIndex(List<Phone> list) throws IOException{
String path = new File("src/solrtest/ikanalyzer").getAbsolutePath();
Analyzer analyzer =new IKAnalyzer();
Directory directory= FSDirectory.open(Paths.get(path));
//创建配置器
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
/**
APPEND:总是追加,可能会导致错误,索引还会重复,导致返回多次结果
CREATE:清空重建(推荐)
CREATE_OR_APPEND【默认】:创建或追加
*/
indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
for(int i=0;i<list.size();i++){
Document document = new Document();
document.add(new StringField("id", list.get(i).getId(), Store.YES));
document.add(new StringField("name", list.get(i).getName(), Store.YES));
document.add(new StringField("phoneType", list.get(i).getPhoneType(), Store.YES));
document.add(new StringField("price", list.get(i).getPrice(), Store.YES));
indexWriter.addDocument(document);
}
indexWriter.commit();
indexWriter.close();
}
public static void searchIndex(String value) throws IOException, ParseException{
String path = new File("src/solrtest/ikanalyzer").getAbsolutePath();
//索引文件的存储位置
Directory directory = FSDirectory.open(Paths.get(path));
//它只读取索引文档. 然后交给检索工具IndexSearcher 去完成查找. 根据传进Query检索条件进行检索查找后,
//会得到一个ScoreDoc类型的结果集, 然后读取它的Document信息, 就能获取检索结果的具体信息, 比如关键字包含在哪些内容中,
//已经这些内容文档的存放路径等等. 这样就算是完成整个检索过程了.
Analyzer analyzer =new IKAnalyzer();
DirectoryReader indexReader = DirectoryReader.open(directory);
IndexSearcher indexSearch = new IndexSearcher(indexReader);
String fieldName = "name";
String request = "anb";
QueryParser parser = new QueryParser(fieldName, analyzer);
parser.setDefaultOperator(QueryParser.AND_OPERATOR);
Query query = parser.parse(request);
TopDocs topDocs = indexSearch.search(query, 5);
//返回得分最高的
// TopDocs topdocs=indexSearch.search(query, 3);
//排名靠前的n个符合条件的查询
ScoreDoc[] scoreDocs=topDocs.scoreDocs;
for(int i=0; i < scoreDocs.length; i++) {
int doc = scoreDocs[i].doc;
Document document = indexSearch.doc(doc);
System.out.println("docid:" + scoreDocs[i].doc);
System.out.println("scors:" + scoreDocs[i].score);
System.out.println("shardIndex:" + scoreDocs[i].shardIndex);
System.out.println("id:"+document.get("id")+",name:"+document.get("name")+",price:"+document.get("price"));
}
indexReader.close();
}
}
solr配置IK Analyzer分词器实例:
1、下载IKAnalyzer分词器ikanalyzer-solr6.5.zip。
2、解压压缩包,其中有ext.dic、IKAnalyzer.cfg.xml、stopword.dic、ik-analyzer-solr5-5.x.jar和solr-analyzer-ik-5.1.0.jar。
ext.dic为扩展字典
stopword.dic为停止词字典
IKAnalyzer.cfg.xml为配置文件
solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar为分词jar包。
3、需要将ext.dic、IKAnalyzer.cfg.xml、stopword.dic保存到solr/WEB-INF/classes目录下。ik-analyzer-solr5-5.x.jar和solr-analyzer-ik-5.1.0.jar放到solr/WEB-INF/lib目录下
4、在managed-schema文件中配置分词器IK
<fieldType name="text_cn" class="solr.TextField"> <analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
Ansj
Ansj介绍
Ansj中文分词是一款纯Java的、主要应用于自然语言处理的、高精度的中文分词工具,目标是“准确、高效、自由地进行中文分词”,可用于人名识别、地名识别、组织机构名识别、多级词性标注、关键词提取、指纹提取等领域,支持行业词典、用户自定义词典。
Ansj分词用到的算法
- 全切分,原子切分;
- N最短路径的粗切分,根据隐马尔科夫模型和viterbi算法,达到最优路径的规划;
- 人名识别;
- 系统词典补充;
- 用户自定义词典的补充;
- 词性标注(可选)
添加自定义词典
Ansj已经实现了用户自定义词典的动态添加删除,当然,也支持从文件加载词典。
从硬盘加载用户自定义词典的方法:
用户自定义词典默认路径:项目目录/library/userLibrary/userLibrary.dic
格式为:[自定义词] [词性] [词频],如:csdn创新院 userDefine 1000,中间用TAB键隔开
原分词结果:[csdn, 创新, 院, 是, 一个, 好, 公司] 增加词典后:[csdn创新院, 是, 一个, 好, 公司]
paoding
庖丁系统是个完全基于lucene的中文分词系统,因而它就是重新了一个analyer,叫做PaodingAnalyzer,这个analyer的核心任务就是生成一个可以切词的TokenStream这些都是lucene的结构设计,如果要和lucene一起使用就要这么写。
庖丁系统中的TokenStream就是PaodingTokenizer,它提供了我们用于分词的核心方法
next,它每次调用的时候返回切好的一个词。它采用了一个迭代器来进行的缓存,因而它不
是每次调用都会去拿出一堆刀来进行切词,它一般会一次切一堆然后将它保存下来,然后等
取完了再切第二次。
切词的时候它是直接调用了knifebox的dissect方法来进行切词的
knifebox是个刀盒子,它有一个刀的数组,它的dissect方法会调用刀的assignable方法
来决定是否可以用这个刀来切,如果用一个刀切了,但是没有切出任何词,即刀返回的最后切词的位置与开始位置一样则换下把刀切,如果切出了词,那么就直接返回最后切的位置,再不换刀切了,同时等待下一次切词。
在这个系统中还有paoding和SmartKnifeBox两个子类他们都是继承knifebox,但是它们只是做了一些简单的检查工作,主要工作还是由这个基类来完成。
分词策略的问题,我们在代码中看见庖丁系统的分词,它在分词的时候尽量将多的词语分出来,但是在PaodingAnalyzer发现它是有两种mode,一种是MOST_WORDS_MODE,一种是MAX_WORD_LENGTH_MODE,从字面上就可以看出它们的策略,前者是表示尽可能多的分词,即“华中科技大学”直接分为“华中/华中科技/华中科技大学/科技/大学/”,在CJKKnife中
当它遇到“华中”的时候就会开始collect,然后它将移动结尾,在分出“华中科技”和“华中科技大学”,这样“华”开头的就切完了,然后它将跳出小循环,进入下一轮大循环,移动开头位置,即“中”字,继续采用这个策略来切词,这样可以分出像上面那么多的词来,而这种方式用在索引的时候最好,可以保证索引中有尽可能多的关键词,这样找到的机会就大些。如果采用后一种mode,它将直接将上面分出的“华中/华中科技/华中科技大学/科技/大学/”只将最长的一个collect了,而前者会将它们全部collect。
前一节简单的提到了分词时候的两种策略,这两种策略的实现实际上是采用使用不同
的collect来实现的,MostWordsTokenCollector对应于最多词策略,MaxWordLengthTokenCollector对应于最长词的策略。在最长词策略中,它是采用将前词分解的词先不要记录下来(保存在list中)而是将它作为候选,如果后面的词与它有一样的开头并且比它长,就替换它,如果和它有一样头的所有词都没有它长则将它记录下来(加入List中)。
至于这个mode策略的选择,它是在PaodingAnalyzerBean中进行的,它在PaodingAnalyzer的init函数中调用了父类PaodingAnalyzerBean中的setmode方法设置mode,同时它产生了一个相应的classtype,最后根据这个classtype来通过反射生成一个collect传入PaodingTokenizer,供它使用。
CJK刀是庖丁解牛的主要的一个切词的刀,它的效率决定了整个中文分词系统的好坏。
CJK刀同样会先调用assignable函数来判断一下当前的字符是否适合使用此刀,这个函数是所有刀所必须调用的它是庖丁系统中重要的一部分,它通常在发现当前一个字符时候使用此刀的时候会使用一个循环一次记录下所有适合的字符在Beef中的启始位置,以便一次用这个刀来切分这一段字符串。
接着它就要开始正式的处理字符串。由于中文分词的是以词典为中心,因而它会不断的截取词语来在词典中进行比较。首先它将确定截取词语的开始位置和结束位置,得到这个词语后,它将直接放入词库中进行比较,如果在词库中的话,它将collect,并将孤立词的开始位置和当前截取词的开始位置之间的部分作为孤立词进行分解。同时它将继续移动结束位置,也就是说将词的开始部分不动,延长词语的长度,如“华中科技大学”,发现了"华中"这个词后,它将继续找“华中科”这个词,这个词显然不在词库中,但它却是一个词的开头,因而它不能确定为孤立字符串,如果发现它不是一个词的前缀,那么就将孤立字符串的开始位置和当前词语的开始位置设置为确定的词典词语的结束位置。但当它发现孤立字符串的开始位置为不是-1,也就是说前面几个字符都是孤立的,而且当前字符也是孤立的,则不要移动孤立字符串的开始位置,只移动当前词语的开始位置。
如果延长的词语仍然是一个词语则将它collect,同时继续移动词语的结束位置。
如果确定开始切分孤立字符串则将对孤立字符串进行二分的切分,所谓二分的切分,基本是二个字一切,"XY"切为"XY","X"切为"X","WXYZ"切为
"WX/XY/YZ","XYZ"切为"XY/YZ"。
Paoding分词过程中词典是相关重要的一环,其特性主要有:
(1)多词典支持,词典功能区分;
(2)词典加载入内存使用,使用预加载和Lazy Mode模式;
(3)根据分词模式,对词典进行二次编译;
(4)词典变更侦测,当词典文件发生变化时,可以重新加载词典。
