


一、复制集
问了能够保证redis数据库中的数据不会因为在服务器出现故障,导致数据丢失,现在需要对redis数据库进行主从设置。保证主服务器数据丢失,可以通过从服务器对数据进行恢复
1、安装
对redis数据库的主从配置只需在配置文件中配置参数即可。首先需要对主从服务器选取端口号,一个主数据库实例配置6379端口,两个从数据库实例配置6380和6381端口。在配置主从实例时,只需在从实例配置slaveof <masterip> <masterport> 参数即可。
安装redis实例:
1、从官方网站下载安装包redis-3.0.6.tar.gz
2、对文件进行解压
tar xzvf redis-3.0.6.tar.gz
3、redis的运行环境的工具安装
yum install gcc
yum install gcc-c++
4、进入安装文件
cd redis-3.0.6
5、编译
make
6、安装到指定目录
make PREFIX=/usr/local/redis01/redis install
启动实例:
redis-server ./6379.conf
关闭实例:
redis-cli -p 6379 shutdown
2、配置
配置参数如下:
daemonize yes //是否后台执行redis实例
pidfile /usr/local/redis01/redis/redis.pid // 线程文件的存放位置
port 6379 //实例运行的端口号
logfile "/usr/local/redis01/redis/6379.log" //实例运行时的记录日志
save 900 1 //没N秒执行M次数据操作,就会快照一次
save 300 10 //..........
save 60 10000 //...........
dbfilename dump.rdb //快照执行时生成的文件
dir /usr/local/redis01/redis/ //快找执行时,生成的文件位置
slaveof <masterip> <masterport> //主从集群时,只需在从实例的配置文件中配置主实例的ip和端口
slave-read-only yes //从实例是否为制度模式
timeout 300 //当 客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
maxclients 128 //设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
maxmemory <bytes> //指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
主从实例的分配:
主实例
创建目录6379 mkdir -p /usr/local/redis/6379
将bin下的redis.conf文件复制到6379目录下,并改名为6379.conf scp redis.conf /usr/local/redis/6379/redis.conf mv redis.conf 6379.conf
从实例
创建目录6380 mkdir -p /usr/local/redis/6380
将bin下的redis.conf文件复制到6379目录下,并改名为6380.conf scp redis.conf /usr/local/redis/6380/redis.conf mv redis.conf 6380.conf
创建目录6381 mkdir -p /usr/local/redis/6381
将bin下的redis.conf文件复制到6381目录下 scp redis.conf /usr/local/redis/6381/redis.conf mv redis.conf 6381.conf
查看redis主从配置:
info replication
3、复制集的原理
主从复制集的同步分为两步执行,初始同步和增量同步。
全量同步:
在初次开启主从复制集,从数据库会向主数据库发送SYNC命令,主数据收到命令后,开支执行快照操作,执行结束,会将快照和缓存中的操作全部发送给从数据库。再次期间主从数据库都会继续接收来自客户端的请求。在初始同步结束,会进入下一阶段,增量同步。
增量同步:
1、在初始同步阶段,从数据库就会存储主数据库的ID,每个运行实例都有一个唯一的ID作为标识。
2、在主数据库将数据同步到从数据库的同时,会将该操作存入队列,并记录下该操作在队列的偏移量。
3、从数据库会将该操作的偏移量也会记录在本地。
4、一旦出现主从重连,从数据库会将主数据库的ID与命令偏移量一并交给主数据库。通过ID来判断该从数据库是否是自己的从数据库。如果不是返回错误信息。如果是,需要判断是否要执行增量同步还是全量同步,如果该命令的偏移量在主数据库的队列中,可以将队列中的命令取出执行增量同步。如果该命令偏移量没有存储在队列中,需要执行全量同步。
挤压队列:
挤压队列是一个固定长度的队列,队列的长度决定的主从断掉后,需要多长时间可以实现全量同步。队列越长允许主从重连执行增量同步的时间就会越长。repl-backlog-size来控制队列大小。
4、读写分离
为了减轻客户端访问redis数据库的压力,可以通过主从数据库共同分担压力。为了保证数据的一致性,可以只有主数据库提供写服务,而主从可以同时读服务。
5、故障恢复
在主数据库出现崩溃时,可以手动的将从数据库设置为主数据库,命令为 SLAVEOF NO ONE。
在重启主数据库后,将主数据库设置为新的主数据库的从数据库,命令为SLAVEOF
二、哨兵模式
哨兵模式只不过是为主从复制集添加监控,并在出现故障时能够,自动的将故障转移,保证系统的正常运行。
1、结构图
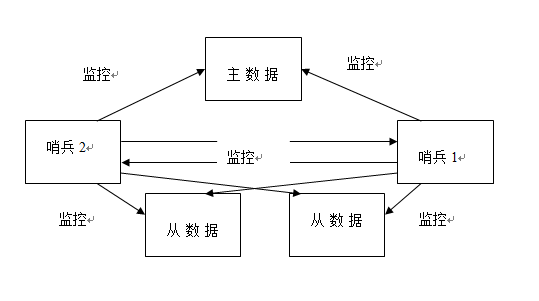
在哨兵模式下,哨兵不仅可以监控主从数据库,也可以监控其他哨兵的运行情况。如果主数据库下线,哨兵会在从数据库中找出一个转换为主数据库。其实哨兵只是一个进程,主要用来实现监控和故障转移。
2、哨兵模式搭建
1、创建哨兵目录
mkdir /usr/local/redis/sentinel6382
2、复制bin目录下的sentinel.conf文件到6382目录下
scp sentinel.conf /usr/local/redis/sentinel6382
3、修改sentinel.conf配置文件
sentinel monitor mymaster ip port number
mymaster为需要监控的主数据库的名字 ip为主数据库的地址 port为主数据库占用的端口 number为在主数据库宕机后,超过number票即可将从数据库选为主数据库。在哨兵配置文件中只是配置了主数据库的基本信息,没有配置从数据库的基本信息,是因为在与主数据库取得联系后,主数据库会返回给哨兵其他从数据库的基本信息,无需配置。
sentinel down-after-milliseconds 6000
6000表示哨兵多长时间,进行一次数据库的监控,用以发现实例是否正常运行。单位为毫秒,如果大于1秒就以1秒为间隔,如果小于1秒就以实际时间为间隔。
4、搭建主从数据库,由于主从数据库的搭建在前一接已经介绍,本节不再详细介绍
5、启动哨兵进程
redis-sentinel sentinel.conf
6、启动主从数据库实例
3、哨兵的原理
哨兵的运行机制主要分为两步走:建立监控网,故障恢复。
建立监控网:
在哨兵初次运行时,会通过INFO指令向主数据库发送信息,主数据库会将自己和从数据库的基本信息返回给哨兵。此后,每个10秒会向哨兵所掌握的主从数据库发送INFO命令,获取数据库的基本信息,查看主数据库是否发送转移,数据库的基本信息是否有更新。
哨兵向主从数据库的_sentinel_:hello频道发送自己所掌握的主从数据库和哨兵的基本信息,其他哨兵会接收到该信息,并对信息做出判断,查看与自己所掌握的信息是否一致。如是否有新的哨兵加入,如果有,需要将新的哨兵基本信息加入本地列表。此后哨兵会每个2秒向频道发送一次所掌握的复制集信息。
哨兵在掌握了主从数据库的基本信息后,每隔1秒会向主从数据库发送PING指令,用以监控数据库是否正常运行。
故障恢复:
哨兵发送PING指令到数据库,在指定的时间内没返回响应,那么哨兵就会认为该数据库主观下线,如果是主数据库,同时会向其他哨兵发送指令,询问其他哨兵是否认为该数据库下线,如果达到一定数量的哨兵认为该数据库下线,哨兵会认为数据库客观下线。
在发现主数据库客观下线后,哨兵A会向其他哨兵推荐自己为零头哨兵,如果其他哨兵没有选举其他领头哨兵,则会同意A为零头哨兵。如果发现超过一半或者一定数量的哨兵选举A为领头哨兵,则A就会成为领头哨兵。当有多个哨兵同时参选领头哨兵,并没有一个哨兵当选时,需要等待一段时间重新发去参选请求。
在选出领头哨兵后,会选择优先级高的从数据库为主数据库。如果有多个数据库为相同优先级,需要通过复制队列的名利偏移量来判断。
