


一、索引分类
索引可以帮助人们提高在查询时的效率,通过查询索引可以锁定到查询范围,从而获取数据。下面的截图为没有使用索引时的执行情况。
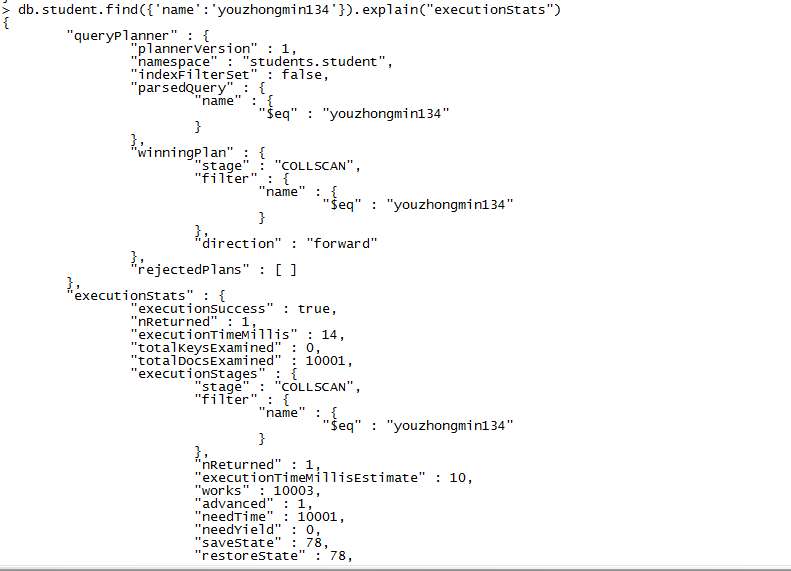
如果需要查看查询的运行详情,可以通过db.collection.find().explain(verbose)来查看,verbose有三种模式,分别为queryPlanner模式、executionStats模式、allPlansExecution模式。三种模式返回的信息逐次细化。我们可以看到通过name查询时耗时14毫秒。如果添加索引后呢?我们可以通过多种索引进行验证。
1、单字段索引
单字段索引是有一个字段作为索引的对象,单字段索引的创建如下:
db.collection.ensureIndex({"field":1}) //我们通过ensureIndex命令在field上添加的索引是升序索引,有1来控制,如果需要添加降序索引,只需将1改为-1。我们在name上创建索引后再进行查询,返回结果如下:
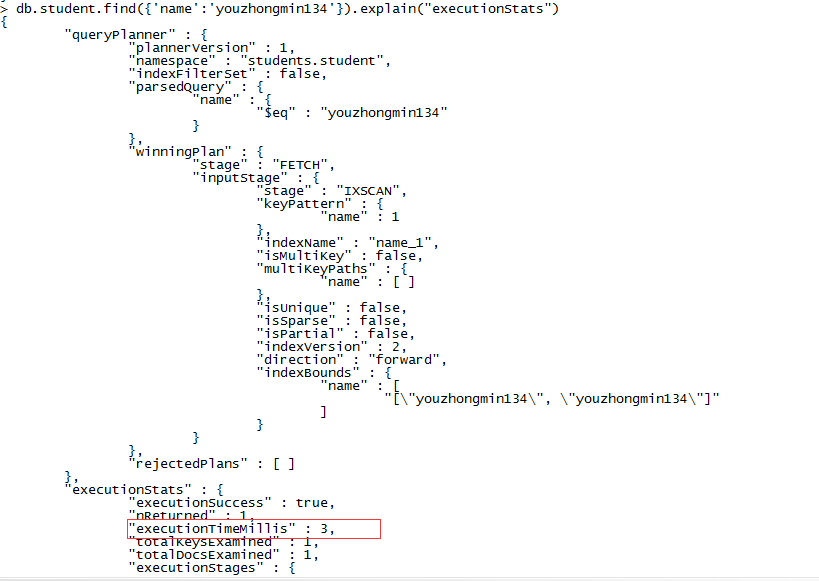
如上图所示,我们在通过索引查询所耗时为3毫秒,大大降低了查询时间。
2、复合索引
复合索引是有多个字段组合起来,构建一个索引表,在建立索引后,查询数据库时,如果有索引存在,会将索引加载到内存。查询的内容为映射时,如果索引正是映射部分,无需从数据库查找文档。如果不是映射部分,需要通过索引中的文档存储地址直接查找文档内容。创建索引的格式如下:
db.collection.ensureIndex({"field1":1/-1,"field2":1/-1,...,"fieldn":1/-1}) //我们通过ensureIndex命令在field上添加的索引是升序索引,有1来控制,如果需要添加降序索引,只需将1改为-1。
(1)在没有使用使用复合索引时,通过name和age查询的结果如下图所示:


可以看到在没有索引时的查询需要耗时12毫秒。
(2)使用复合索引查询结果


通过复合索引的查询,耗时几乎为0,所以在有多个条件进行查询时,可以建立复合查询来提高效率。
(3)复合索引中的字段颠倒后的结果


在使用的查询条件中将复合索引的顺序颠倒后,索引对查询没有起到任何作用。这是因为查询在执行时首先匹配索引的开始,逐次匹配。如果复合索引的第一个字段匹配成功后,才会执行第二个字段的匹配。
(4)使用符合索引的部分查询
我们在查询时,可能只涉及到一个字段的查询条件,如果查询的条件是复合索引的部分字段,查询效果如何呢。首先来验证一下。
使用复合索引的前半部分,例如我们在查询name='youzhongmin12'的个人信息时,查询结果如下,耗时4毫秒。


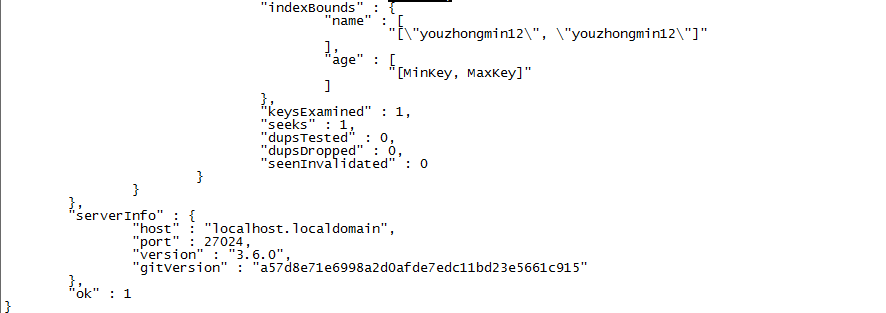
使用复合索引的后半部分,例如我们在查询age=20的个人信息时,查询结果如下,耗时11毫秒。

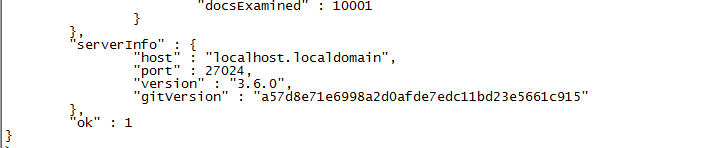
通过以上部分索引的使用结果,可以看到,在查询时查询条件只要是复合索引的前半部分就可以继续使用复合索引。
3、复合索引的原理
复合索引的排列顺序是逐个字段排序,首先按照第一个字段排序,如果字段值相同,就会按照第二个字段排序,索引在查询时,首先查找与第一个匹配的索引字段值,如果有多个,就会与第二个字段进行匹配。例如创建的索引是db.student.ensureIndex({"name":1,"age":1}),则索引表的排列顺序为:
| NAME,AGE | 位置信息 |
| youzhongmin3,21 | post1 |
| youzhongmin4,22 | post2 |
| youzhongmin5,20 | post3 |
| youzhongmin6,20 | post4 |
| youzhongmin7,23 | post5 |
| youzhongmin8,21 | post6 |
| youzhongmin9,22 | post7 |
| youzhongmin9,23 | post8 |
| youzhongmin10,24 | post9 |
如果查询{“name”:"youzhongmin9",“age”:22}的文档,首先按照索引的第一个字段进行查找,如果有多个,可以通过索引的第二个字段进行匹配,从而找到文档的指定位置,返回给客户端。有上图的索引结构可以看出,对所有匹配索引前缀的查询都可以利用复合索引,例如查询条件为{"name":"youzhongmin9"}。但是查询条件复合后半部分时,无法使用复合索引。同时查询条件为复合索引的部分字段且颠倒查询顺序,也无法利用复合索引。
4、哈希索引
哈希索引主要是通过某一个字段的哈希值来创建索引,哈希索引只能进行字段完全匹配的查询也就是说只能利用等号进行查询,一般来说哈希索引比普通索引的查询速度快。创建哈希索引的格式如下:
db.collection.ensureIndex({filed:’hashed’});
哈希索引的执行结果



由上图返回的执行结果,可以看到哈希索引的执行时间几乎为0毫秒
二、索引属性
1、唯一索引
唯一索引可以保证所指定的索引在文档中的值唯一,如果希望文档中的某一个值唯一,可以使用唯一索引来限制。唯一索引的格式如下:
db.collection.ensureIndex({filed:1/-1},{"unique":true});
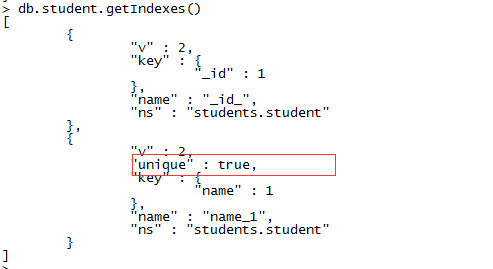
2、稀疏索引
只对有值的字段创建索引,没有值的字段不需要索引。该属性可以联合唯一索引一起使用,一旦提供了这个字段的值就必须是唯一的。创建稀疏索引的格式如下:
db.collection.ensureIndex({filed:1/-1/hashed}{"unique":true,"sparse":true});
三、索引技巧
1、索引减少了内存访问,提高了速度。
在数据量比较大的情况下,为了提高磁盘的访问速度,可以对查询条件的字段创建索引,只将索引加载到内存,查询时只查询索引,通过索引指向的文档位置获取文档。否则的话,需要将全部的文档加载到内存逐个比较,由于内存是有限的,在大数据量的情况下,安页分批加载到内存,这样就会降低对数据的访问速度。
2、不要到处创建索引
创建的索引表,和文档表没有任何区别,创建索引也会占用大量的磁盘空间。索引在提高磁盘的读取速度的同时,在进行写操作时需要将新文档的索引值插入索引表,这也会大大降低对集合的写操作。索引的作用是在查询时返回集合的一小部分文档数据,如果返回的结果集几乎接近集合的一般,也就没有必要使用索引。
3、索引覆盖查询
如果在查询时指向返回部分字段且这些字段在性能允许的情况下,可以将这些字段放到索引中,在查询时mongo只会去索引中查询复合条件的数据,将索引中的字段值直接返回给客户端,无需通过索引中指向文档的指针获取文档。从而提高了查询效率。
4、使用复合索引加快查询
一般来说尽量创建复合索引而不是单字段索引,因为在查询时,查询条件只要是符合复合索引的字段顺序或者与复合索引的前缀匹配,就可以利用复合索引进行查询。
5、通过建立分级文档加快扫描
在没有对分档进行分级时的结构,在进行{"zip":"1003"}的文档查询时需要遍历每个文档的每个字段,无分级文档的结构为下图


分级后的文档结构为下图

在进行响应的查询时,查询语句也会变为{"address.zip":"1003"},这时只会查询_id、name和online字段,最后在address中匹配zip。这样会大大降低文档的扫描字段。
6、AND查询
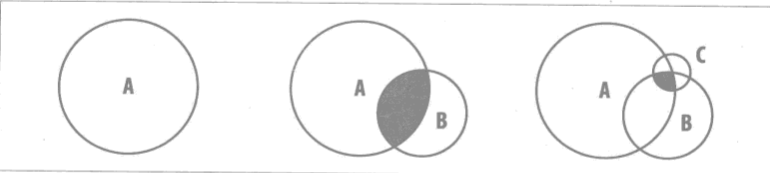
现在有A、B、C三个查询条件,使用and进行合并文档结果。这在种情况下,可以将条件比较苛刻的放在最前面,这样可以减少查询数量,提高查询效率。查询条件比较宽泛为开头和比较苛刻为开头两种步骤示例图:
查询条件比较宽泛为开头
比较苛刻为开头

由上图可以看出,以查询条件比较苛刻的为开始,可以减少文档的查询范围。
7、OR查询
or查询与and查询的条件顺序正好相反,首先将查询范围比较大的放在查询的开始。因为每次查询都要查询不在结果集之内的文档。查询范围从大到小,可以逐次缩减查询范围。查询范围从大到小和从小到大的两种情况。
查询范围从大到小的方式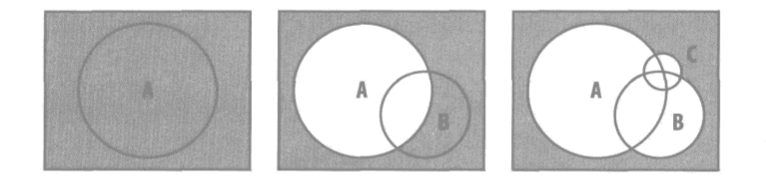
查询范围从小到大的方式
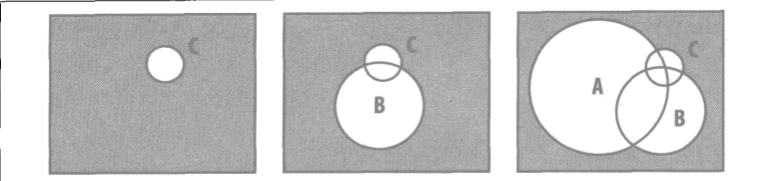
深色部分表示需要每次查询的范围,查询范围从大到小的方式可以看出每次查询的范围在不断减小。从小到大的查询范围可以看出查询范围没有明显变化。
8、排序与索引的使用
在使用排序时,排序的关键字为索引或者索引的前缀,这样可以调高查询效率,因为引用了索引。但是排序的关键字的顺序和升序/降序都与索引的顺序与升序/降序有关。一旦排序关键字没有使用索引或者不符合索引的规则,就会导致整个查询无法使用索引。
索引管理
1、创建索引
db.collection.ensureIndex({filed1:1/-1/’hashed’,...,filedn:1/-1/’hashed’},{"unique":true,"sparse":true});
2、查看索引
db.collection.getIndexes()
3、查看索引大小
db.collection.totalIndexesSize()
4、删除索引
db.collection.dropIndex("index_name")
5、删除所有索引
db.collection.dropIndexes()
6、重置索引
db.collection.reIndex()
