爬取哔哩哔哩评论区(包含对评论的回复)并保存在xlsx中
第一次写爬虫,作业要求写报告,那就修改一下顺便发到这里啦。最后成型的代码大量参考了这里
代码地址在这里
要干什么
通过python爬虫抓取哔哩哔哩弹幕视频网任一视频下的评论内容并保存为表格(.xlsx)
主要的问题
获取请求URL
- 一开始没有查看api文档、直接尝试获取URL时已知出现问题,后来才知道要删除中间的jQuery段
存储
- 因为爬取的是评论区,常常有大段的文字,常用'/n'换行,常用的csv存储可能会因此结构混乱,所以想通过xlsx存储
- 但是常用的几种操作xlsx的库对于“添加”这一操作都非常困难,看了一会儿总觉得头大
- 寻找了很久发现pandas的数据表操作非常实用,格式规范、合并简单
- 但是json格式跟pandas常用的写入方式还是不太一样,不过还好python转换键值对比较方便,具体实现可以看下方
子评论
- 对评论的回复(下称“子评论”)常常被无视,它的请求URL和参数值都和父评论本身不一样
- 遍历他们并提取数据花费了一定的时间
爬取间隔
- 不是异步代码。没有header池的话一定要有时间间隔啊!!!!!!!!!!!!
网页分析
随意打开一个视频的评论区,按下f12打开控制台搜索相关内容,找到评论数据的保存格式,并在标头中找到对应的请求URL
查阅github上总结的api文档了解到各必要参数意义:
- next:页码
- type:默认为1
- oid:av号
- mode:查询模式(楼层、时间、热度)
- plat:默认为1
需要注意的是,中间的jQuery段需要删除才能获取请求
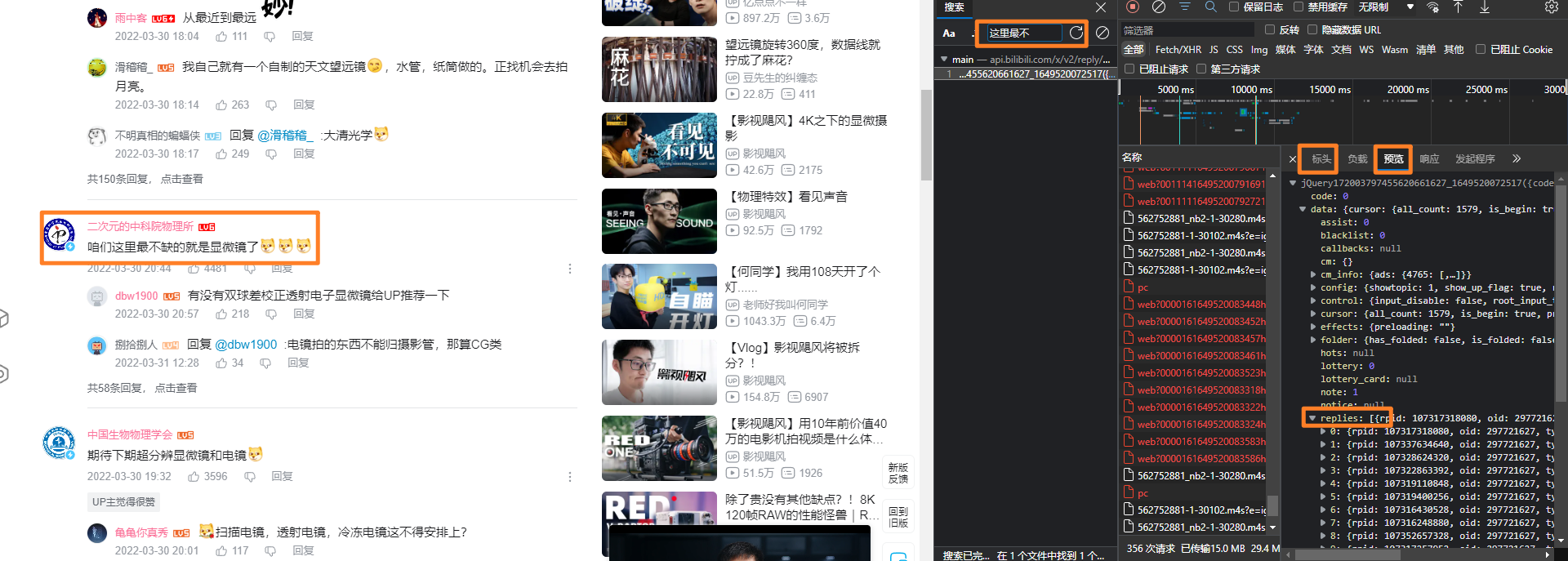
找到了目标地址和格式就可以开始写代码了
代码实现
没有太多特别的地方,函数互相调用导致拆开了分析不太方便,一次性附上了
"""
主要参考:https://blog.csdn.net/mlyde/article/details/118936871
query说明:https://www.bilibili.com/read/cv8325021/
通过向API发送请求获得json文件
请求地址:
https://api.bilibili.com/x/v2/reply?pn={1}&type={2}&oid={3}&sort={4}
"""
import requests
import os
import time
import json
import pandas as pd
from bilibili_api import video, sync # https://bili.moyu.moe/#/
# 全局变量
cookie = "最好修改成自己的,保留bili_jct、buvid3和SESSDATA,在终端查询或者直接点击浏览器地址栏的小锁找找都能找到"
file_dir = "./comment_data/"
bv = "BV号,链接也成"
comment_mode = 3 # mode是需要传入的api,规定了排序模式: 1:评论(楼层);2:最新评论(时间);3:热门评论(热度),不过1已经失效了
def b2a(bv_num):
"""
调用现成的bilibili库将用户输入的哔哩哔哩地址转为真正用于识别视频的oid(av号)
:param bv_num: 用户设定的哔哩哔哩视频BV号,每个bv参数名都不一样是因为pycharm一直提示我要从外部隐藏该名称……
:return: oid(av号)
"""
v = video.Video(bvid=bv_num)
info = sync(v.get_info())
return info.get('aid', "None")
def response_f(bv_id, next=0, mode=3):
"""
request网页提取出的返回父评论的函数,以json格式传输
:param bv_id: bv号
:param next: json中用来标注页码
:param mode: 所用的额排序模式
:return: 返回提取后的json
"""
api_url = 'https://api.bilibili.com/x/v2/reply/main'
url = 'https://www.bilibili.com/video/' + bv_id
av = b2a(bv_id) # 先转av号
# 复制的headers,user-agent和cookie是我自己的
headers = {
'accept': '*/*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'cookie': cookie,
'pragma': 'no-cache',
'referer': url,
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'script',
'sec-fetch-mode': 'no-cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36 Edg/100.0.1185.36',
}
# 定义所拆解内容
data = {
'jsonp': 'jsonp',
'next': next, # 页码
'type': '1',
'oid': av, # av号
'mode': mode, # 1:楼层大前小后, 2:时间晚前早后, 3:热门评论
'plat': '1',
'_': str(time.time() * 1000)[:13], # 时间戳
}
response = requests.get(api_url, headers=headers, params=data)
# 中文,不定义编码格式大概率会乱码
response.encoding = 'utf-8'
# 将得到的json文本转化为可读json,这段是复制的
if 'code' in response.text:
c_json = json.loads(response.text)
else:
c_json = {'code': -1}
if c_json['code'] != 0:
print('json error!')
print(response.status_code)
print(response.text)
return 0 # 读取错误
return c_json
def response_r(bv, rpid, pn=1):
"""
返回子评论json,和父评论方式基本相同但是参数不同,重写了一个,这里其实复用程度不是很够,可以写个循环+判断省略的,因为是作业就偷懒了
:param bv: bv号
:param rpid: 父评论的id
:param pn: 子评论的页码是通过pn判断的
:return: json格式的子评论
"""
r_api_url = 'https://api.bilibili.com/x/v2/reply/reply'
url = 'https://www.bilibili.com/video/' + bv
av = b2a(bv)
headers = {
'accept': '*/*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'cookie': cookie,
'pragma': 'no-cache',
'referer': url,
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'script',
'sec-fetch-mode': 'no-cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36',
}
data = {
'jsonp': 'jsonp',
'pn': pn, # page number
'type': '1',
'oid': av,
'ps': '10',
'root': rpid, # 父评论的rpid
'_': str(time.time() * 1000)[:13], # 时间戳
}
response = requests.get(r_api_url, headers=headers, params=data)
response.encoding = 'utf-8'
# 加载得到的json
if 'code' in response.text:
r_cjson = json.loads(response.text)
else:
r_cjson = {'code': -1}
if r_cjson['code'] != 0:
print('error!')
print(response.status_code)
print(response.text)
return 0 # 读取错误
return r_cjson
def parse_comment_r(bv, rpid, df):
"""
解析子评论json
:param bv: bv号
:param rpid: 父评论的id
:param df: pandas datagram,作为本程序的数据传递方式
:return: 返回修改后的df
"""
cr_json = response_r(bv, rpid)['data']
count = cr_json['page']['count']
for pn in range(1, count // 10 + 2):
time.sleep(0.1)
print('p%d %d ' % (pn, count), end='\r')
cr_json = response_r(bv, rpid, pn=pn)['data']
cr_list = cr_json['replies']
if cr_list: # 有时'replies'为'None'
for i in range(len(cr_list)):
comment_temp = [{
'time': time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(cr_list[i]['ctime'])), # 时间
'like': cr_list[i]['like'], # 赞数
'uid': cr_list[i]['member']['mid'], # uid
'name': cr_list[i]['member']['uname'], # 用户名
'sex': cr_list[i]['member']['sex'], # 性别
'content': '"' + cr_list[i]['content']['message'] + '"', # 子评论
}] # 保留需要的内容
df2 = pd.DataFrame(comment_temp)
df = pd.concat([df, df2], axis=0, ignore_index=True)
return df
def parse_comment_f(bv, df):
"""
解析父评论json
:param bv: bv号
:param df: pandas datagram,作为本程序的数据传递方式
:return: 返回修改后的df
"""
c_json = response_f(bv, mode=comment_mode)
if c_json:
# 父评论总数
try:
count_all = c_json['data']['cursor']['all_count']
print('comments:%d' % count_all)
except KeyError:
print('KeyError, 该视频可能没有评论!')
return '0', '2' # 找不到键值
else:
print('json错误')
return '1', '0' # json错误
# 开始序号
count_next = 0
# 存放原始json
all_json = ''
for page in range(min((count_all // 20 + 1),150)):
time.sleep(1)
print('page:%d' % (page + 1))
c_json = response_f(bv, count_next, mode=comment_mode)
all_json += str(c_json) + '\n'
if not c_json:
return 1 # json错误
count_next = c_json['data']['cursor']['next'] # 下一个的序号
# 评论列表
c_list = c_json['data']['replies']
# 有评论,就进入下面的循环保存
if c_list:
for i in range(len(c_list)):
comment_temp = [{
# 'floor': c_list[i]['floor'], # 楼层
'time': time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(c_list[i]['ctime'])), # 时间
'like': c_list[i]['like'], # 赞数
'uid': c_list[i]['member']['mid'], # uid
'name': c_list[i]['member']['uname'], # 用户名
'sex': c_list[i]['member']['sex'], # 性别
'content': c_list[i]['content']['message'], # 评论内容
}] # 保留需要的内容
# 若有子评论,记录rpid,爬取子评论
replies = False
replies = False
if c_list[i]['rcount'] or ('replies' in c_list[i] and c_list[i]['replies']):
replies = True
rpid = c_list[i]['rpid']
df = parse_comment_r(bv, rpid, df) # 如果有回复评论,爬取子评论
df2 = pd.DataFrame(comment_temp)
df = pd.concat([df, df2], axis=0, ignore_index=True)
if c_json['data']['cursor']['is_end']:
print('读取完毕,结束')
# 为最后一个json,结束爬取
break
else:
print('评论为空,结束!')
break
time.sleep(0.2)
return df, all_json
def main():
global file_dir
global bv
if '/' in bv or '?' in bv:
# 分解链接
bv = bv.split('/')[-1].split('?')[0]
# 处理存储路径
if file_dir == '':
file_dir = './'
elif file_dir[-1] != '/' or file_dir[-1] != '\\':
file_dir += '/'
if not os.path.exists(file_dir):
print('存储路径不存在', end='')
os.mkdir(file_dir)
print('已创建')
data0 = [{'time': '', 'like': '', 'uid': '', 'name': '', 'sex': '', 'content': ''}] # 行首
df = pd.DataFrame(data0)
df, all_json = parse_comment_f(bv, df)
df = df.drop(index=0) # 这种方式会有空行,把它干掉
# 保存
while True: # 使用while以便占用时可以关掉文件后继续操作而非必须从头执行
try:
df.to_excel("./%s/%s.xlsx" % (file_dir, bv))
break
except PermissionError:
input('文件被占用(关闭占用的程序后,回车重试)')
if __name__ == "__main__":
main()
print('== over! ==')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号