并发编程【四】锁和队列及生产者消费模型
锁和队列
1、锁multiprocessing-Lock
锁的应用场景:当多个进程需要操作同一个文件/数据的时候;
当多个进程使用同一份数据资源的时候,就会引发数据安全或顺序混乱问题。
为保证数据的安全性,多进程中只有去操作一些进程之间可以共享的数据资源的时候才需要进行加锁;
枷锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务进行修改,即串行的修改,没错速度式慢了,但牺牲了速度却保证了数据的安全;
模拟查票抢票:


import json import time from multiprocessing import Process,Lock """ 模拟查票/抢票 查票是不需要排队的,可以使用多进程,每个人都可以在同一时间查看 买票为避免多个进程操作同一个文件造成数据不安全,使用锁来避免多个进程同时修改同一个文件 """ def search_ticket(name): with open('piao',encoding='utf-8') as f: dic = json.load(f) print('%s查看余票为%s张票'%(name,dic['count'])) def buy_ticket(name): with open('piao', encoding='utf-8') as f: dic = json.load(f) time.sleep(2) if dic['count'] >= 1: print('%s买到票了'%name) dic['count'] -= 1 time.sleep(2) with open('piao','w',encoding='utf-8') as f: json.dump(dic,f) else: print('余票为0 %s没有买到票'%name) def user(name,lock): search_ticket(name) print('%s在等待' % name) # lock.acquire() # 拿钥匙取数据 # buy_ticket(name) # lock.release() # 归还钥匙 with lock: print('%s开始执行了' % name) buy_ticket(name) if __name__ == '__main__': lock = Lock() # 创建锁 lis = ['alex','wusir','taibai','eva_j'] for name in lis: Process(target=user,args=(name,lock)).start() 模拟查票/抢票

#加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲了速度却保证了数据安全。 虽然可以用文件共享数据实现进程间通信,但问题是: 1.效率低(共享数据基于文件,而文件是硬盘上的数据) 2.需要自己加锁处理 #因此我们最好找寻一种解决方案能够兼顾:1、效率高(多个进程共享一块内存的数据)2、帮我们处理好锁问题。这就是mutiprocessing模块为我们提供的基于消息的IPC通信机制:队列和管道。 队列和管道都是将数据存放于内存中 队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来, 我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可获展性。
2、进程之间的通信—队列multiprocessing.Queue
进程之间的通信:IPC(Inter-Process Communication)
multiprocessing.Queue可以完成进程之间通信的特殊队列
from multiprocessing import Queue def son(q): print(q.get()) # 从队列里面取值 if __name__ == '__main__': q = Queue() # 创建一个队列 Process(target=son,args=(q,)).start() q.put('wanhaha') # 往队列里放值 使用队列完成主进程与子进程的通信
1、队列是进程之间通信的安全保障,自带了锁 2、队列是基于文件家族的socket服务实现的 3、管道Pipe也是基于文件家族的socket服务实现的IPC机制 4、队列 = 管道 + 锁 5、管道没有锁,不安全
3、生产者消费模型
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。
为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
import time from multiprocessing import Queue,Process def producer(q): """ 生产者 :param q: :param name: :return: """ for i in range(10): time.sleep(0.2) q.put('泔水%s'%i) print('正在生产泔水%s'%i) def consumer(q,name): """ 消费者 :param q: :return: """ while True: s = q.get() if not s:break time.sleep(0.2) print('%s正在吃%s'%(name,s)) if __name__ == '__main__': q = Queue() p1 = Process(target=producer,args=(q,)) p1.start() c1 = Process(target=consumer,args = (q,'alex')) c1.start() p1.join() q.put(None) 向队列中添加None来结束消费者中的循环
import time import random from multiprocessing import JoinableQueue,Process def consumer(jq,name): while True: food = jq.get() time.sleep(random.uniform(1,2)) print('%s吃完%s'%(name,food)) jq.task_done() def producer(jq): for i in range(10): time.sleep(random.random()) food = '泔水%s'%i print('%s生产了%s'%('taibai',food)) jq.put(food) jq.join() if __name__ == '__main__': jq = JoinableQueue(5) c1 = Process(target=consumer,args=(jq,'alex')) p1 = Process(target=producer,args=(jq,)) c1.daemon = True # 守护进程 c1.start() p1.start() p1.join() 利用守护进程结束循环
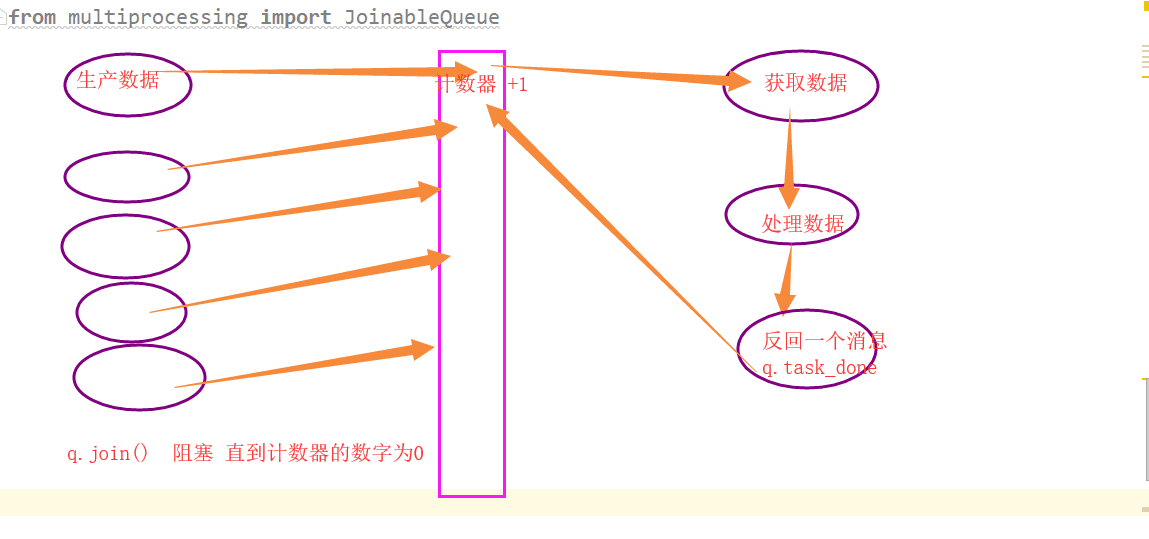
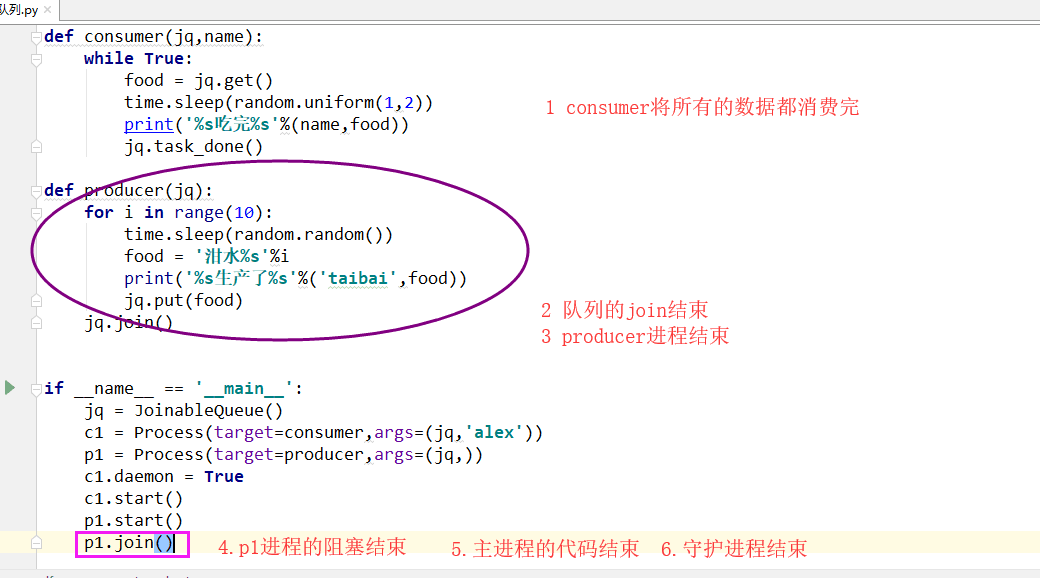
边生产边吃,供不应求时会get()阻塞住,直到生产者往队列里放有值才能继续吃,每吃一次都会向队列发送一个信号q.task_done()(相当于告诉队列我吃完一个了)此时队列中的计数器会减去一,只要队列中的计数器不为0,程序就会被q.join()阻塞住;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号