
 关于科学计算的一些工具的介绍,和适合于科学计算语言的一些思考。
关于科学计算的一些工具的介绍,和适合于科学计算语言的一些思考。
特别说明:要在我的随笔后写评论的小伙伴们请注意了,我的博客开启了 MathJax 数学公式支持,MathJax 使用
$标记数学公式的开始和结束。如果某条评论中出现了两个$,MathJax 会将两个$之间的内容按照数学公式进行排版,从而导致评论区格式混乱。如果大家的评论中用到了$,但是又不是为了使用数学公式,就请使用\$转义一下,谢谢。
想从头阅读该系列吗?下面是传送门:
- Linux 桌面玩家指南:01. 玩转 Linux 系统的方法论
- Linux 桌面玩家指南:02. 以最简洁的方式打造实用的 Vim 环境
- Linux 桌面玩家指南:03. 针对 Gnome 3 的 Linux 桌面进行美化
- Linux 桌面玩家指南:04. Linux 桌面系统字体配置要略
- Linux 桌面玩家指南:05. 发博客必备的图片处理和视频录制神器
- Linux 桌面玩家指南:06. 优雅地使用命令行及 Bash 脚本编程语言中的美学与哲学
- Linux 桌面玩家指南:07. Linux 中的 Qemu、KVM、VirtualBox、Xen 虚拟机体验
- Linux 桌面玩家指南:08. 使用 GCC 和 GNU Binutils 编写能在 x86 实模式运行的 16 位代码
- Linux 桌面玩家指南:09. X Window 的奥秘
- Linux 桌面玩家指南:10. 没有 GUI 的时候应该怎么玩
- Linux 桌面玩家指南:11. 在同一个硬盘上安装多个 Linux 发行版以及为 Linux 安装 Nvidia 显卡驱动
- Linux 桌面玩家指南:12. 优秀的文本化编辑思想大碰撞(Markdown、LaTeX、MathJax)
- Linux 桌面玩家指南:13. 使用 Git 及其 和 Eclipse 的集成
前言
不知道经常需要做科学计算的朋友们有没有这样的好奇:在 Linux 系统下使用什么工具呢?说到科学计算,首先想到的肯定是 Matlab,如果再说到符号计算,那就非 Mathematica 不可了。可惜,以上两款软件都是商业软件。虽然破解版满天飞,但是这不符合开源世界的逻辑。在 Linux 系统下,也有非常不错的科学计算工具,包括符号计算的也有。下面我就来隆重向大家推荐几款。
Octave
这款软件是 GNU 出品,在 GNU 的在线文档网站上可以下载到它的完整的帮助文档,我喜欢 pdf 版,可以一口气从头读到尾,很舒服。从语法角度讲,Octave 和 matlib 完全兼容。下面是其运行效果图:

它也有 GUI 界面的包装,那就是 QtOctave,如下图:
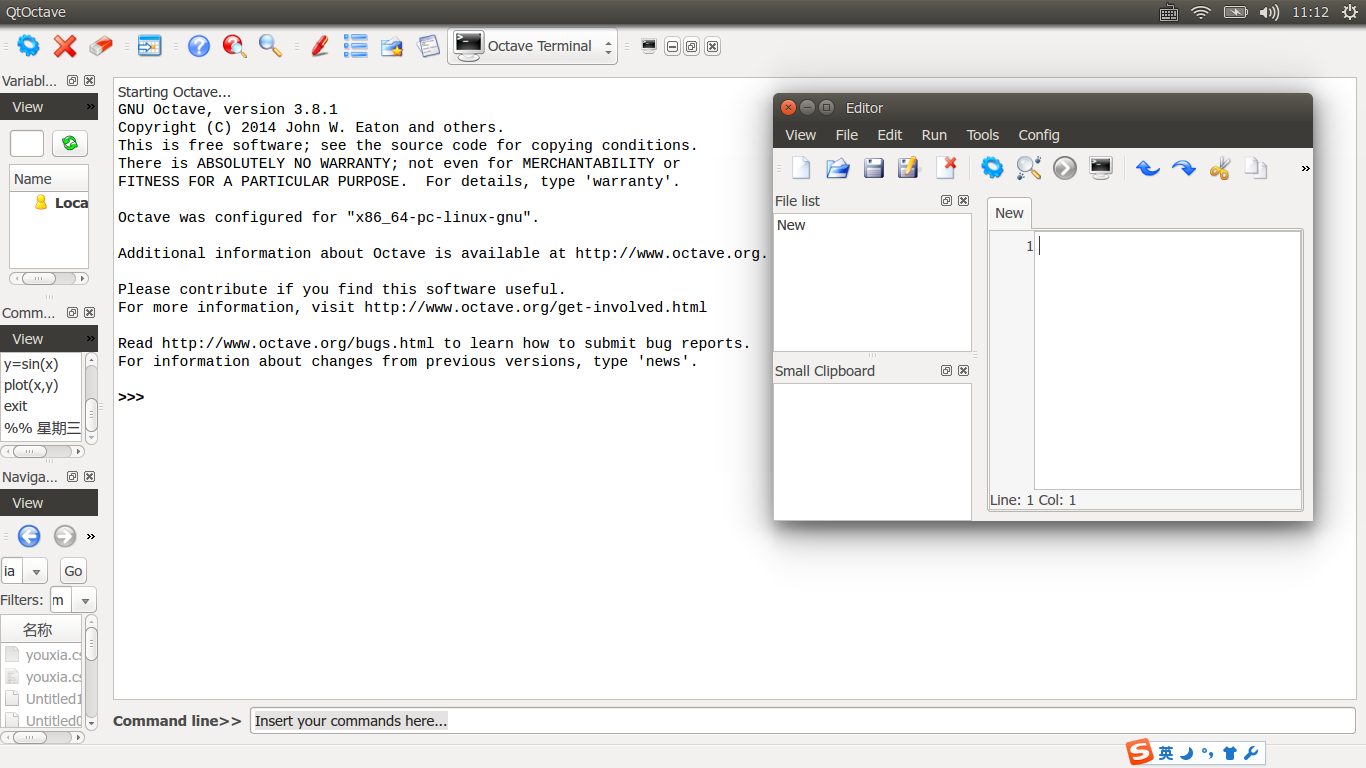
在 Ubuntu 下该软件的安装非常简单,使用如下命令即可:
sudo apt-get install octave
sudo apt-get install qtoctave
Maxima
数值计算使用 Octave,那么符号计算就少不了 Maxima 了。由于符号计算中,数学公式的显示也是非常重要的一环,所以我喜欢用它的 GUI 封装 wxMaxima,该软件使用如下命令安装:
sudo apt-get install wxmaxima
下面是它的运行效果图:

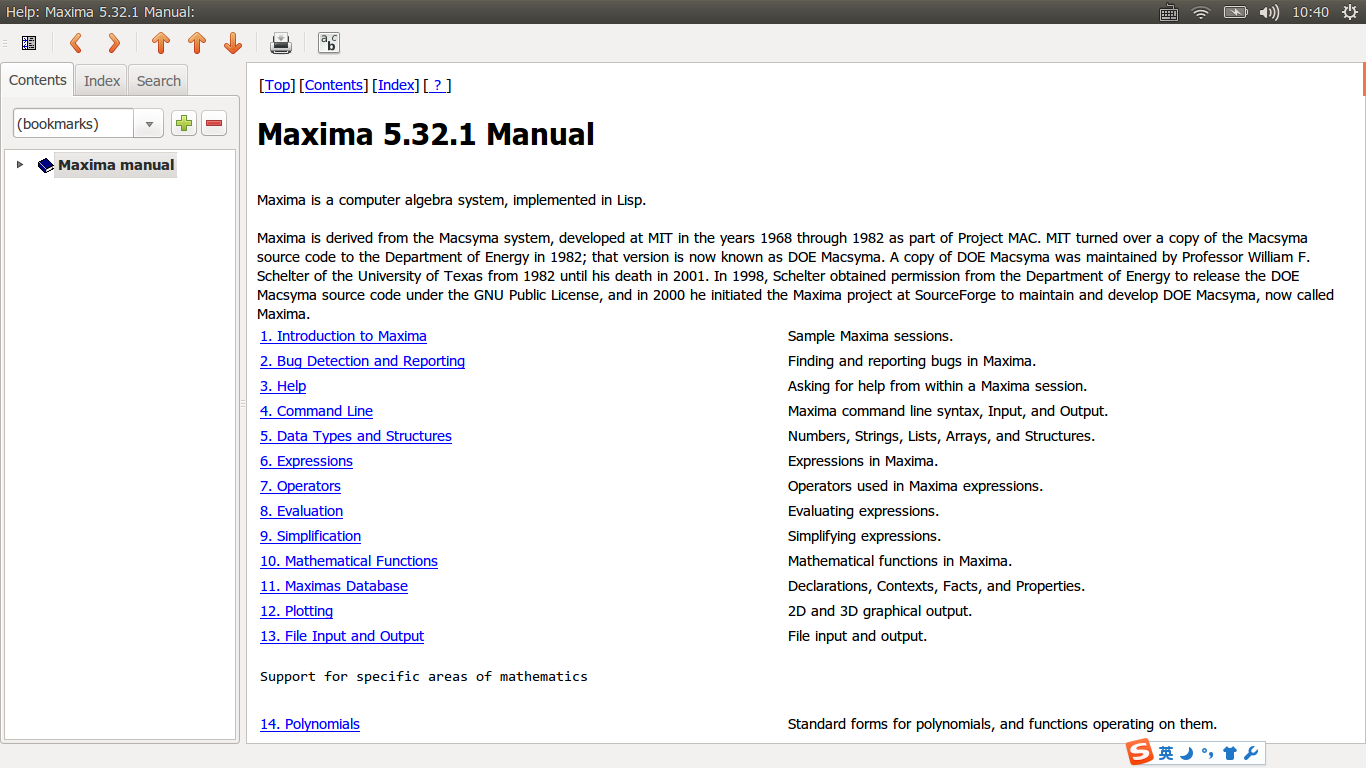
有了 GUI 的封装,我们的学习曲线都要简单很多,因为它的功能都在它的菜单栏中体现出来了。Maxima 也自带完善的文档,如下图:
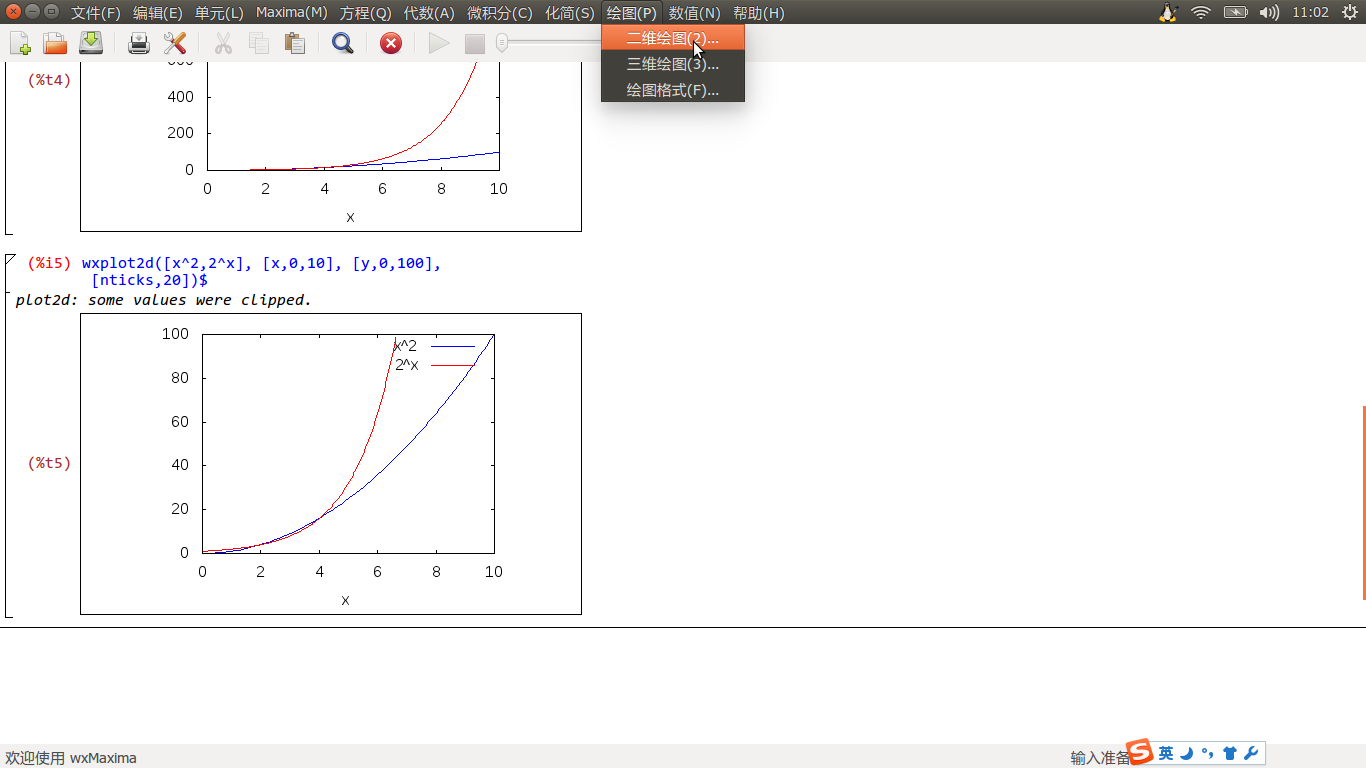
符号运算不仅能对各种数学公式进行运行、变形、化简,也可以直接对函数作图,如下图:
但是以上介绍的都不是重点。下面的工具才是我这篇随笔的重量级嘉宾。它就是:
Python 和 Jupyter notebook
使用 python 进行科学计算最近几年很火,主要得益于 python 语言和 Numpy、SciPy、pandas、matplotlib、SymPy 等库。另外一个大杀器就是 Jupyter notebook,它就是以前的 IPython notebook,现在的版本又进步了,改名叫 Jupyter notebook,可以通过 pip 进行安装。Jupyter notebook 可以说是提供了在数学方面读写算加画图一条龙的服务了。
另外,写 Python 最好的工具当然是 PyCharm 啦。如果只是做科学计算,使用 Community 版本就足够了,我并不建议大家用破解版。最后,虽然在 Ubuntu 中可以使用 apt-get 安装 Numpy、SciPy、pandas、matplotlib、SymPy 等库,但是我觉得污染全局的 Python 环境不好,所以我首先考虑使用虚拟环境,然后在虚拟环境中使用 pip 安装这些库到局部环境中。在 PyCharm 中创建项目的时候,就可以选择使用虚拟环境,我就选择 Python 自带的 venv 就好了,如下图:

直接打开 PyCharm 中的 Terminal,就可以进入这个项目的虚拟环境,在这个 Terminal 中运行的命令,默认就在这个项目的虚拟环境中执行。我们可以在这个 Terminal 中运行pip install命令安装所有需要的库。在 PyCharm 中使用pip install命令时,有一个令人头痛的问题,那就是从国外的源下载的速度太慢,我们可以替换成国内的源。我太懒,都是使用临时替换,只需要添加-i 源地址参数就可以了。例如,要安装 numpy,并且选择从阿里云下载,就使用pip install numpy -i https://mirrors.aliyun.com/pypi/simple/命令。如下图:

常用的国内源有:
- 清华:https://pypi.tuna.tsinghua.edu.cn/simple
- 阿里云:https://mirrors.aliyun.com/pypi/simple/
- 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
- 华中理工大学:http://pypi.hustunique.com/
- 山东理工大学:http://pypi.sdutlinux.org/
- 豆瓣:http://pypi.douban.com/simple/
新版 Ubuntu 要求使用 https 源,要注意。
使用pip install jupyter就可以安装 Jupyter notebook 了,如下图:

安装完之后,连 PyCharm 中的 Python 控制台的提示符都变了,从>>>变成了In[1]:。如下图:

然后运行jupyter notebook命令,就可以启动 Jupyter notebook 了。不错,这是一个 B/S 应用,我们启动它时会在我们的机器上建立一个简单的服务器,然后自动打开一个浏览器访问这个服务器,远程访问也行。下面是运行效果:

Jupyter notebook 中的内容是由一个一个的输入区域组成的,称为 Cell。每一个 Cell 除了可以输入代码,还可以输入 Markdown,如上图中所示。按 Shift+Enter 即可结束该区域的输入,并执行和显示效果。如果以后要重新编辑里面的内容,双击该区域即可。Markdown 区域也是支持 MathJax 的哦。上面的输入执行后,效果如下图:

下面看看使用 NumPy 来进行数值计算和绘图的效果:

在这里,使用了 Jupyter notebook 的魔术命令%matplotlib inline将绘图结果直接显示到页面中。Jupyter notebook 还有好多魔术命令可用,比如,我们可以使用%timeit测试某段代码的性能。
使用 pandas 进行数据分析并绘图的效果:

最后,看看使用 SymPy 进行符号计算的效果:

从上图可以看到,SymPy 的 latex 函数可以把输出的数学公式转换成 LaTeX 代码,不过该代码有点问题,它里面每个反斜杠都变成了双反斜杠。将该 LaTeX 代码复制、修改后,输入 Markdown 区域就可以看到完美的数学公式了。如下图:

我们在 Jupyter notebook 中建立的笔记是可以保存的,而且保存的是纯文本的 JSON 格式,扩展名是.ipynb,所以可以非常方便地把它放到 GitHub 进行分享。从 Jupyter notebook 的帮助菜单可以很方便地导航到 NumPy、SciPy、matplotlib、pandas、SymPy 的帮助文档。在 matplotlib 的官网中,还专门有一个 gallary 页面,里面有各种图表的缩略图和代码,对我们的学习真的是很有帮助哦。
最后,PyCharm 也支持我们创建 Jupyter notebook 文件,PyCharm 可以自己启动一个 Jupyter notebook 服务器,也可以连接到一个现有的 Jupyter notebook 服务器。其实从理论上讲,这没什么难的,浏览器能做到的事,PyCharm 肯定也可以做到,只是在 PyCharm 中内嵌一个浏览器内核的事而已。但是,目前我不太建议在 PyCharm 中使用 Jupyter notebook,因为它的黑色主题看起来还是不太舒服,而且对 Markdown 的支持不好。如下图:

适合数值计算的语言需要具备什么样的特色
前面搞了不少工具论,下面再来讨论一下编程语言。这段时间,我继续徜徉在数值计算的世界。为了广泛学习数值计算方面的知识,我抽空看了 Python 科学计算和数值分析方面的书,也仔细研读了 Octave 的用户手册,甚至连古老的 Fortran、新兴的 R 语言我都去逐一了解。对于数值计算的库,我了解了一下 Boost 的 uBLAS,以前也用过 OpenCV,当然,了解最多的还是 Python 中的 NumPy、SciPy 和 pandas。今天谈的内容是我对适合做数值计算的编程语言的一些看法,主要是一些思路方面的东西,不评论具体语言的优劣。另外,我是想到哪儿写到哪儿,如果有什么不对的地方欢迎大家指正。
一、元组和数组
如果数值计算仅仅只是两个标量之间的加减乘除,那就不需要我在这里浪费口舌了。向量啊、矩阵啊、多维数组啊什么,才是数值计算真正的主角。所以,适合做数值计算的编程语言必须有一个好的方式表示数组,特别是多维数组。哪种方式好呢?是这样:
int a[m][n][k];
还是这样:
int a[m,n,k];
看似没有什么差别,但是如果你想获取数组 a 的形状呢?比如这样:
? = a.shape();
或者再更进一步,想改变数组 a 的形状呢?比如这样:
a.reshape(?);
在上面的代码中,“?”究竟应该用什么代替呢?
如果让我给出答案,我会说:要用元组。很多编程语言中都有元组的概念,比如 Python。元组就是用逗号隔开的几个值,可以加圆括号,也可以不加。我觉得加上圆括号后可读性更好。比如 (a,b) 是元组,(3,4,5) 也是元组。如果写成 [3,4,5] 那就是数组了,在 Python 中,也称之为列表。不过 Python 的列表功能比数组要强大,因为数组只能保存同一种数据类型的值,而列表可以保存任何对象。数组一般情况下不能动态改变长度,而列表可以。Octave 语言中使用 cell array 这个术语来表示可以保存不同类型对象的容器。Octave 中的数组和矩阵是可以动态改变长度的。C 语言的数组没有动态改变长度这个功能,而如果使用 C++ 的话,则必须使用 vector<> 模板类。
我认为,一个好的编程语言必须要有“元组”这个一个概念,必须能够用好大括号、中括号和小括号。在有没有元组这个问题上,很多语言做得不好,C 语言没有,C++ 也没有,Java 没有,C# 这个有很多新功能的语言也没有,不要告诉我有 Tuple<> 模板类可以用,那个真的没有语言内置的元组功能好。在能不能用好大中小括号这个问题上,C 语言就做得不好。你看它不管是初始化数组,还是初始化 struct,都是用大括号。而 Python 和 JSON 就做得很好嘛,初始化数组用中括号,初始化对象或字典的时候采用大括号。如果加上小括号表示元组,那就齐活儿了。
数值计算可以针对标量、一维数组、二维数组以及n维数组进行。数组可以如下组织,如下图:

元组最大的用途就是可以用来表示数组的形状了。比如一维数组的形状为 (n,),请注意其中的逗号不能省略。二维数组的形状 (m,n),三维数组的形状 (m,n,k),依次类推。另外,元组可以用来对数组中的元素进行索引。比如:
a = [ [1,2,3,4], [5,6,7,8], [9,10,11,12], [13,14,15,16] ];
b = a[2,3,3];
元组还有一个很大的用途,那就是可以让一个函数返回多个值。C 语言在这个方面是做得比较丑陋的,如果一个函数要返回多个值,只能给这个函数传指针或者多重指针作为参数,C++ 可以传引用,C# 更加画蛇添足,专门有一个out关键字用来修饰函数的参数。微软你真是的,你既然能想到out,你就不能想到元组吗?常见的例子,比如meshgrid()函数可以同时初始化两个数组,peak()函数可以同时初始化三个数组。你看它们用元组多方便:
(xx, yy) = meshgrid(x, y);
(xx, yy, zz) = peak();
另外,元组还可以这样用,比如交换两个变量的值:
(a,b) = (b,a);
二、数组初始化
在数值计算中,数组的初始化也是非常重要的一环。如果像 C 语言这样写:
int a[100] = {1, 2, 3, 4, ... , 100};
估计很多人是要骂娘的。这样写:
for(int i=0; i<100; i++){
a[i] = i+1;
}
也不优雅。我只是想初始化一个数组而已,怎么就非得要写一个循环呢?如果是二维数组呢,就得两层循环,三维数组就得三层。真的是太闹心了。
另外,如前所述,我也不喜欢在初始化数组的时候用大括号。我觉得中括号就是为数组而生。比如这样:
a = [1, 2, 3, 4];
这就是一个一维数组,但是如果这样写:
a = [ [1, 2, 3, 4] ];
就是一个行向量。如果写成这样:
a = [ [1], [2], [3], [4] ];
那么这就是一个列向量,如下图:

当然,上面的示例只有四个数字,这么写一写无可厚非。如果是很多数字呢?或者很多维的数组呢?这时就必须得用到很多初始化函数了,而且这些初始化函数最好能接受元组作为参数来决定数组的形状。比如这样:
a = xrange( 1, 60, (3,4,5) ); //用1到60的数字初始化一个3*4*5的数组
b = randn ( (3, 4, 5) ); //用随机数初始化一个3*4*5的数组
其它的初始化函数还有 linspace()、logspace()、ones()、zeros()、eyes() 等等。这些函数还可以配合 reshape()使用,比如这样:
c = linspace(0, 2*pi, 60).reshape(3, 4, 5);
在所有的这些初始化中,元组都是重要的组成部分。
三、range 和切片
其实,range 除了可以是一个函数,还可以更省点儿事,像这样写:
r = 0:10:2; //0,2,4,6,8,10
s = 11:0:-3; //11,8,5,2
在某些语言中,也把这个功能叫切片。其实就是:的灵活运用,有标点符号可以用当然不能浪费嘛。使用切片,只需要指定起始值、终止值和步长,就可以获得一个数字序列。
但是,:最大的用途并不是用来对数组进行初始化,而是对数组进行索引。比如,a 是一个三维数组,可以通过切片来获取其中的一部分数据。见下面的代码:
a = range(1, 60).reshape(3, 4, 5); // a是一个三维数组
b = a[1, 2:3, 1:4]; // b是一个二维数组,其值为[ [12, 13, 14, 15], [17, 18, 19, 20]]
切片除了可以指定起始值和终止值外,也可以指定步长。当然,也可以只用一个单独的:,代表取这一整个轴。关于轴的概念,可以看我前面的图片。见下面这样的代码:
a = range(1, 60).reshape(3, 4, 5); // a是一个三维数组
b = a[1, :, :]; // b的值为二维数组[[1,2,3,4,5], [6,7,8,9,10], [11,12, 13, 14, 15], [16,17, 18, 19, 20]]
四、不写循环
在对多维数组进行加减乘除的时候,如果使用传统的像 C 这样的语言,则避免不了要写循环。比如要计算两个多维数组的加法,不得不写这样的代码:
m = 10;
n = 20;
k = 30;
a = randn(m, n, k); //形状为(m, n, k)的三维数组,初始化为随机值
b = randn(m, n, k); //形状为(m, n, k)的三维数组,初始化为随机值
for(int i=0; i<m; i++){
for(int j=0; j<n; j++){
for(int p=0; p<k; p++){
c[i, j, p] = a[i, j, p] + b[i, j, p];
}
}
}
上面的代码当然远不如下面这样的代码简洁:
C = A + B;
所以不写循环基本上就成了所有数值计算语言的标准配置。Matlab 和 Octave 是这样,NumPy 是这样,R 语言也是这样。C++ 也在追求这样,因为 C++ 中有运算符重载的功能,所以可以对矩阵类重载加减乘除运算符。但是 C++ 中运算符的基础设施有缺陷,比如它没有乘方运算符(幂运算符),在 Octave 和 NumPy 中,都可以这样计算 $ x^y $:x**y。但是在 C++ 中,只有使用函数 power(x, y)。不要想 ^ 运算符,它是一个位运算符,所以取幂只有使用 ** 了。另外,多维数组运算还有特例,比如二维数组之间加减乘除,既可以是逐元素的加减乘除,也可以是矩阵的加减乘除。向量计算也有特例,既可以是逐元素加减乘除,也可能是向量内积(点乘)。如果正好是长度为 3 的向量,还可以计算叉乘。这些运算符都需要重新定义,所以虽然 C++ 有重载运算符的机制,但是因为这些运算符完全超越了 C++ 的基础设施,所以 C++ 也没有办法写得很优雅。
不写循环还有一个优点,那就是可以对运算速度进行优化。优化是编译器或解释器的责任,写数值计算程序的人可以完全不用费心。编译器或解释器可采取的优化方式有可能是利用 SSE 等多媒体指令集,也可能是发挥多核 CPU 的多线程优势,甚至是使用 GPGPU 计算都有可能。如果用户非要写成 C 语言那样的循环,而他又不会内联汇编或 OpenMP 的话,那么就谈不上什么运算速度的优化了。
五、广播
不写循环,直接把两个多维数组进行加减乘除当然省事。但是如果两个数组的形状不一样呢?比如一个二维数组加一个行向量,或一个二维数组加一个列向量,甚至是数组加减乘除一个标量,会出现什么情况呢?
不用担心,在面向数值计算的语言中,一般都有“广播”这样一个特性。当两个数组的形状不一样时,形状比较小的那个往往可以在长度为 1 的维度上进行广播。如下图:

六、奇异索引
Fancy indexing,有的书上翻译成花式索引,但我认为叫奇异索引比较好。它就是指一个低维的数组,可以使用高维的数组进行索引,最后得到的结果是一个高维的数组。如果索引中含有切片,可能会得到一个更高维度的数组作为结果。
这个概念理解起来比较难。特别是再配合切片使用,更加增加其复杂性。所谓一图胜千言,先看普通索引的情况:

前面提到,对多维数组进行索引的时候需要用到元组,元组的长度等同于数组的维数。对于普通索引而言,元组的各个部分要么是整数,要么是切片。而对于奇异索引而言,索引元组的各个组成部分都可能是多维数组或者切片。如果是多维数组,则最后得到的数组的形状和索引数组的形状相同,如果配合切片,则可能得到更高维的数组。如下图:

七、函数调用
编程语言发展这么多年,一直在进化,也一直在相互靠拢。对于一个编程语言来说,是应该面向过程还是面向对象?是静态类型还是动态类型?这些都是值得思考的地方。但是在函数调用方面,有一些思想倒是可以学习。
在 C 语言这样比较古老的语言中,对于函数的参数来说,只有位置参数一种。也就是说,像一个函数传递参数的时候,只能正确的参数放到正确的位置,而且参数的个数必须和函数定义的相同。这是最原始的函数调用思想。
紧接着,在某些编程语言如 Java、C# 中,有了可选参数这个概念。但是可选参数要放到参数列表的最后面,而且必须提供默认值。当调用函数时如果指定了这个参数,则使用调用时指定的值,否则使用默认值。
但是我觉得适合数值计算的语言必须还得更进一步,提供关键字参数的功能。什么是关键字参数呢?比如对数据进行绘图的时候,需要指定线型、标签、标题等各种属性,可以这样调用函数:
plot(x, y, marker="*", color="r", linestyle="-", title="...", legend="...", xlabel="...", ylabel="...");
每一个参数调用的时候都可以指定它的名字,这样我们就不用去死记各个参数的位置,是不是很方便呢?
八、生态环境
对于一门编程语言而言,生态坏境很重要。在数值计算领域更是如此。因为很多数值计算的库都是专业的人士写给专业人士看的,比如物理专业的写物理领域的算法,气象专业的写气象专业的算法,所以不大可能有一个全面的官方的,像 C 或 C++ 这样一个由 ANSI 定义的库。
广泛接受开源社区的贡献是一个比较好的办法。Perl 是这样,Python 也是这样,新兴的 R 语言也是这样。Perl 有 CPAN,Python 有 PyPI,R 语言也有 CRAN。至于 Matlab,那更是有各种各样的工具包。
OK,就写这么多吧,还有其它的一些什么特色,我想到后再随时更新此文。
另外,本文中所有的图片都是在 Ubuntu 中使用 Inkscape 矢量图软件绘制而成。
版权申明
该随笔由京山游侠在2018年11月16日发布于博客园,引用请注明出处,转载或出版请联系博主。QQ邮箱:1841079@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号