scrapy框架之创建项目运行爬虫
创建scrapy
scrapy startproject 项目名称
创建蜘蛛(爬虫文件)
scrapy genspider 蜘蛛名称 网址
爬取网页(举百度的列子)
- 编写爬虫文件
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['baidu.com']
start_urls = ['http://www.baidu.com/']
def parse(self, response):
print(response.text)
还要改一下settings里的设置
# UA伪装(就是把爬虫文件伪装成为一个浏览器形式的访问)
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.42'
# robots.txt ,不遵守君子协议
ROBOTSTXT_OBEY = False
- 运行爬虫
1.窗口运行
scrapy crawl baidu
2.编写方法运行
main.py
from scrapy.cmdline import execute
execute('scrapy crawl baidu'.split())

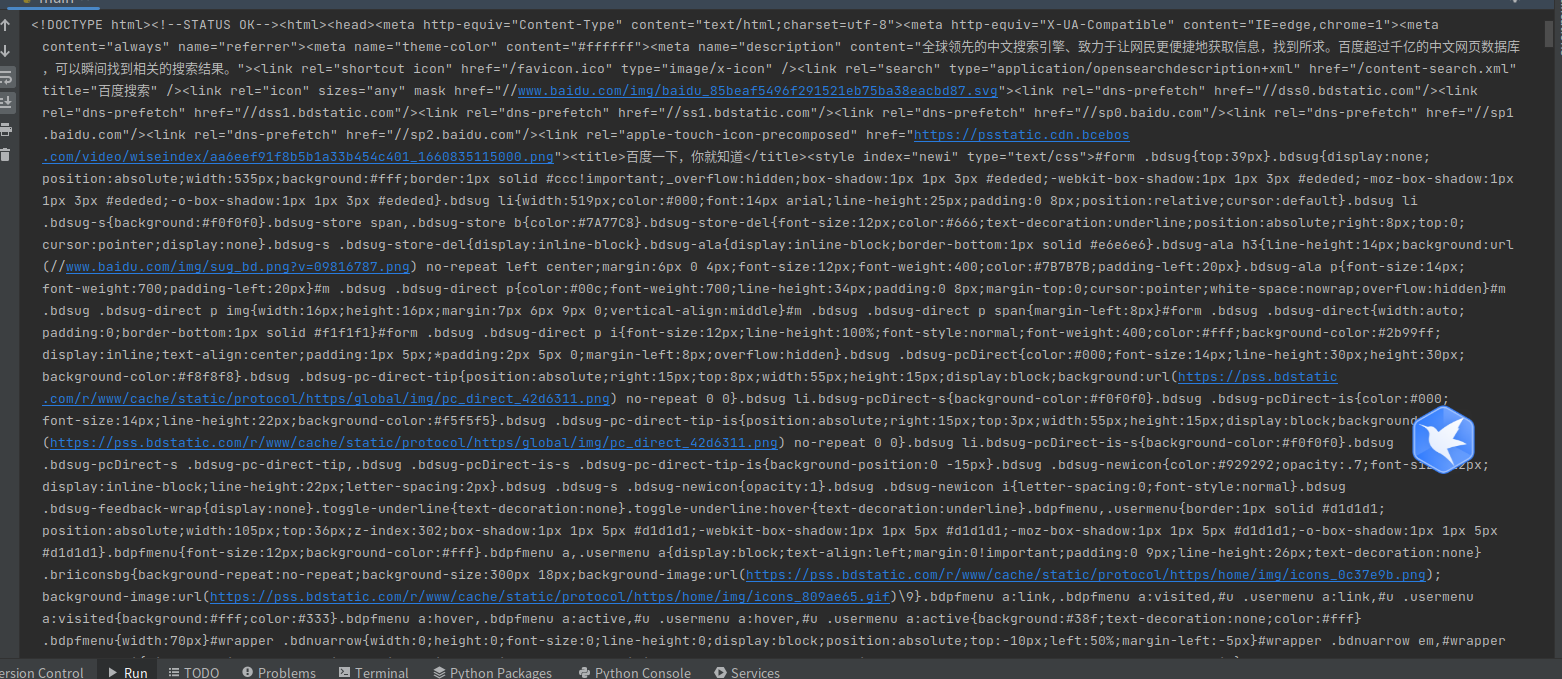
红色的不是报错,而是日志
效果展示


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构