排序之快速排序 → 基本版实现
前言
本篇博客是在伍迷兄的博客基础上进行的,其博客地址。
希尔排序相当于直接插入排序的优化,它们同属于插入排序类,堆排序相当于简单选择排序的优化,它们同属于选择排序类。而快速排序其实就是冒泡排序的升级,它们都属于交换排序类。即它也是通过不断的比较和移动交换来实现排序的,只不过它的实现,增大了记录的比较和移动的距离,将关键字较大的记录从前面直接移动到后面,关键字较小的记录从后面直接移动到前面,从而减少了总的比较次数和移动交换次数,而不是像冒泡排序那样左右两两进行比较和交换。
说白了,其实就是在冒泡排序的基础上加入了记忆的功能,类似堆排序于简单选择排序,冒泡排序两两左右比较之后是没有记住两者大小关系的,下轮比较的时候两者比较还是如他们第一次比较一样,彼此不认识;而快速排序,他选取了一个枢纽值,使得枢纽值左右两边的元素有个大小关系,那么枢纽值左边的就不需要与枢纽值右边的进行比较了。
基本思想
通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序的目的;就是选择一个关键字,通过一趟排序(进行比较和移动)使得关键字的左边都比他小(或者大)、右边都比他大(或者小),然后对他的左边元素和右边元素分别进行排序,以此直至整个序列有序。
从字面可能不太好理解,那么我们来看代码,假设初始序列为{5,3,7,9,1,6,4,8,2}。
代码实现
/** * 快速排序 * @param arr */ private static void quickSort(int[] arr) { qSort(arr,0,arr.length-1); } /** * 对序列arr中的子序列arr[low..high]作快速排序 * @param arr * @param low * @param high */ private static void qSort(int[] arr, int low, int high) { int pivotKey; if(low < high){ // 找到枢纽值的位置,此时arr[low,pivotKey-1]都小于(大于)arr[pivotKey],arr[pivotKey+1...high]都大于(小于)arr[pivotKey] pivotKey = partition(arr,low,high); qSort(arr,low,pivotKey-1); // 对arr[low...pivotKey-1]进行快速排序 qSort(arr,pivotKey+1,high); // 对arr[pivotKey+1...high]进行快速排序 } }
这一段代码的核心是“pivotKey = partition(arr,low,high);”,在执行它之前,arr的数组值为{5,3,7,9,1,6,4,8,2}。partition函数要做的,就是先选取当中的一个关键字,比如选择第一个关键字5,然后想尽办法将它放到一个位置,使得它左边的值都比它小,右边的值比它大,我们将这样的关键字称为枢轴。
在经过partition(arr,0,9)的执行之后,数组变成{2,3,4,1,5,6,9,8,7},并返回值枢纽值的下标4给pivotKey,数字4表明元素5放置在数组下标为4的位置。此时,程序把原来的数组变成了两个位于元素5左和右的小数组{2,3,4,1}和
{6,9,8,7},然后分别对子序列进行快速排序。
到了这里,应该说理解起来还不算困难。partition的作用相当于赋予了程序记忆功能,从而来提高速度。下面我们就来看看快速排序最关键的partition方法实现是怎么样的。
1 /** 2 * 寻找枢纽值的下标,并返回 3 * 交换arr[low...high]中的元素,移动枢纽值到正确的位置 4 * @param arr 5 * @param low 6 * @param high 7 * @return 8 */ 9 private static int partition(int[] arr, int low, int high) { 10 int pivotValue = arr[low]; // 选取arr[low]当作枢纽值 11 // 从两端向中间扫描,使枢纽值移动到正确的位置 12 while(low < high){ 13 while(low<high && arr[high]>=pivotValue){ 14 high --; 15 } 16 swap(arr,low,high); // 将比枢纽值小的记录交换到低端 17 while(low<high && arr[low]<=pivotValue){ 18 low ++; 19 } 20 swap(arr,low,high); // 将比枢纽值大的记录交换到高端 21 } 22 return low; 23 }
执行过程模拟
整个快速排序关键点在于partition方法,那么我们就来模拟一下这个方法的执行过程
1)初始时,low=0,high=8,pivotValue=arr[low]=5,如下图

2)执行13~15行,arr[high]>=pivotValue不满足,跳出循环,执行16行,交换5和2,此时,序列如下图

执行17~19行,循环条件满足,low++后,low=1,继续执行循换,条件依然满足,low++,low=2,继续执行循环,此时循环条件不满足,跳出循环,执行20行,交换arr[low=2]和arr[high=8]即7和5,过程如下图
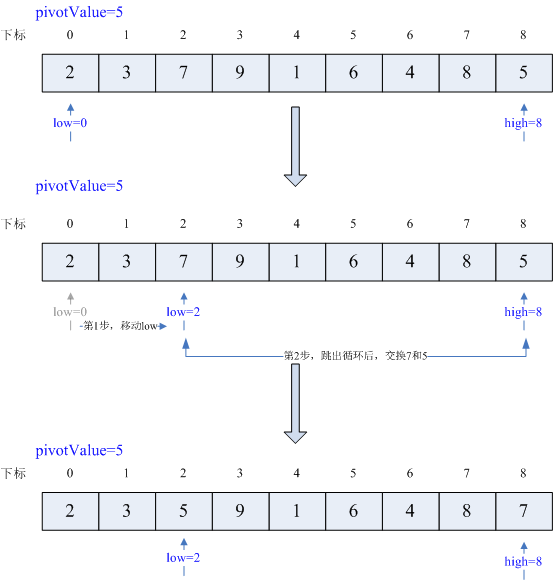
3)内部循环结束,继续执行外部循环,回到12行,low<high,继续执行内部循环,执行13~15行
条件满足,执行循环体,high--,high=7,继续执行循环,条件满足,执行循环体,high--,那么high=6,继续执行循环,条件不满足,交换arr[low=2]和arr[high=6],即交换5和4,执行过程如下
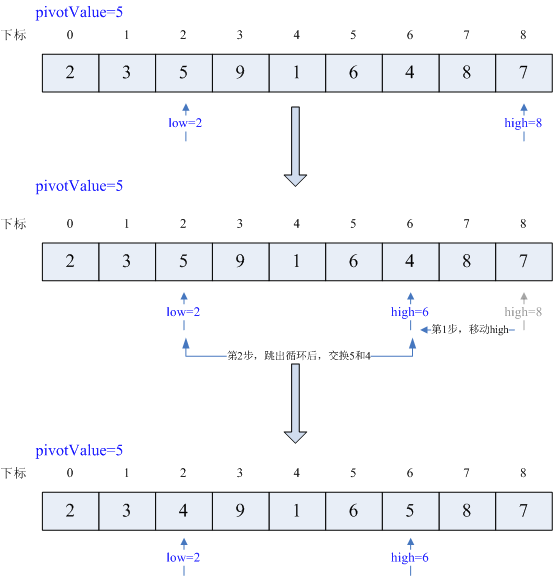
接下来执行17~19行,循环条件满足,low++,那么low=3,继续执行循环,条件不满足,跳出循环,执行20行,交换arr[low=3]和arr[high=6],即交换9和5,执行过程如下

4)内部循环结束,继续执行外部循环,条件满足,继续执行内部循环
执行13~15行,条件满足,high--,那么high=5,继续执行循环,条件满足,high--,此时high=4,条件不满足,跳出循环,执行16行,交换arr[low=3]和arr[high=4],即交换5和1,执行过程如下如
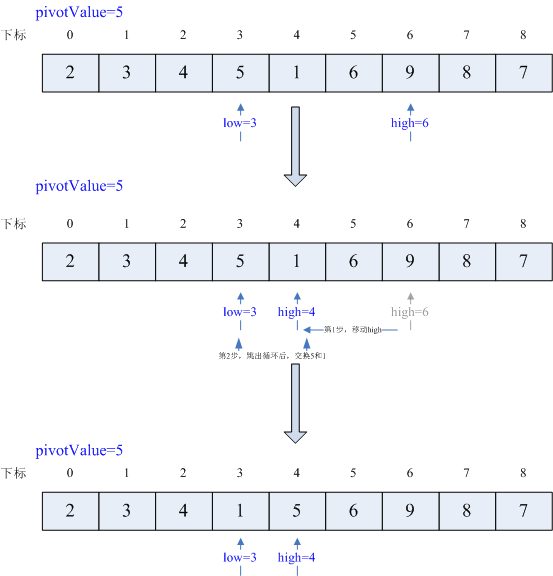
接下来执行18~19行,条件满足,low++,那么low=4,继续执行循环,条件不满足,跳出循环,交换arr[low=4]和arr[high=4],即交换5和5,过程图就不提供了,比较简单容易理解
5)内部循环结束,继续执行外部循环,条件不满足,跳出外部循环,返回low=4,自此partition方法执行完毕,那么我们的关键字5已经找到正确的位置即4,并将该位置的索引4返回,序列为{2,3,4,1,5,6,9,8,7}
子序列{2,3,4,1}和{6,9,8,7}分别进行快速排序,过程与上面一样,这里就不做演示了,各位看官老爷们自行去模拟!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号