scrapy框架之item与pipelines
继续以起点小说为例子,我们要做的就是把对象存储到item(类似于一个字典)中,在通过pipelines持久化到txt文件中。
之前我们在运行爬虫的后面加“-o 爬虫名称” 这样很方便,但是也有很多的弊端,比如只能存为特定的格式,像txt这种就不可以。同时在使用pipelines存储前可以写一些存储前的操作。没有看过存储的小伙伴可以看一下这篇文章scrapy框架之生成存储文件json,xml、csv文件,废话不多说,直接开始!!
写item类
上次我们起点小说爬到是书名和作者,所以我们定义一个书名和作者。
import scrapy
class QidianItem(scrapy.Item):
bookName = scrapy.Field()
authors = scrapy.Field()
编写爬虫文件
我们要在爬虫文件中实例化Item对象,在把爬到的值赋值给item
import scrapy
from qidian.items import QidianItem
class QidianspiderSpider(scrapy.Spider):
name = 'qidianspider'
allowed_domains = ['www.qidian.com']
start_urls = ['https://www.qidian.com/rank/yuepiao/']
def parse(self, response):
names = response.xpath('//*[@id="book-img-text"]/ul/li[1]/div[2]//a/text()').extract()
authors = response.xpath('//*[@id="book-img-text"]/ul/li[1]/div[2]//text()').extract()
item = QidianItem() #实例化对象
for name,author in zip(names,authors):
item['bookName'] = name #把值添加到item对象中
item['authors'] = author
yield item #提交到管道
在settings文件中开启管道
记得要关闭ROBOTSTXT_OBEY,写好UA伪装,不懂得可以看scrapy框架之创建项目运行爬虫
ITEM_PIPELINES = {
'qidian.pipelines.QidianPipeline': 300,
}
简单测试一下看是否正确
在pipelines文件中写
class QidianPipeline:
def process_item(self, item, spider):
print(item)
return item
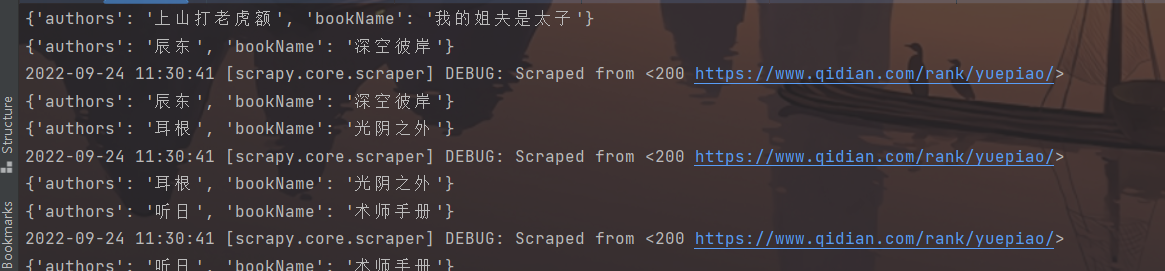
在管道中打印一下item,看否把数据提交到了管道,看到下图就表示成功把数据投入管道中
正式编写pipelines文件
class QidianPipeline(object):
def open_spider(self,spider):
self.fp = open('my.txt','w',encoding='utf-8')
print('爬虫开始~~')
def process_item(self, item, spider):
name = item['bookName']
authors = item['authors']
self.fp.write('书名:'+ name + '|' + '作者:' + authors + '\n')
return item
def close_spider(self, spider):
self.fp.close()
print('爬虫结束~~')
编写方法运行
from scrapy.cmdline import execute
execute('scrapy crawl qidianspider'.split())
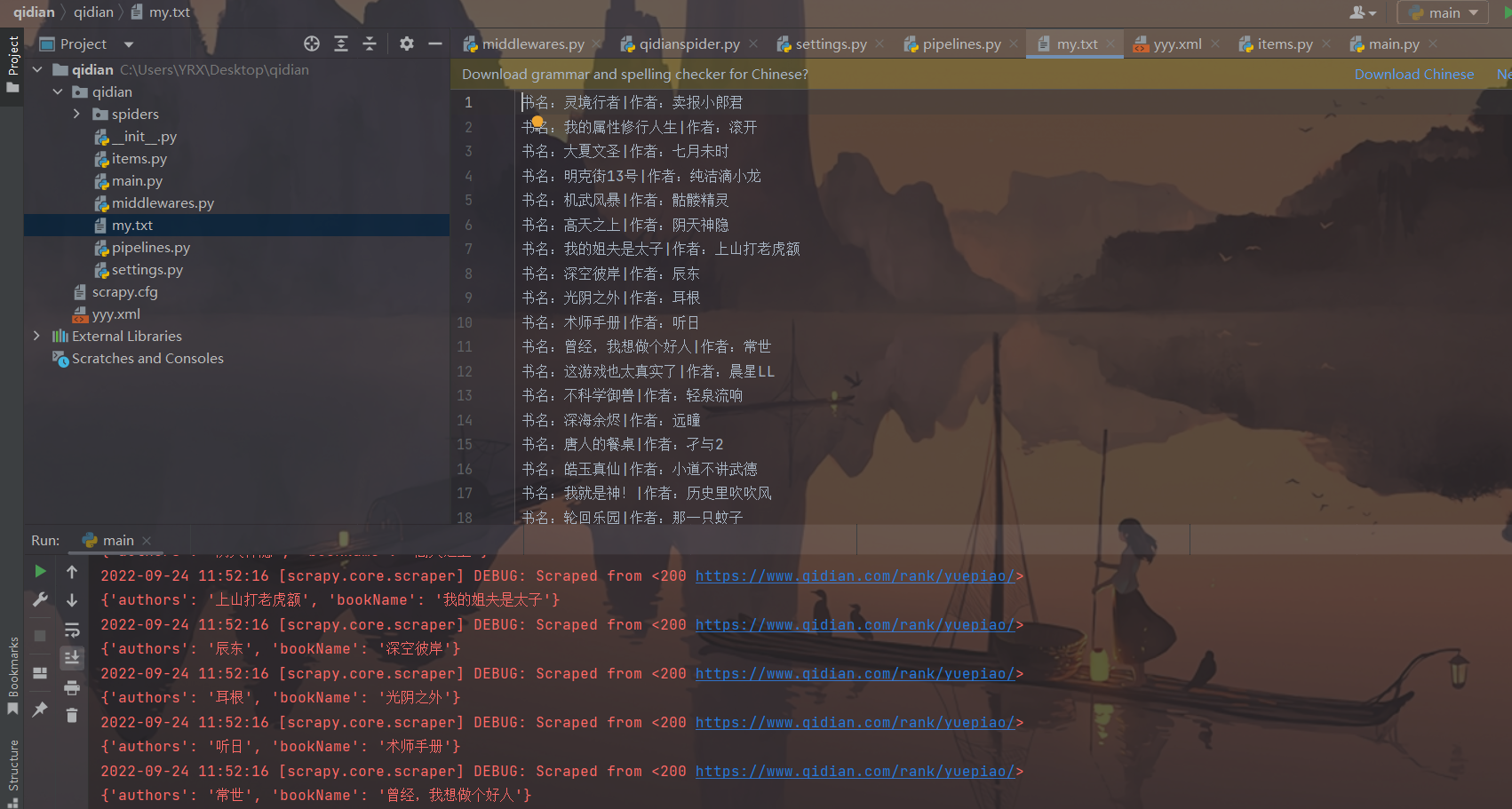
成果展示