

增补博客 第八篇 python 中国大学排名数据分析与可视化
1.增补博客 第二篇 python 谢宾斯基三角型字符分形图形输出2.增补博客 第三篇 python 英文统计3.增补博客 第四篇 python 中文级联菜单4.增补博客 第五篇 python 电子算盘5.增补博客 第六篇 python 电子算盘6.增补博客 第七篇 python 比较不同Python图形处理库或图像处理库的异同点
7.增补博客 第八篇 python 中国大学排名数据分析与可视化
8.增补博客 第九篇 python 图书评论数据分析与可视化9.增补博客 第十篇 python 函数图形绘制10.增补博客 第十一篇 python 分段函数图形绘制11.增补博客 第十二篇 python大作业小说阅读器(1)爬取12.增补博客 第十三篇 python大作业小说阅读器(2)爬取13.增补博客 第十四篇 python大作业小说阅读器(3)显示文字函数14.增补博客 第十五篇 python大作业小说阅读器(4)html页面15.增补博客 第十七篇 python 模拟页面调度LRU算法16.增补博客 第十八篇 python 杨辉三角形17.增补博客 第二十篇 python 筛法求素数18.增补博客 第二十一篇 python 查找鞍点19.增补博客 第二十四篇 python 正整数的因子展开式20.增补博客 第二十二篇 python 牛顿迭代法21.增补博客 第二十三篇 python 对比Python中的列表、元组、字典、集合、字符串等之间异同22.增补博客 第十九篇 python 爬楼梯23.增补博客 第一篇 python 简易带参计算器24.增补博客 第十六篇 python 排列组合序列25.增补博客 第二十五篇 python 列举说明Python同Java及C++的不同之处【题目描述】以软科中国最好大学排名为分析对象,基于requests库和bs4库编写爬虫程序,对2015年至2019年间的中国大学排名数据进行爬取:
(1)按照排名先后顺序输出不同年份的前10位大学信息,并要求对输出结果的排版进行优化;
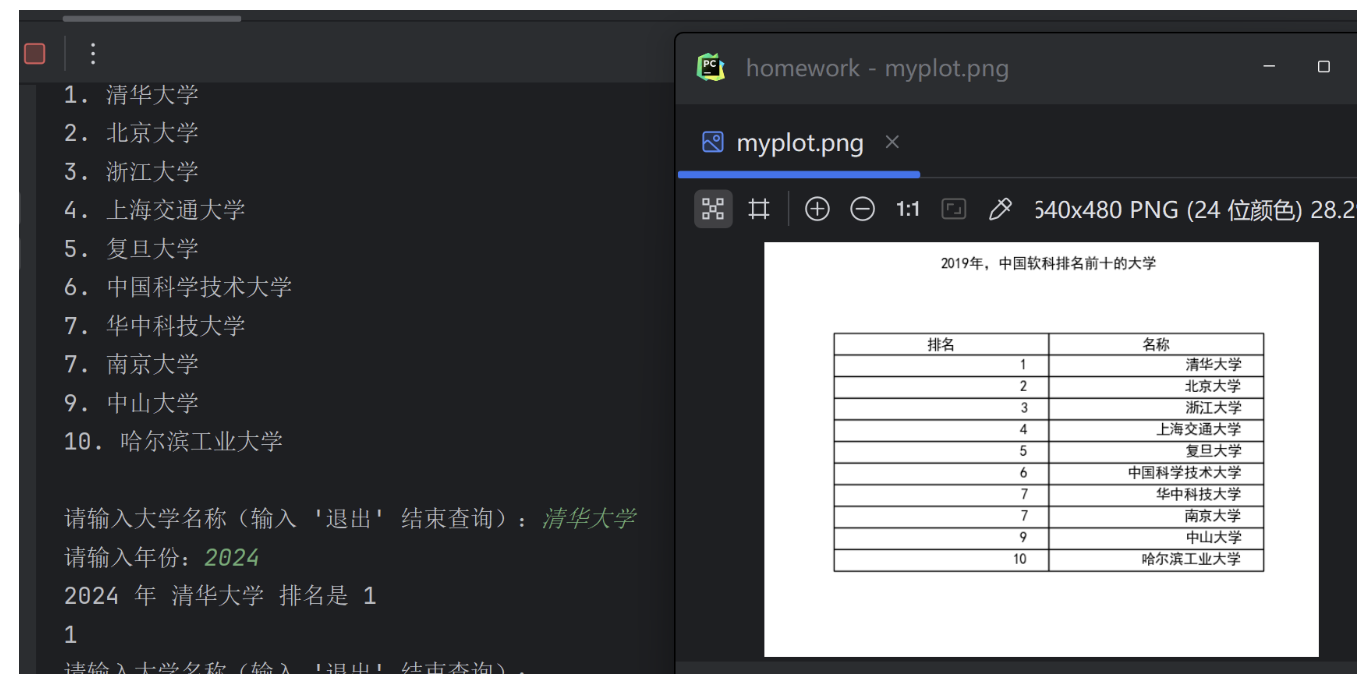
(2)结合matplotlib库,对2015-2019年间前10位大学的排名信息进行可视化展示。
(3附加)编写一个查询程序,根据从键盘输入的大学名称和年份,输出该大学相应的排名信息。如果所爬取的数据中不包含该大学或该年份信息,则输出相应的提示信息,并让用户选择重新输入还是结束查询;
【练习要求】请给出源代码程序和运行测试结果,源代码程序要求添加必要的注释。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 | import requestsfrom bs4 import BeautifulSoupimport matplotlib.pyplot as pltfrom sympy.physics.control.control_plots import matplotlibplt.rcParams['font.sans-serif']=['SimHei'] # 用来设置字体样式以正常显示中文标签plt.rcParams['axes.unicode_minus']=False # 默认是使用Unicode负号,设置正常显示字符,如正常显示负号# 设置请求头部信息headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}def get_ranking(year): url = f'https://www.shanghairanking.cn/rankings/bcur/{year}.html' # 发送HTTP请求以获取网页内容 response = requests.get(url, headers=headers) # 检查请求是否成功 if response.status_code == 200: # 使用BeautifulSoup解析HTML内容 soup = BeautifulSoup(response.content, 'html.parser') # 找到包含大学信息的表格 table = soup.find('table', class_='rk-table') # 提取前10所大学的信息 universities = table.find_all('tr', {'data-v-90b0d2ac': True})[1:11] # 排除表头行 # 存储排名数据的列表 ranking_data = [] for university in universities: rank_element = university.find('td', {'data-v-90b0d2ac': True}) # 检查排名元素是否存在 if rank_element: rank = rank_element.text.strip() name = university.find('a').text.strip() # 将排名数据存储到列表中 ranking_data.append({"排名": rank, "名称": name}) return ranking_data else: print("请求失败。状态码:", response.status_code)def main(): # 1. 获取并输出前10位大学信息 for year in range(2015, 2020): ranking_data = get_ranking(year) if ranking_data: print(f"{year}年前10所大学:") for data in ranking_data: print(f"{data['排名']}. {data['名称']}") print() # 创建一个表格的figure fig, ax = plt.subplots() # 隐藏坐标轴 ax.axis('off') # 创建表格 table = ax.table(cellText=[list(data.values()) for data in ranking_data], colLabels=list(ranking_data[0].keys()), loc='center') # 调整表格字体大小 table.auto_set_font_size(False) table.set_fontsize(12) # 调整单元格高度 table.scale(1, 1.5) # 显示表格 plt.title(f"{year}年,中国软科排名前十的大学", pad=20) plt.show() else: print(f"未能获取{year}年的大学排名数据。")def get_specific_ranking(university, year): # Renamed the function # 构建URL url = f'https://www.shanghairanking.cn/rankings/bcur/{year}.html' # 发送HTTP请求 response = requests.get(url) # 检查响应状态码 if response.status_code == 200: # 使用BeautifulSoup解析HTML内容 soup = BeautifulSoup(response.content, 'html.parser') # 找到包含大学信息的表格 table = soup.find('table', class_='rk-table') # 提取前30所大学的信息 universities = table.find_all('tr', {'data-v-90b0d2ac': True})[1:31] # 排除表头行 # 存储排名数据的列表 ranking_data = [] for university_row in universities: name_element = university_row.find('a') # 检查大学名称元素是否存在 if name_element: name = name_element.text.strip() # 检查大学名称是否与输入的大学名称匹配 if name == university: rank_element = university_row.find('td', {'data-v-90b0d2ac': True}) if rank_element: rank = rank_element.text.strip() print(f"{year} 年 {university} 排名是 {rank}") return rank # 如果未找到匹配的大学名称,打印消息 print(f"找不到 {university} 在 {year} 年的排名信息。") else: print("请求失败。状态码:", response.status_code)if __name__ == "__main__": main() while True: university = input("请输入大学名称(输入 '退出' 结束查询):") if university.lower() == '退出': break year = input("请输入年份:") print(get_specific_ranking(university, year)) |
合集:
python


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix