【论文笔记】CBIR的最近发展 - Recent developments of content-based image retrieval
Abstract
随着互联网技术的发展和数字设备的普及,基于内容的图像检索(Content-Based Image Retrieval, CBIR) 迅速的发展、应用,涉及计算机视觉和人工智能的各个领域。目前,可以有效且高效地从具有输入图像的大规模数据库中检索相关图像
本文对 2009-2019 年间 CBIR 的 理论和算法 的 发展和应用进行了综述
- 从图像表示和数据库搜索的角度对这些技术的发展进行了回顾
- 进一步总结了基于内容的图像检索在时尚图像检索、人物识别、电子商务产品检索、遥感图像检索、商标图像检索等领域的实际应用
- 针对大数据的挑战和深度学习技术的应用,讨论了基于内容的图像检索的未来研究方向
1-Introduction
CBIR 是什么 & 应用
基于内容的图像检索 (Content-Based Image Retrieval, CBIR) 技术可以根据我们感兴趣的对象或内容的输入图像从数据库中检索相关图像
应用举例
- 人脸检索可以帮助警察和其他安全人员更快地抓获嫌疑人
- 在网上购物中,商品图像检索可以帮助顾客找到他们喜欢的商品
- 从地图上检索可以帮助我们更准确地定位,减少迷路的可能性
- 衣物检索可以帮助消费者购买他们想要的衣服
- 医学图像检索可以帮助医生更有效地进行医疗诊断等
CBIR 的两大部分
- 用于图像索引的图像表示
- 我们希望特征向量或图像表示能具有鉴别性以帮助区分图像。更重要的是,我们希望它们对某些转换是不变的
- 用于数据库搜索的相似性度量
- 基于图像表示,两幅图像之间的相似性度量应反映语义上的相关性
这两个用以连接的 components 对检索性能至关重要,现有的 CBIR 算法可以根据它们对这两个 components 的贡献进行分类
事实上,从大规模数据库中获取准确的检索图像仍然是具有挑战性的。最大的挑战是图像的高级含义与其低级视觉特征之间的语义鸿沟
为了缩小这一语义鸿沟,学术界和产业界都做出了广泛的努力——因此 CBIR 在最近几年取得了长足的进步
例如,谷歌和百度都是流行的搜索引擎,可以通过任何图像搜索相关图像。阿里巴巴、亚马逊和 eBay 等一些电子商务网站也有类似的商品搜索功能。像 Pinterest 这样的社交平台也有类似的内容推荐功能。
过去的综述不足 & 本文的贡献
过去已经有一些文章,但存在不足:
- 它们不包括 2017 年至 2019 年的最新研究,在此期间经历了大数据的挑战和深度学习技术的应用,有很多新算法值得总结
- 他们只关注技术发展,没有对实际应用进行深入总结
在本次调查中,我们关注 2009 年至 2019 年 CBIR 的技术发展和实际应用。本文的主要贡献在于三个方面:
- 首次从图像表示和数据库检索的角度对 2009-2019 年间的技术发展进行了回顾和分类
- 进一步总结了 2009-2019 年 CBIR 在时尚图像检索、人物识别、电子商务产品检索、遥感图像检索、商标图像检索等领域的实际应用
- 针对大数据的挑战和深度学习技术的应用,分析和讨论了基于内容的图像检索的未来研究方向
结论没有新东西,也就是上面这些
本文结构
- 第二节介绍了基于内容的信息检索的一般流程
- 第三节和第四节分别回顾了近年来 CBIR 在图像表示和数据库搜索方面的发展
- 第五节进一步总结了基于内容的图像检索的实际应用
- 第六节概述了基于内容的图像检索的未来发展方向
- 第七节对基于内容的图像检索进行了简要的总结
2-General flowchart overview
介绍了基于内容的信息检索的一般流程
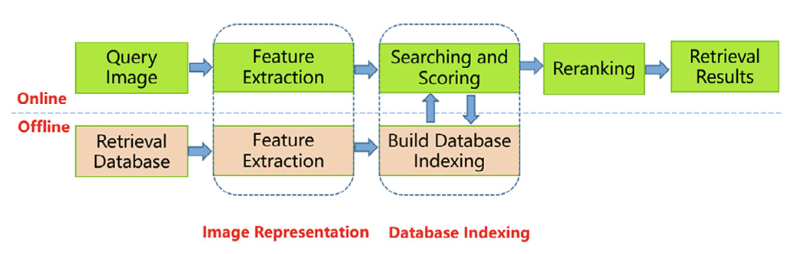
首先介绍了基于内容的图像检索系统的总体框架,如图 1 所示
- 在离线子系统中,每幅图像都以其提取的特征向量作为检索数据库中的索引进行编码
- 在线子系统中,输入查询图像后:
- 以与检索数据集中的图像相同的方式提取其特征向量
- 使用该特征向量对数据库中所有可能的图像进行相似度评分
- 那些得分高于预定义阈值的图像将被选中,通过增强 visual context in contrast to the original query 来进一步细化
- 最后,按照重排分数的降序将这些图像视为检索系统的概率排序结果或输出
- 在该框架中,基于特征的图像表示是数据集索引的基础,并借助于一定的相似性度量。从技术的角度来看,CBIR 系统是基于图像表示和数据库搜索的。因此,我们分别从图像表示和数据库搜索两个方面对基于内容的图像检索研究进行综述
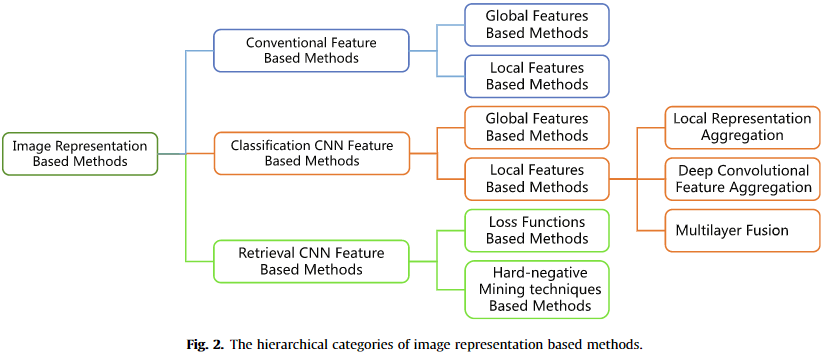
3-Image representation
回顾了近年来 CBIR 在图像表示和方面的发展
对于 CBIR,关键的一步是图像表示,即:从给定的图像中提取关键特征,然后将其转换为 fixed-size 的向量 (所谓的特征向量)
一般来说,提取的特征可以分为三大类:
- 常规特征 conventional features
- 分类 CNN 特征 classification CNN features
- 检索 CNN 特征 retrieval CNN features
3-1-Conventional feature based methods
指没有通过任何 CNN 方法提取的特征,主要存在于早期 CBIR 系统,但近年来也在某些方面取得了显著的发展
这些特征是 heuristically designed 启发式设计的(没法在数学上严格证明的,但是用起来又有效的),可以进一步分为全局特征和局部特征
全局特征
- 全局特征通常分别从图像的颜色、形状、纹理和结构中提取,然后转化为整体表征。当然,这些多类型的全局特征可以进一步组合在一起进行图像检索
- Li 等人 实际上开发了一种两阶段生成 generative/判别 discriminative 学习算法,将颜色、纹理和结构特征结合在一起进行图像检索。具体地说,生成阶段将图像的各种描述的长度归一化,而判别阶段识别哪些图像包含目标对象。事实上,该算法可以组合任意数量的不同特征类型,而不需要任何建模假设
- Berman - 组合特征,灵活的图像数据库系统,其中栅格距离度量和组合操作也可以组合任意一组多种类型的特征
- Zhao - 将稀疏表示法(SR)应用于图像检索;研究了前向和后向稀疏表示的差异和互补性,然后构建了一种新的半监督学习模型——合作稀疏表示法,结合二者、提高了图像标注性能
虽然这些方法表达紧凑,适合于大规模图像数据库中的重复检测,但当目标图像包含一些背景杂波时,它们可能不能很好地工作
局部特征
特征提取
SIFT 最为著名(at 高级变换),近年来许多局部特征提取方法都是 SIFT 的拓展,主要包括 interest point detection 和 local region description 两个步骤
- Zhou 等 - 开发了 binary signature of the SIFT descriptor,其中两个 median thresholds 由 original descriptor 本身确定
- 并利用该二进制 SIFT 建立了一种新的 CBIR 索引方案 BSIFT
- 还将边缘加入到特征描述符中,建立了 Edge-SIFT
除了像 SIFT 这样的图像关键点的特征提取方法,一些局部特征方法提取密集网格 dense grids 上的特征——可能在多个尺度上独立于图像内容。
事实上,近年来已经开发了各种本地描述符。由于这些方法都有不同的优点,因此很难为检索任务选择最好的方法。然而,Madeo 等人[20]从速度、紧凑度、区分度三个方面对几种典型的局部描述符进行了对比分析
向量表示
当样本图像随着数据集中某类局部特征的大量集合而发生巨大变化时,通常需要将这些局部特征聚合为具有固定长度的向量表示,以便通过查询与所有数据库图像的相似性比较,以进行后续的数据库搜索
这些聚集方案中的大多数需要对这些局部特征进行聚类分析,以获得所获得的聚类的中心的码本 obtain a codebook of the centers of the obtained clusters,根据该码本,原始特征向量可以以不同的方式聚合
传统方法后续略了
3-2-Classification CNN feature based methods
基于 CNN 特征的分类方法:找到特征,比较特征
同样,CNN 方法也可以分为两类:全局特征和局部特征
提取自 CC 的 deep fully connected layers 的特征本质上是 deep global features, 描述了图像的全局语义信息
有一些基于深度全局特征的方法
- Bakenko 等人 - 采用全连接层的 activation,其中 CNN 在与测试集相关的数据集上进行微调,作为 global descriptors,然后进行降维 dimensionality reduction
- 然而,制作标记训练数据的成本很高,所以一些作品使用的是现成的网络,只在 ImageNet 上预先训练过
- 结果表明,使用第 7 个全连接层(fc7)特征可以比使用第 8 个全连接层(fc8)特征具有更好的检索效果——这是因为较高层的特征旨在对预训练数据集执行分类任务,而较低层的特征对其他数据集具有更好的泛化能力
- 这些方法可以产生紧凑的嵌入特征,以便在过滤步骤中快速计算相似度,但可能缺乏对图像细节的描述——这对于图像检索而言意义不大。因此,关注 CNN 局部特征的作品越来越多
According to the features in image representation extraction process, 基于局部 CNN 特征的方法可以进一步分为三类:
- 局部表示聚合 (local representation aggregation)
- 深度卷积特征聚合 (deep convolutional feature aggregation)
- 多层融合 (multi-layer fusion)
通常,这些方法使用现成的仅在 ImageNet 上预训练的网络作为特征提取器
局部表示聚合
他们首先尝试从输入图像中提取一系列局部区域,然后将这些局部区域输入到网络中,生成相应的局部图像表示。这些部分图像表示又通过特定的聚合方法又聚合成一个紧凑的图像表示。根据提取局部区域的不同,我们进一步将这类方法分为三大类:
- 基于滑动窗口的局部区域提取 local area extraction based on the sliding window
- 通常使用一系列不同的滑动窗口在输入图像上滑动以创建局部区域
- Razavie 等人[31]使用 4 种不同大小的滑动窗口和 FC7 特征作为图像的部分表示
- Gong et al.[32]提出了多尺度无序池(MOP)算法来嵌入和汇集不同尺度层次的 CNN 全连通激活图像块,然后使用 VLAD 对这些局部图像表示进行聚合
- 有关区域检测 region of interest detection
- 第二类方法实现了一些特定的检测算法来提取输入图像中的感兴趣区域
- 例如,补丁-卷积核网络(Patch-CKN)[33]利用海森仿射检测器来提取输入图像中的感兴趣区域
- Mopuri 等人[34]利用训练有素的探测器进行强健的地标定位,以产生更高效的区域搜索系统
- 基于区域提议的局部区域提取 local area extraction based on region proposal
- 基于区域建议,利用一些特别的无监督候选区域生成算法来获取可能包含目标的局部候选区域
- Mopuri 等人[35]使用选择性搜索提取 2000 个局部区域并将这些区域馈送到网络,生成 fc7 特征并作 max-pooling 来计算图像级表示
- 互补 CNN 和 SIFT(Complementary CNN and SIFT, CCS)[36]使用 Edgebox 从每张图像中提取 100 个局部区域,并将这些区域提供给网络,然后使用 VLAD 来聚合这些 CNN 特征。
上述方法都需要多个前馈网络,因此其效率成为瓶颈
深度卷积特征聚合
看 这一篇的 introduction 部分 ,从全连接层特征转向深度卷积层的特征;例子可看这篇
深度卷积特征可以被视为对输入图像局部区域的描述。这些方法只需向网络馈送一次,即可生成深卷积特征,并将其聚合得到最终的图像表示,计算效率较高
这些方法的关键问题是如何聚合深度卷积特征。通过考虑聚合中是否存在权重机制,我们可以将这些方法分为直接聚合和加权聚合
直接聚合方法使用特定的聚合方法来聚合深卷积特征,以获得最终的图像表示。聚合方法可以使用 BOW、VLAD、FV、max-pooling 和 sum-pooling 等经典方法。
- 区域卷积最大激活(Regional Maximum Activation of Convolutions, R-MAC)[37]通过在卷积特征映射中最大限度地汇集局部区域来均匀采样和聚集,以考虑区域信息
- Sum-Pooled Convolutional (SPoC) [38] 表明,当最终图像表示被 白化 whiten 时,sumpooling 方法优于最大池化方法
- 当使用带有白化的鲁棒视觉描述符 (RVD-W) 方法 [29] 来聚合 CNN 特征时,检索性能得到进一步提高。
- 伊森等人 [39] 利用多尺度网格与 CNN 特征相结合,通过扩散实现查询扩展
加权聚合方法采用直接聚合的策略对深度卷积特征进行编码,根据每个位置特征的重要性对深度卷积特征进行加权
- 选择性卷积描述符聚合 (SCDA) [40] 提出了一种无监督方法,用于在去除噪声背景的同时定位代表性对象,从而改进细粒度图像检索性能
- Kalantidis 等人[41]提出了在 CNN 特征聚合中引入交叉维加权对 Spoc 进行扩展的 Crow 算法
- 希门尼斯等人[42]使用类激活映射(CAMS)来计算卷积特征映射的语义感知空间权重
- 通过基于部分的加权聚集(PWA)[43]发现,深度卷积特征的不同通道对应于目标不同部分的响应
- 一些检索方法[44,45]采用了注意机制。深度局部特征(DELF)[44]采用了一种基于学习的注意力网络,并使用该注意力网络对特征地图上的所有点进行密集加权。Kim 等人[45]提出了一种简单而有效的区域注意力网络,该网络考虑了全局背景,对区域的注意力得分进行了加权
最后,我们考虑多层融合。深层的 CNN 特征是有层次性的,即随着 CNN 层级的深入,它们从 低层的视觉特征 转变为 高层的语义特征 。
深度卷积特征聚集方法旨在补充深度神经网络中不同层特征的信息,以综合不同层特征的不变性和区分能力
我们可以进一步将这些多层功能融合在一起。
- 多尺度区域卷积最大激活(MS-RMAC)[46]分别从 VGG-16 的 relu1-2 层、relu2-1 层、relu3-3 层、relu4-3 层和 relu5-3 层提取 R-MAC 特征[37],然后将得到的特征加权到最终的图像表示中
- Seddati 等人。[47]通过特征选择,将多尺度和两层特征提取机制结合起来,提出了一种改进的 RMAC 签名。基于区域熵的多层抽象池(REMAP)[48]从多个 CNN 层学习和聚集深层特征的层次结构,was trained in the way of end-to-end with a triplet loss.
3-3-Retrieval CNN feature based methods
基于 CNN 特征的检索方法(端到端):直接判断源与目标的“差距”?
虽然这么多研究关注从“分类任务预先训练的深层网络中提取特征(然后检索),但后来研究表明深层网络可以直接针对端到端的实例检索任务进行训练
在 deep matric learning 中有一些有效的损失函数,如对比损失、三重损失、三重中心损失、四重损失、提升结构损失、N 对损失、二项偏差损失、直方图损失、角度损失、基于距离加权差值的损失和层次三重损失 (contrastive loss, triplet loss, triplet-center loss, quadruplet loss, lifted structure loss, N-pairs loss, binomial deviance loss, histogram loss, angular loss, distance weighted margin-based loss, and hierarchical triplet loss)
它们的共同原则是对一小部分图像进行 subsample,验证它们是否 locally(局部地?)符合 ranking 目标,如果不符合,则执行一次小的模型更新,并重复这些步骤,直到收敛
基于 CNN 特征的检索方法采用了上述损失函数
- 拉德诺维奇等人[56]使用对比损失来学习图像表征
- Gordo 等人[49]引入了三元组损失
- 同样,N 对损失[57]、三对中心损失[58]和四对损失[59]都有效地提高了提取精度
- Kim 等人。[54]提出了一种新的三元组损失,它允许将标签空间中的距离比保留在学习的度量空间中(?
- 最近,he 等人[60]引入了平均精度(AP)损失,并演示了其在 patch verification, patch retrieval and image matching 方面的出色结果
- 受此启发,Revaud 等人[53]通过利用列表损失公式的最新进展,直接优化了全局平均平均精度(Mean Average Precision, MAP)。与现有的损失相比,它可以在 每次迭代中同时考虑数千幅图像 ,并在许多标准检索基准上建立了新的最先进的图像表示。
在深度度量学习中,hard-negative mining techniques 可以显著提高学习嵌入空间的质量。事实上,CBIR 在这方面已经做了很多工作。
- The lifted structured loss [51]通过在自身内部结合 hard-negative mining 功能,每次都在一个小批量中考虑所有正负对(?
- Kim 等人[54]设计了一种适用于连续标签的 metric learning 的三元组挖掘策略
- 通常,基于 CNN 特征的检索方法可以采用半硬挖掘、智能挖掘、距离加权抽样等硬否定挖掘技术。特别的,Wang 等人[55]建立了 General Pair Weighting(GPW)框架,通过梯度分析将深度度量学习中的抽样问题转化为统一的配对加权问题,为理解最近的 pair based loss 函数提供了有力的工具
4-Database search
通过有效的图像表示或特征向量,我们可以进一步建立 CBIR 系统的数据库索引方法,并通过相似性度量对图像索引进行搜索。我们将这整个过程称为数据库搜索
由于检索时间是影响 CBIR 系统性能的关键,因此数据库搜索非常重要,尤其是在大型图像数据库中。事实上,一种高效的数据库搜索方法可以显着加快检索过程并大大减少内存使用
高维特征向量的数据库搜索方法通常分为两种:特征直接数据库搜索和特征利用数据库搜索。然而在实际应用中,数据库搜索方法往往将这两种数据库搜索方法结合起来进行性能优化。为清楚起见,数据库搜索方法的分层类别如图 3 所示。
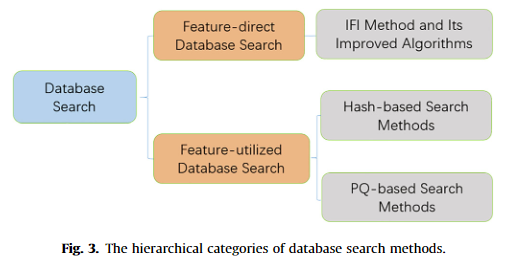
4-1-Feature-direct database search
直接使用特征的数据库搜索方法利用每幅图像的特征向量作为数据库搜索的索引,即特征向量直接作为原始图像的索引
存在一些有效的 CBIR 特征直接数据库检索方法:
- 一些方法通过反向文件索引技术 inverted file index techniques 加快检索过程
- 另一些方法通过分层聚类或 K-Dimensional Tree (KD 树)缩小搜索路径。这类搜索最常用的方法是反向文件索引(IFI)[61]
受 information retrieval 领域的启发,IFI 存储 word IDs 到单词出现的 document IDs 的映射(还挺熟悉)
在 CBIR 系统中,IFI 是稀疏矩阵的简洁表示,其行和列分别表示图像和视觉词汇。因此,在查询阶段,包含与 查询图像相同视觉词的 数据库图像 通过欧几里得度量、余弦距离等相似度的计算,大大提高了时间效率。
IFI 是许多搜索系统的核心组件[62,63] ,因为它促进了更快和更可伸缩的查询。一些方法对原始 IFI 做了某些改进。
- 反向多索引(IMI)[64]利用产品量化的思想构建了一个多索引结构,以优化重排序搜索空间。传统 IFI 结构的索引是一维数据,而 IMI 结构的索引使用多维表。使用 IMI 进行检索时,返回的候选元素倒排列表更短,候选元素更接近查询词,查全率更高
- Zheng 等[65]使用多个逆文档频率(IDF)方法来适应多个特征之间的相关性,并将特征的相应二进制代码存储到倒排索引中,而 Liu 等[66]提出了原始 SIFT 特征空间和二进制 SIFT 空间的交叉索引
为了提高检索的准确率,一些方法在倒排表中嵌入语义信息。
- Karayev 等人[67]基于语义属性的 SIFT 特征 去除倒排表中不相关的图像,插入语义相关图像,极大地提高了索引特征的区分能力
- 张等人[68]提出了一种将语义属性(作为因素)共索引到 由局部特征生成的倒排索引中的方法,使索引能够传递更多的语义线索
也有一些改进的算法来加快检索速度
- 郑等人[69]提出了一种 Q index,该索引去除了查询图像中不重要的特征,根据预定义的特征得分只检索倒排表中较重要的特征
- 对于并行检索,Ji et al.[70]在多个服务器上建立分布式索引,并将索引分布问题定义为一个学习问题,以减少服务器之间的搜索延迟
为了提高召回率,通常对一幅图像使用多个量化器来获得多个索引[71,72]
- 夏等人[71]采用协同索引结构同时优化多个量化器。非正交倒排
- 多指标(NOIMI)是等人提出的[72]是一种适用于海量深度特征数据的快速索引方法。非 IMI 包括两个码表,S 和 T,每个码表包含 K 个码字。S 是通过对原始数据进行聚类而生成的一阶码表,而 T 是通过对原始数据和每个对应的一阶聚类(S 中的码字)的质心之间的残差数据进行聚类而生成的二阶码表,从而消除了正交子空间的任何分解。因此,NOIMI 为海量深度 CNN 特征数据的标引提供了更合理的索引单元,质心更准确地代表了实际数据的分布
4-2-Feature-utilized database search
利用特征的数据库搜索方法通过将高维浮点特征向量映射到低维向量或二值向量来降低距离的计算复杂度
一种广泛使用的特征利用的数据库搜索方法是基于 hashing 的索引,其将图像压缩成一系列 Hashing 码,使得搜索可以被转换为 Hashing 码之间的汉明距离的比较。因此,它可以同时降低计算复杂度和存储成本。
基于 Hashing 的方法可以分为数据无关方法[73]和数据依赖方法[74-77];依赖数据的方法可以进一步分为无监督 Hashing 方法[74,75]和有监督 Hashing 方法[76-78]。基于 Hashing 的方法的层次结构如图 4 所示
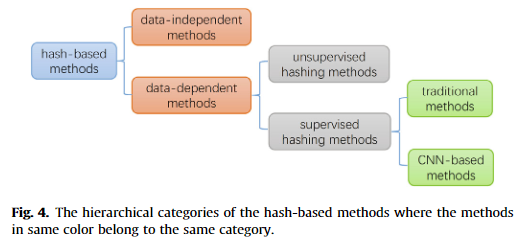
数据无关
与数据无关的方法是基于 哈希函数 的,该哈希函数是独立生成的,没有任何关于训练集的信息。
- 最具代表性的是 Locality-Sensitive Hashing (LSH)[73],它使用许多随机映射 Hashing 函数来划分特征空间。当两个特征向量相似时,它们具有更高的碰撞概率。在给定查询图像的情况下,可以根据哈希冲突过滤候选列表,然后通过精确的距离计算对候选列表进行重新排序。有许多这种方法的变体可以加快搜索过程[79]。然而,由于缺乏训练数据集的信息,它们的检索结果并不理想。
数据有关:无监督
无监督哈希方法只利用训练数据集的信息,不带标签信息来指导训练阶段。它们的代表包括各向同性 Hashing(IsoH)[74]、可伸缩图 Hashing(SGH)[80]、有序嵌入 Hashing(OEH)[75]等。然而,由于没有来自训练数据集的信息来指导训练过程,他们的结果具有一定的局限性。
数据有关:有监督
分为传统的有监督 Hashing 方法和基于 CNN 的有监督 Hashing 方法
传统方法
存在一些传统的监督 Hashing 方法,如快速监督 Hashing(FASSH)[81]、监督离散 Hashing(SDH)[82]、COlumn Sampling based DIscrete Supervised Hashing (COSDISH)[83]和非对称内积二进制编码(AIBC)[84]。与无监督 Hashing 相比,传统的有监督 Hashing 方法可以利用图像的标签来生成更高精度的 Hashing 码
然而,对于 streaming data,依赖于数据的方法中的 Hashing 模型应该被修改以适应新到来的数据的分布。随着来自互联网的数据的不断增长,对海量的社会数据进行在线哈希更新变得非常耗时
- 为了缓解这一问题,Ma 等人 [85] 提出了 Hamming Subspace Learning (HSL),通过选取具有代表性的 Hashing 函数,从高维 Hamming 空间生成低维 Hamming 子空间
HSL 在一定程度上提高了在线更新的速度和 Hashing 的性能。尽管如此,这些传统的有监督 Hashing 方法仍有两个明显的缺陷:
- 它们的特征提取不依赖于哈希函数的学习,因此设计的特征可能与 Hashing 过程不兼容;
- 它们使用的传统特征不能包含语义信息
CNN 方法
- 卷积神经网络哈希 (CNNH) [86] 将基于 CNN 的深度哈希算法推向了最前沿,它不是端到端的训练
- Network In Network Hashing (NINH) [87] 同时基于 CNN 的学习特征模块和哈希编码模块。它是端到端的,但特征学习的准确性还不够好
- 紧凑根双线性 CNN (The Compact Root Bilinear CNN, crb-cnn) [76] 使用integrated 网络模型来获得更好的语义特征
- Conjeti 等 [88] 和 Cheng 等 [78] 都提出了残余哈希架构 residual hash architecture,以降低计算机的存储容量,提高检索效率
- 深度语义排名散列 (Deep Semantic Ranking Hashing, DSRH) [89] 使用了类似于 DeepID2 的网络结构,直接让网络学习排名
- 同样,Shi 等人 [77] 提出了用于检索和分类任务的深度排名哈希
- 受深度监督哈希 (DSH) [90] 在线训练策略的启发,利用使用三元组标签的更丰富信息,Zhou 等人 [91] 利用三元组损失函数增强了学习紧凑二进制代码的 DSH 算法
- 此外,Li 等 [92] 提出了一种新颖的基于 CNN 的哈希码生成方法,即分段监督深度散列 (Piecewise Supervised Deep Hashing, PSDH) 方法,该方法直接 uses a latent layer 数据和分类网络的输出层结果,为每个输入图像生成一个两段哈希码。实际上,PSDH 在搜索具有相似特征的图片方面表现出色
这些方法大多数都是端到端训练,其特征提取依赖于哈希函数学习。它们具有显著的检索精度和节省检索时间。因此,基于cnn的哈希得到了越来越多的关注。
PQ 方法
CBIR 的另一种广泛使用的特征数据库搜索方法是 乘积量化 (PQ),它将特征空间分解为多个低维子空间的笛卡尔乘积,然后分别量化每个子空间。在训练阶段,每个子空间被聚类得到多个质心 (量化器),所有这些质心的笛卡尔积构成整个空间的密集分区,可以保证量化误差相对较小。量化学习后,对于给定的查询向量,可以通过查表来计算查询向量与数据库中每个向量的非对称距离
通常,PQ 是在非常低的内存存储和时间成本下生成大型码本的最佳选择。由于散列方法缺乏特征恢复的准确性,因此在某些情况下,最小化量化误差的乘积量化方法可以获得优于散列方法的准确性 [93]
与监督哈希方法一样,它们也可以分为传统的乘积量化方法和基于 CNN 的乘积量化方法。为了清楚起见,基于 PQ 的方法的分层类别如图 5 所示
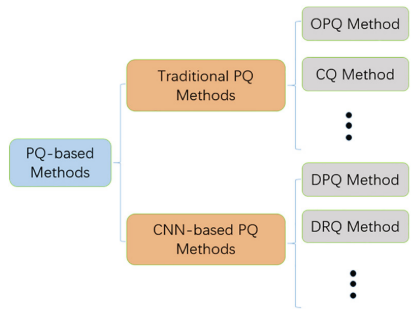
具有代表性的传统乘积量化方法是乘积量化(PQ)[94]、优化乘积量化(OPQ)[95]和复合量化(CQ)[96]。事实上,PQ[94]和 OPQ[95]首先将整个特征空间分成多个子空间,然后分别在每个子空间上执行类似的算法。CQ[96]使用与 OPQ 相同的策略学习足够的码本,但其码字的维度与原始特征的维度相同。这些传统的乘积量化方法能够以较低的存储空间和时间成本生成大码本
最近,基于 CNN 的乘积量化方法发展迅速。他们使用端到端的 cnn 一起执行图像特征学习和量化
- 深度量化网络 [97] 是第一个对分离良好的图像特征进行学习和量化的深度学习结构
- 深度视觉语义量化 [93] 使用 CQ 来量化分离的图像特征
- Yu 等 [98] 提出了一种可微量化方法
然而,上述方法有两个缺点。首先,如果我们想获得具有不同代码长度的二进制代码,他们需要训练许多模型。其次,高维向量空间的分解很棘手。为了解决这些问题,深度递归量化 (DRQ) [99] 和深度渐进量化 (DPQ) [100] 都做出了一些努力。
- DRQ [99] 使用深度量化方法来构造一个码本,该码本可以递归地用于生成顺序二进制代码
- DPQ[100] 提出了一种用于大规模图像检索的 PQ 替代模型。
5-应用
5-1-Fashion image retrieval
服装电子商务的快速发展 和 互联网上服装图像数据量的增加 使得服装实例级图像检索(Fashion Instance-level image Retrieval, FIR)越来越受到计算机视觉的关注
FIR 是寻找与任何查询图像相似的时尚图像,满足用户需求的任务。
FIR 主要涉及跨域的时尚图像检索,即匹配两种图像,一种是用户随意拍摄的,另一种是卖家专业拍摄的。由于服装物品的变形性很强,图像的视角变化剧烈,拍摄环境如光照、背景等也是多种多样的,FIR 一直被认为是一项具有挑战性的任务
过去十年该领域有很多实用的数据集,table 1 对他们做了整理和对比(见原文)
有许多深度学习的方法
略
5-2-Person Re-IDentification
人的再识别(Re-ID),也被称为人检索,是将同一人在不同视角下拍摄的图像进行匹配,通常被认为是图像检索的子问题。
Person Re-ID 可以在跨设备的图像视频中检索特定的行人目标,弥补了目前固定摄像头的视角限制。它在智能安防、智能视频监控、智能检索等方面有着广泛的应用。
- 由于背景和外观(如光照、姿态、遮挡、分辨率)的不同,来自不同摄像机视角的图像差异很大。
- 不同身份的相似图像之间存在一定的干扰。
- 人体姿势和人体遮挡的变化可能会使问题变得更加复杂。
为了应对这些挑战,人们从不同的理论角度进行了大量的努力
略
5-3-E-commerce product retrieval
在电子商务购物中,消费者通常不知道用来找到他们想要的商品的正确关键字。电子商务产品检索可以帮助消费者搜索到他们想要的产品。
然而,这项任务具有挑战性。首先,很难处理异质的图像数据,很难弥合用户实时拍摄的图像和在线图像之间的差距。其次,处理海量更新数据的大规模索引也不是一件容易的事情
5-4-Remote sensing image retrieval
因为遥感技术的提高,其可以用来处理很多问题如天气预报、气候监测、城市规划、地质分析、灾害监测、资源调查等。
其中,基于内容的遥感图像检索是有效利用这些遥感数据的关键问题。它能够从大规模的图像数据库中自动高效地检索出用户所需要的遥感图像,受到了国内外研究人员的广泛关注。
根据方法的改进,我们可以将过去十年中的 CBRSIR 方法分为两类:基于特征的 CBRSIR 方法和基于 Hash 的 CBRSIR 方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号