数据结构之堆 → 不要局限于堆排序
开心一刻
一天,一个演讲老师正在演讲正确的爱情观
情到深处,老师激动的说道:你一个月挣三千,凭什么让一个月挣三万的人喜欢你?
结果底下站起来一个女孩,说道:因为我骚呀

堆结构
定义:堆就是用数组实现的完全二叉树,并且根据堆属性来排序,决定节点在树中的顺序
信息量是不是有点大?

欸,有这些疑问就对了,我们慢慢往下看
堆属性
堆分为两种:大顶堆和小顶堆,也称最大堆和最小堆
在大顶堆中,父节点的值大于等于左右孩子节点的值。在小顶堆中,父节点的值小于等于左右孩子的值。这就是所谓的 堆属性 ,并且这个属性对堆中的每一个节点都成立
注意:堆属性只限制了父节点与其左右孩子的大小关系,并没有限制左右孩子之间的大小关系
我们看个例子

上图中父节点有两个:9 和 5,9 比 5 和 7 都大,5 比 3 和 2 都大,满足大顶堆的属性,所以它是一个大顶堆
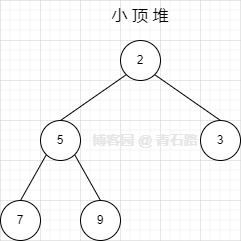
上图中父节点有两个:2 和 5,2 比 5 和 3 都小,5 比 7 和 9 都小,满足小顶堆的属性,所以它是一个小顶堆
由此我们可以得出:大顶堆的根节点存放的肯定是最大值,小顶堆的根节点存放的肯定是最小值
大顶堆能够快速得到最大值、小顶堆能够快速得到最小值,但也就仅此而已了。堆中其他节点的顺序是未知的,大顶堆中不能确定最小值,小顶堆中不能确定最大值
数组如何实现完全二叉树
用数组来实现完全二叉树,是不是感觉很怪?常规的树的节点由 数据+指向孩子节点的指针 组成,数组如何表现 指向孩子节点的指针?
怪不代表不能,不仅能实现,而且在时间和空间上还很高效
我们以前面的大顶堆示例为例,通过数组这样存储: [9, 5, 7, 3, 2] ,仅此而已,不需要任何额外的空间!
那么关键问题来了,既然没有使用指针,那么如何确定某个节点的父节点以及子节点了?答案就是: 索引映射
假设某个节点的索引是 i,那么它的父节点和子节点在数组中的位置可以通过如下公式获取

注意看左右孩子的公式,不难得出:某个节点的左右孩子处于相邻位置
我们将公式放到大顶堆示例中验证一下
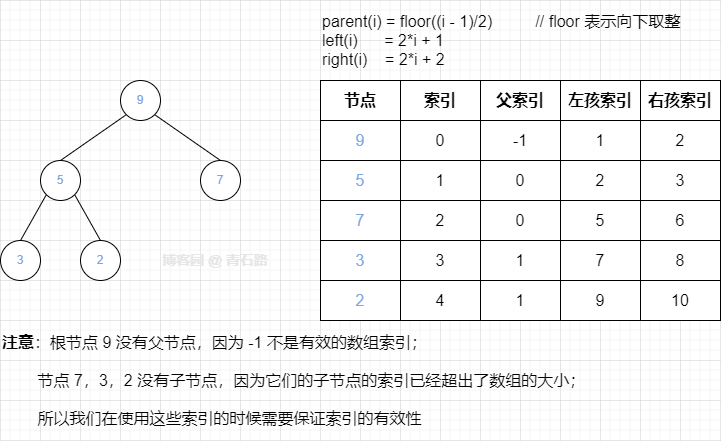
完美契合,只是需要注意下索引的有效性
堆与二叉搜索树的区别
从定义上来讲,堆和二叉搜索树还是有区别的,所以堆并不能取代二叉搜索树
相似点就不梳理了,我们重点来看下它们的区别
节点顺序。二叉搜索树中,左孩子必须比父节点小,右孩子必须比父节点大。但是堆中并非如此,堆中只需要保证父节点比左右孩子都大(小)
内存占用。二叉搜索树除了需要存储数据,还需要存储指向左右孩子的的指针。但堆仅用一个数组来存储数据,而不使用指针
平衡。二叉搜索树在平衡的情况下,其大部分操作的时间复杂度是 O(log N) ,非平衡的极端情况下,二叉搜索树退化成一个链表,大部分操作的时间复杂度是 O(N)
堆就是数组实现的完全二叉树,完全二叉树就是平衡二叉树,所以堆肯定是平衡的
搜索。二叉搜索树本身就是为搜索而生,所以其搜索很快。而堆的目的是快速找到最大(小)节点,所以其搜索会很慢
堆操作
有两个原始操作: shiftUp 和 shiftDown 用于保证插入或删除节点后,堆仍然是一个有效的大顶堆或者小顶堆
上移 → shiftUp
在位置 k 处插入元素 x,将 x 逐层往根上移动,直至满足堆属性(仍是大顶堆或小顶堆)
假设初始大顶堆如下:
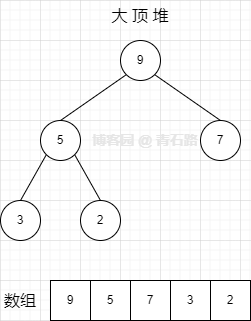
我们以它为例,来看两种情况
1、新插入元素:6,插入位置索引:5
索引 5 的父位置索引是 2,那么元素 6 的父元素是 7,7 比 6 大,仍是大顶堆,满足堆属性,操作完成
此时大顶堆如下
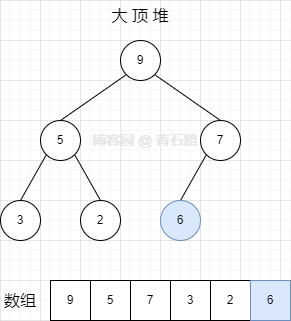
2、新插入元素:10,插入位置索引:5
索引 5 的父位置索引是 2,那么元素 10 的父元素是 7,7 比 10 小,不满足堆属性,元素 10 逐层往上移动,如下图

小顶堆是一样的处理方式,只是比较方式不一样而已,就不具体演示了
我们再来看下具体的代码实现

实现兼容了 自然比较器 和 自定义比较器 两种情况, 自然比较器 默认是升序排序
比较器 升序对应的是小顶堆,降序对应的是大顶堆
下移 → shiftDown
在位置 k 处插入元素 x,将 x 逐层往叶子上移动(下移),直至满足堆属性(仍然是大顶堆或小顶堆)。整个操作也称作 堆化(heapify)
假设大顶堆如下:

我们以它为例,来看看一个例子
假设我们需要将根节点 9 替换成 1,操作步骤是怎样的?
将 9 替换成 1 后,不满足大顶堆属性,需要调整,将节点 1 逐层向下移动,直至满足堆属性,如下所示
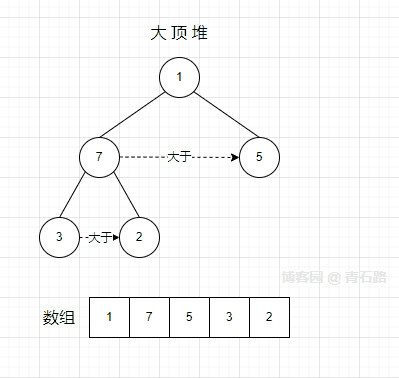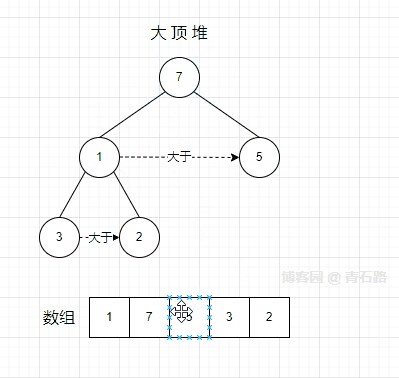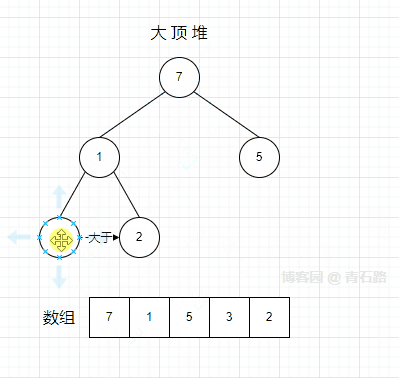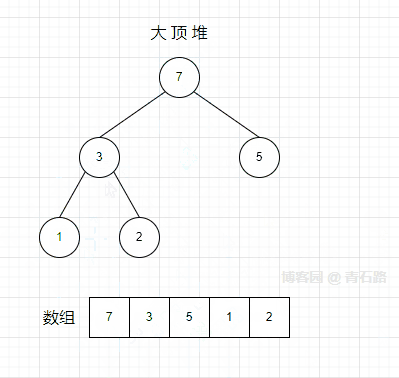
1、节点 1 在根节点的时候,取它的孩子节点中的大者(7) 与自身交换
2、节点 1 在索引为 1 的位置的时候,取它的孩子节点中的大者(3) 与自身交换
3、节点 1 来到叶子节点,操作完成
我们再来看看代码实现

基于 shiftUp 和 shiftDown ,还有很多其他的操作,我们慢慢往下看
insert
在堆的末尾添加一个新的元素,然后用 shiftUp 修复堆;代码如下

peek
获取根元素;如果是大顶堆则是获取最大值,如果是小顶堆,则是获取最小值

indexOf
查找元素的位置索引
因为堆不是为了快速查找而建立的,所以其时间复杂度是 O(N)

remove & removeAt
remove 是删除元素。为了将这个节点删除后的空位填补上,需要将最后一个元素移到根节点的位置,然后使用 shiftDown 方法来修复堆
removeAt 是删除指定位置的节点。将最后一个元素移到此位置,当它与子节点比较发现无序使用 shiftDown ,如果与父节点比较发现无序则使用 shiftUp

replace
将指定位置的元素替换成目标元素;当它与子节点比较发现无序使用 shiftDown ,如果与父节点比较发现无序则使用 shiftUp

buildHeap
构建初始堆,循环调用 insert 即可

使用场景
堆排序
这个可以说是大家最容易想到的堆的使用场景
过程如下:
1、以 0 ~ arr.length-1 元素进行堆化,那么 arr[0] 就是最大值(大顶堆)或最小值(小顶堆),然后将 arr[length-1] 与 arr[0] 进行交换
2、以 0 ~ arr.length-2 元素进行堆化,那么 arr[0] 就是最大值(大顶堆)或最小值(小顶堆),然后将 arr[length-2] 与 arr[0] 进行交换
3、以此类推,直至整个数组有序
如果是大顶堆,那么则是升序;如果是小顶堆,则是降序
以降序为例,我们来看下代码实现

优先队列
优先队列的底层实现就是:堆,有兴趣的小伙伴可以去看看你们的开发语言中优先队列的底层实现
Java 中是 PriorityQueue ,只要你们去看它的源码,你们就会发现我上述 堆操作 的代码实现和 PriorityQueue 的基本一致,你们懂的: 拿来主义

获取极值
快速得到最大值或最小值;这是由堆属性决定的,我们就不重复讲了
处理大数据量的 topN 问题,比如磁盘数据文件 10G,内存却只有 1G,如何统计出前 100 大的数据?
可以利用小顶堆:每次读取一个数与堆顶进行比较,若比堆顶大,则把堆顶弹出,把当前数据压入堆顶,然后调整小顶堆( shiftDown ),最终得到的小顶堆即为最大的100条数据
提升逼格
虽然很虚,也很飘,但真的提升逼格,面试的时候还真有用!
总结
堆属性
只强调了父节点与左右孩子节点的大小关系,并未要求左右孩子节点的大小关系
所以堆不是有序的,查找的时间复杂度 O(N)
堆操作
重点是上移操作 shiftUp 与下移操作 shiftDown ,其他操作都是基于这两个操作
使用场景
堆排序
优先队列
获取极值



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具