跟着李沐老师做BERT论文逐段精读(笔记)
论文地址 ; 中文翻译 ; 代码地址 ; 视频地址 ; 本篇大部分内容来源 。只做整理补充,推荐去看李沐老师原视频,讲的真的很好
建议学习顺序:5min全局理解 -> 李沐老师论文讲解 -> 图解or手推BERT -> 代码讲解 ,都强力安利
图解 BERT真的非常适合过完论文对每一个小 part 都有所感受以后做整体串联!!我可太喜欢这个 up 了
1-标题 + 作者
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- pre-training: 在一个大的数据集上训练好一个模型 pre-training,模型的主要任务是用在其它任务 training 上
- deep bidirectional transformers: 深的双向 transformers
- language understanding: 更广义,transformer 主要用在机器翻译 MT
- 总结:BERT:是用用深的、双向的、transformer 来做预训练,用来做语言理解的任务。
2-摘要
摘要第一段:和哪两篇工作相关,区别是什么:BERT 是在 GPT 和 ELMo 的基础上的改动。
新的语言表征模型 BERT: Bidirectional Encoder Representations from Transformer,是 Transformers 模型的双向编码表示。与 ELMo 和 Generative Pre-trained Transformer 不同:
- BERT 从无标注的文本中(jointly conditioning 联合左右的上下文信息)预训练得到无标注文本的 deep bidirectional representations
- GPT unidirectional,使用左边的上下文信息 预测未来
- BERT bidirectional,使用左右侧的上下文信息
- pre-trained BERT 可以通过加一个输出层来 fine-tune,不需要对特定任务的做架构上的修改就可以在在很多任务(问答、推理)有很不错的、state-of-the-art 的 效果
- ELMo based on RNNs, down-stream 任务需要调整架构
- GPT, down-stream 任务只需要改最上层
- BERT based on Transformers, down-stream 任务只需要调整最上层
可以说,BERT 具有预训练、深度、双向这几个特点
摘要第二段:BERT 的好处(实例)
simple and empirically powerful
- 在 11 个不同的任务上比较好,以及具体的对比结果(包括绝对精度和相对其他任务的精度)
3-Introduction
导言第一段:本篇论文关注的研究方向的一点点 background
- Language model pre-training 可以提升 NLP 任务的性能
- NLP 任务主要分两类:sentence-level tasks 句子级别的任务——情绪识别; token-level tasks 词级别的人物——NER (人名、街道名) 需要 fine-grained output
注意,NLP 预训练很早之前存在,BERT 使 NLP 预训练 出圈了
导言第二段:摘要第一段的扩充
- 常见的 pre-trained language representations 两类策略:
- 基于特征的
- 对
每一个下游的任务都去构造一个和这个任务相关的神经网络 - 训练好的 representation(如词嵌入等等)作为额外的特征,和输入一起放进模型,作为一个很好的特征表达
- 如 ELMo,使用 RNN
- 对
- 基于微调参数
- 预训练好的模型放在下游应用的时候只要改动最上层
- 预训练好的参数在下游微调一下
- GPT
- 基于特征的
介绍别人工作的目的:铺垫自己方法的好
- ELMo 和 GPT 预训练时 使用 单向的语言模型 unidirectional language model,使用相同的目标函数
- 毕竟语言模型是单向的、预测未来。不是给第 一句、第三句,预测第二句
导言第三段:当前相关技术的局限性
- 标准语言模型是 unidirectional 单向的,限制了模型架构的选择
- GPT 从左到右的架构,只能将输入的一个句子从左看到右。
- 然而对于句子情感分类任务:从左看到右、从右看到左 都应该是合法的。我输入的是完整的句子
- 哪怕是 token-level tasks,如问答 QA,也应该可以看完整个句子选答案,不是从左往右一步一步看。
- ∴ 如果能 incorporate context from both directions 看两方向的信息,能提升 任务性能。
已知相关工作的局限性,+ 解决局限性的想法 -- > 导言第四段: 如何解决?
BERT 通过 MLM(Masked language model) 带掩码的语言模型 作为预训练的目标,来减轻 语言模型的单向约束
- MLM 带掩码的语言模型做什么呢?
- 每次随机选输入的词源 tokens, 然后 mask 它们,目标函数是预测被 masked 的词;类似挖空填词、完形填空。
- MLM 和 standard language model (只看左边的信息)有什么区别?
- MLM 可以看 左右的上下文信息, pre-train deep bidirectional transformer 的基础
- BERT 除了 MLM 还有什么?
- NSP: next sentence prediction
- 判断两个句子是随机采样的 or 原文相邻,学习 sentence-level 的信息
导言第五段:文章的贡献
- 展示了 bidirectional 双向信息的重要性
- GPT 只用了 unidirectional 信息
- Peter 2018 也做了双向的尝试,但只是简单把
从左看到和 从右看到左的模型独立训练 + shallow concatenation 拼在一起 - BERT 在 bidirectional pre-training 的应用更好
- 假如预训练模型结果很好就不用对特定任务的架构等做这么多改动了
- BERT 是第一个微调模型,在一系列 sentence-level and token-level task 都取得了很好的成绩
- BERT 开源,随便用
4-结论
近期实验表明,非监督的预训练模型很好, 资源不多的任务也能
本文拓展前任的结果到 deep bidirectional architectures,使同样的预训练模型能够处理大量的 NLP 任务
近年来语言模型迁移学习的研究表明:
- 无监督的预训练对许多 语言理解系统 很重要,
- 对它们研究的发现使资源较少的任务也能从 deep unidirectional architectures 中获益
- 我们则将这些发现进一步普遍化 -> 深入到双向架构(即 deep bidirectional architectures),允许相同的预训练模型成功地处理一系列广泛的 NLP 任务
稍微总结
- ELMo 用了 bidirectional 信息,但架构是 RNN 比较老
- GPT 架构 Transformer 新,但只用了 unidirectional 信息
- BERT = ELMo 的 bidirectional 信息 + GPT 的新架构 transformer。毕竟语言任务很多并不是预测未来,而是完形填空
- 结合这俩,并证明双向有用
锐评:A + B 缝合工作 or C 技术解决 D 领域的问题,不要觉得想法小、不值得写出来;简单朴实的写出来。简单好用 说不定会出圈 😘
5-相关工作
2.1 Unsupervised Feature-based approaches
非监督的基于特征表示的工作:词嵌入、ELMo 等
单词表征学习是多年来较活跃的研究领域。预训练的词嵌入被认为是现代 NLP 系统的组成部分,与从头学习的嵌入相比提供了显着的改进
这些方法已经被推广到更粗的粒度,如句子嵌入或段落嵌入。与传统词嵌入一样,这些学习到的表征通常用作下游模型中的特征
ELMo将传统的词嵌入研究概括为不同维度。他们建议从语言模型中提取语境敏感型特征。把语境字词嵌入与现有任务特定架构集成时,ELMo 针对一些主要的 NLP 基准
2.2 Unsupervised Fine-tuning approaches
非监督预训练 -> 微调:GPT 等,一种源于语言模型(LMs)的迁移学习新趋势
产生 contextual token representations 的句子或文档 encoders 从未标记文本中预先训练,然后对有监督的下游任务进行微调
这些方法的优点是几乎不需要从头学习参数。部分基于这一优势,OpenAI GPT(Radford et al.,2018)在 GLUE 基准测试中的许多句子级任务上取得了前所未有的先进成果
2.3 Transfer Learning from Supervised Data
在有监督有标号的数据上做迁移学习
NLP 有监督 的大数据集:natural language inference and machine translation
CV 做的还不错,ImageNet 训练好、再做迁移
NLP 表现不那么好:可能差别确实很大,且 NLP 数据远远不够
BERT 发现:
- NLP 中,在无标号的大量数据集上训练的模型效果 > 有标号、但数据量少一些的数据集上训练效果
- 很多 CV 任务也开始采用这种想法,在大量无标记的图片上训练的模型
6-BERT 模型
BERT 有两个任务:预训练 + 微调
- pre-training: 使用 unlabeled data 训练
- fine-tuning: 采用 Bert 模型,但是权重都是预训练期间得到的
- 所有权重在微调的时候都会参与训练,用的是有标记的数据、
- 每一个下游任务都会常见一个 新的 BERT 模型,(由预训练参数初始化),但每一个下游任务会根据自己任务的 labeled data 来微调自己的 BERT 模型
预训练和微调不是 BERT 的创新,CV 里用的不少
李沐老师锐评:有关于预训练和微调的介绍 就很好,哪怕之前已经被使用。
如果假设读者都知道论文的技术,而只给 Ref 会让读者很懵。论文写作要自洽,简单的说明就好,避免读者不知道预训练和微调,增加理解文章的障碍。
预训练+微调示意图:
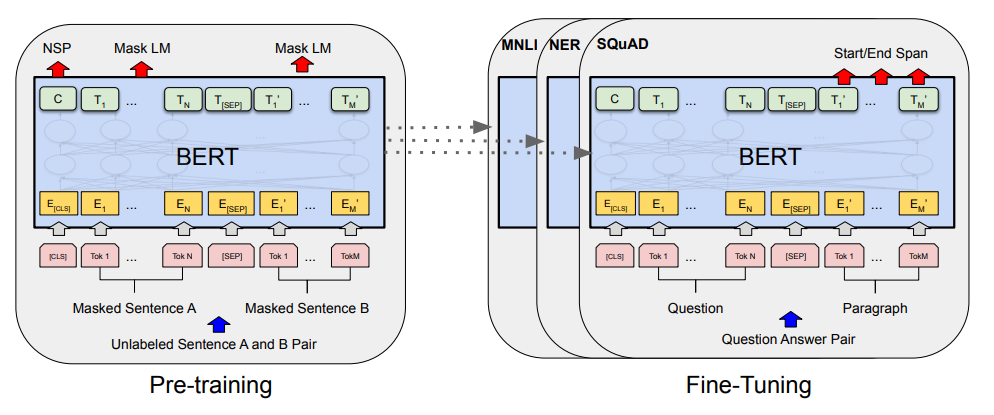
下游任务:创建同样的 BERT 的模型,权重的初始化值来自于 预训练好 的权重。
MNLI, NER, SQuAD 下游任务有 自己的 labeled data, 对 BERT 继续训练,得到各个下游任务自己的的 BERT 版本。
模型架构 Model Architecture
multi-layer bidirectional Transformer encoder:一个多层双向 Transformer 的解码器,基于 transformer 的论文和代码
主要调了三个参数:
- L: transform blocks 的个数
- H: hidden size 隐藏层大小
- A: 自注意力机制 multi-head 中 head 头的个数
主要两个 size:
- 调了 BERT_BASE (学习 1 亿参数,L=12, H=768, A=12)
- BERT_LARGE(3.4 亿参数, L=24, H=1024, A=16)
BERT 模型复杂度和层数 L 是线性关系, 和宽度 H 是 平方关系。
因为 深度 变成了 以前的两倍,在宽度上面也选择一个值,使得这个增加的平方大概是之前的两倍
H = 16,因为每个 head 的维度都固定在了 64。因为你的宽度增加了,所以 head 数也增加了

BERT_base 的参数选取 和 GPT 差不多,可以比较公平地对比模型;BERT_large 刷榜
把超参数换算成可学习参数 + transformer 架构复习
https://www.bilibili.com/video/BV1PL411M7eQ?t=1400.8
这篇讲的比较清楚: 一文懂“NLP Bert-base” 模型参数量计算
词向量的一个 remark: 词向量
输入输出(预训练&微调共通部分)
-
下游任务有处理一个句子、有的处理 2 个句子,BERT 能处理不同句子数量的下游任务,使输入可以是 a single sentence and a pair of sentences (Question answer)
- a single sentence: 一段连续的文字,不一定是真正上的语义上的一段句子
- 输入称为一个序列 sequence,可以是一个句子也可以是两个
-
这里和 transformer 不同
- transformer 预训练时候的输入是一个序列对。编码器和解码器分别会输入一个序列
- BERT 只有一个编码器,为了使 BERT 能处理两个句子的情况,需要把两个句子并成一个序列
Bert 切词
- WordPiece
- 如果按空格切词:一个词是一个 token。数据量大的时候,词典会特别大,到百万级别。可学习的参数基本都在嵌入层了
- 采用本方法:若某词出现概率不大,则只保留该词出现频率高的子序列(很可能是它的词根)
- 最终得到 30k token 经常出现的词(子序列)的字典
BERT 的输入序列构成
- [ CLS ] + [ SEP ]
- 序列开始永远是 [ CLS ] ,输出的是整个句子层面的信息 sequence representation
- BERT 使用的是 transformer 的 encoder,self-attention layer 会看输入的每个词和其它所有词的关系
- 就算 [ CLS ] 这个词放在我的第一个的位置,他也是有办法能看到之后所有的词。所以他放在第一个是没关系的,不一定要放在最后
- 句子结束要区分两个句子:两种方法
- 每个句子后 + [ SEP ] 表示 separate
- 学一个嵌入层 来表示 整个句子是第一句还是第二句 (好奢靡)
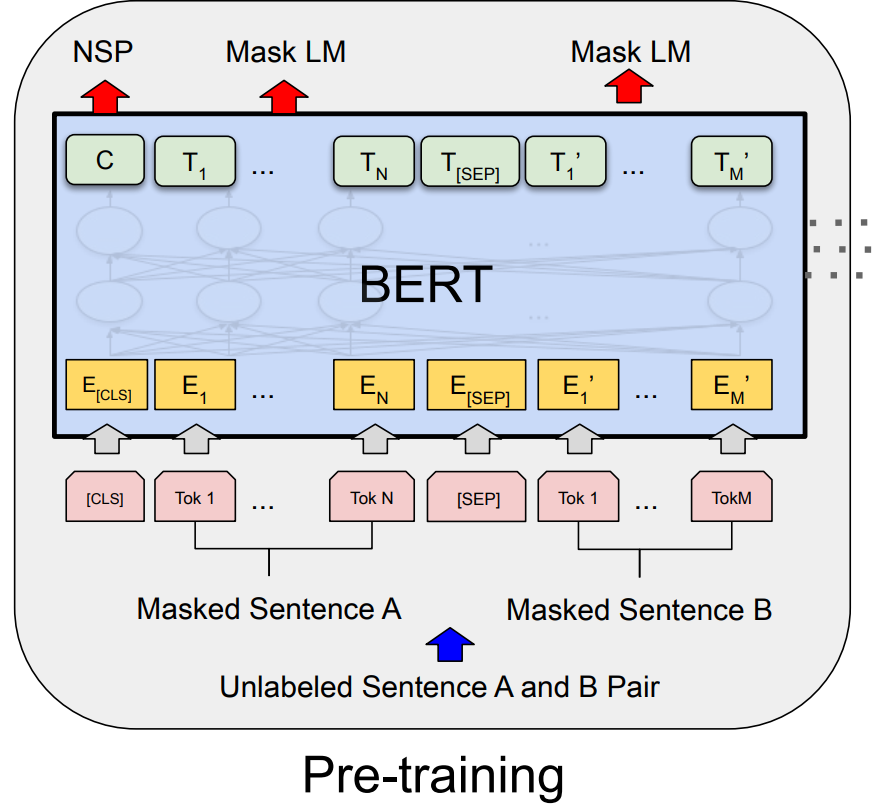
上图是预训练整体过程:
- 每一个 token 进入 BERT 得到 这个 token 的 embedding 表示。
- 整体进 BERT 然后输出一个结果序列
- 最后一个 transformer 块的输出,表示 这个词源 token 的 BERT 的表示。在后面再添加额外的输出层,来得到想要的结果
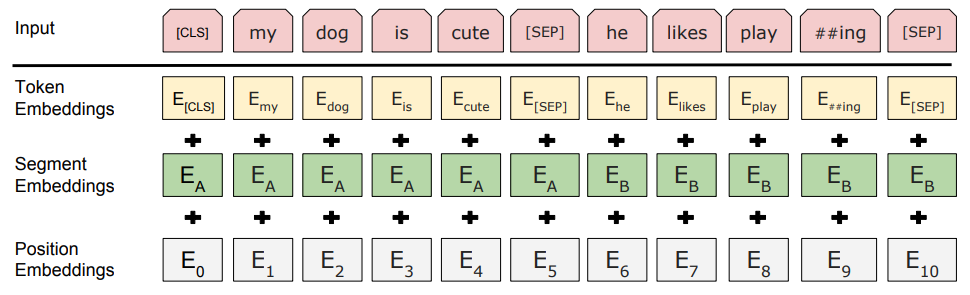
上图是 Input embeddings、得到这个 token 的 embedding 的过程:
- For a given token
- BERT input representation = token 本身的表示 + segment 句子的表示 + position embedding 位置表示
- token embedding:就是词源,每一个 token 有对应的词向量
- Segment 即到底是 A 句还是 B 句,学习得到
- Position 的输入是 token 词源在这个序列 sequence 中的位置信息。从 0 开始 1 2 3 4 --> Maximum。最终值是学习得到的(transformer 是给定的)
- 加起来的话每个向量的信息就会组合在一起
- 从【一个词源的序列】得到【一个向量的序列】,最终可以进入 transformer 块
1.Pre-training BERT
预训练的 key factors: 目标函数,预训练的数据
TASK1: Masked lm
为什么 bidirectional 好? MLM 是什么?完形填空
- 由 WordPiece 生成的词源序列中的词源 有 15% 的概率会随机替换成一个 mask
- 不过对于特殊的词源不做替换,i.e., 第一个词源 [ CLS ] 和中间的分割词源 [SEP]
- 如果输入序列长度是 1000 的话,要预测 150 个词。
- MLM 带来的问题:预训练和微调看到的数据不一样。预训练的输入序列有 15% 【MASK】,微调时的数据没有【MASK】,看到的数据不一样
- 解决方案:对于这 15% 被选中 masked 的词:
- 80% 的概率被替换为【MASK】
- 10% 换成 random token
- 10% 什么都不干,不改变原 token。但它的结果 $T_i$ 会被用来做预测(跟没 mask 类似?跟微调中的相同?)
- 采用 ablation study 来具体选择如何决定这 80 10 10 都是啥
- 解决方案:对于这 15% 被选中 masked 的词:

Task 2: 预测下一个 JuinNSP Next Sentence Prediction
- 在问答和自然语言推理里形式都是句子对
- 如果 BERT 能学习到 sentence-level 信息就很好
- 我们给定输入序列 2 个句子 A 和 B,50% 正例 50% 负
- 即 50% B 真的在 A 之后,50% 是 a random sentence 随机采样来的
- 正例:这个人要去一个商店,然后他买了一加仑的牛奶。IsNext
- 反例:这个人去了商店,然后企鹅是一种不能飞的鸟。NotNext
- 顺便可以看到 flightless 被 wordPiece 分成了两个词
- 即 50% B 真的在 A 之后,50% 是 a random sentence 随机采样来的

其实这两个任务在真实场景都不算实用,我们只是希望得到副产品——对语言的”感觉“、得到最好的句子中词的 representation。毕竟如此大量的数据我们不希望都去标注,那能学会这些句子内的联系对我们来说就很好
还有数据 Pre-training data
2 个数据集:BooksCorpus (800 M) + English Wikipedia (2500 M)
使用一篇一篇文章,而不是随机打断的句子。 a document-level corpus rather than a shuffled sentence-level corpus
transformer 确实可以处理较长的序列,一整个文本的输入当然效果会好一些
2.Fine-tuning BERT
介绍
- BERT 和一些基于 encoder-decoder 的架构有什么不一样(transformer 是 encoder-decoder)
- 整个句子对被放在一起输入 BERT,self-attention 能够在两个句子之间相互看
- Transformer 的 encoder 一般看不到 decoder
- BERT 在很多方面更好,但代价是 不能像 transformer 做机器翻译
- Transformer 的 decoder 可以通过掩码产生只看前面句子的效果从而做机器翻译
做下游任务
根据下游任务,设计我们任务相关的输入和输出

- 模型其实不怎么变,加一个输出层
softmax得到 标号label - 关键问题是怎么样把输入改成想要的句子对来输入?
- 我们只需将任务的特定输入和输出插入到 BERT 中,并端到端微调所有参数
- 有两个句子的话,当然就是句子 A 和 B,可以是句子理解句子对、假设-前提 或者 问答
- 只有一个句子的话,要做句子分类的话, B 就 886 了
- 比如说文本分类任务或者序列标记 text classification or sequence tagging
- 根据下游任务的要求,要么是输出 [CLS] representation is fed into an output layer for classification ——拿到第一个词源 [CLS] 对应的输出去做分类 such as entailment or sentiment analysis
- 或者是 the token representations are fed into an output layer for token-level tasks 拿到对应那些词源的输出做我们想要的 sequence tagging or question answering 输出,其实也差不多
- 记得最后加
softmax哦
顺便,微调比预训练便宜。TPU 1 hour, GPU a few hours.
7-实验
很重要的一点事写出了具体对每一个下游任务到底是怎么样构造输入输出
1.GLUE
General Language Understanding Evaluation (一般语言理解能力评估)
- 多个数据集
- sentence-level tasks
输出通过:
- [CLS] 的 BERT 输出 representation 向量 --> 学习一个输出层 W,用 softmax 分类得到 label
- $log(softmax(CW^T)$

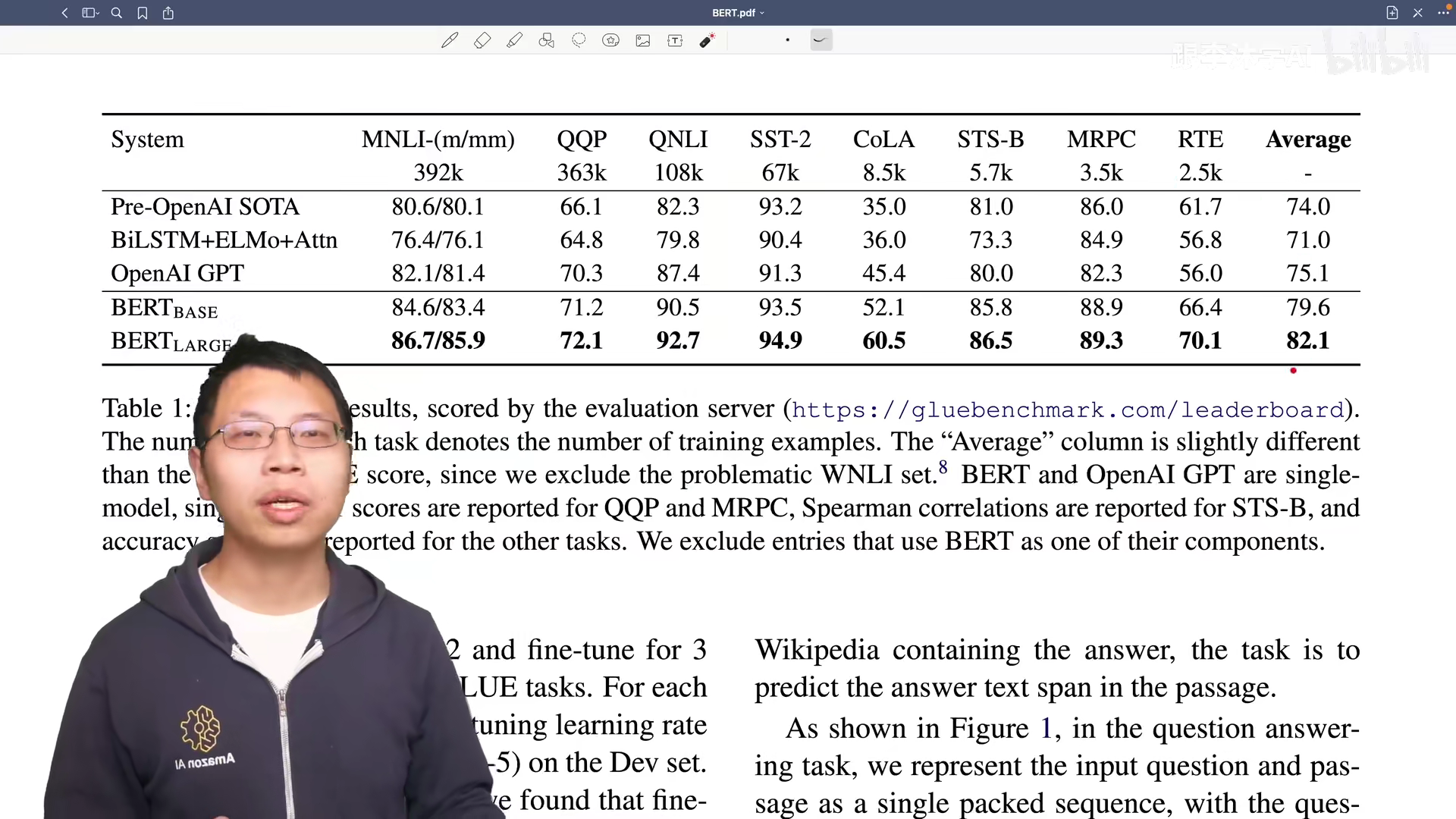
表 1 是 BERT 在 分类任务的表现
2.SQuAD v1.1
Stanford Question Answering Dataset 斯坦福问答数据集
- 给一段文字,问一个问题,答案在这段话内
- 需要你来判断答案的开始和结尾
- 也就是对每个词源 token,判断是不是答案的开始 or 结尾
- 具体来讲就是 学 2 个向量 S 和 E,分别对应这个词源 token 是答案开始词的概率 和 是答案结尾词的概率

具体计算 每个 token 是答案开始的概率,结尾词 E 的计算与之类似:
- S 和 第二句话的每个词源 token 相乘 再 softmax,得到归一化的概率
$$P_i = \frac{e ^ { S * T_i }}{\Sigma_j e ^ { S * T_j }}$$
本文微调时,epochs = 3(数据扫三遍), 学习率 = 5e-5, batch_size = 32 【意义备忘】
- 大家实验发现:用 BERT 做微调的时候,结果非常不稳定。同样的参数,同样的数据集,训练 10 遍,variance 方差特别大。
- 其实很简单,epochs 不够,3 太小了,可能要多学习几遍会好一点
- 另外优化器 optimizer 是 adam 的不完全版,在长时间训练的 BERT 没问题,训练时间不够的时候还是需要 完全版 adam
略了一个 3 SQuAD v2.0 表现也很不错
4.SWAG
Situations With Adversarial Generations 判断两个句子之间的关系,BERT 和之前的训练没多大区别,效果好。
总结:BERT 在不一样的数据集上,用起来很方便,效果很好。
输入表示成“一对句子的形式”,最后拿到 BERT 对应的输出,然后加一个输出层 softmax,完事了。
BERT 对 NLP 整个领域的贡献非常大,有大量的任务用一个相对简单、只改数据输入形式和最后加一个输出层,就可以效果很不错。
8-Ablation studies
消融研究
看 BERT 每一个组成部分的贡献。

- 没有 NSP
- LTR 从左看到右(无 MLM ) & 没有 NSP
- LTR 从左看到右(无 MLM ) & 没有 NSP + BiLSTM (从 ELMo 来的想法)
去掉任何一个组成部分,BERT 的效果都会有打折,特别是 MRPC。
Effect of Model Size
- BERT_base 110 M 可学习参数
- BERT_large 340 M 可学习参数
BERT 首先证明了大力出奇迹,引发了模型“大”战
现在:GPT-3 1000 亿可学习参数
Feature-based Approach with BERT
没有微调的 BERT,将 pre-trained 得到的 BERT 特征作为一个静态的特征输入,效果没有 + 微调好
用 BERT 需要微调
总结
老师锐评:写的就还可以
- 先写 BERT 和 ELMo (bidirectional + RNN)、GPT (unidirectional + transformer) 的区别
- 介绍 BERT 模型
- BERT 实验设置、效果好
- 结论突出 'bidirectional' 贡献
文章 1 个卖点,容易记。
但 BERT 是否要选择 'bidirectional' 双向性呢?
可以写,但也要写 双向性带来的不足是什么?
- GPT 用的是 decoder
- BERT 用的是 encoder,不好做 generative tasks:机器翻译、文本摘要
- 但是分类问题在 NLP 更常见。NLP 研究者喜欢 BERT,较容易的应用在 NLP 中自己想解决的问题。
再看 BERT,有一个完整的解决问题的思路 ---- 大家对 DL 的期望
- 训练一个很深、很宽的模型,在一个很大的数据集上预训练好;训练好的模型参数可以解决很多小的问题,通过微调提升小数据集上的性能
- 这个模型拿出来之后可以用在很多小的问题上,能够通过微调来全面提升这些小数据上的性能。这个在计算机视觉里面我们用了很多年了
BERT 把 CV 的套路搬到了 NLP,1 个 3 亿参数的模型,展示:模型越大、效果越好。大力出奇迹。
为什么 BERT 被记住?
BERT 用了 ELMo, GPT 更大的训练数据集,效果更好;BERE 也被更大的训练数据集和更大的模型超越。
BERT 的引用率是 GPT 的 10 倍,影响力 ✔

 浙公网安备 33010602011771号
浙公网安备 33010602011771号