Java爬虫项目实战(一)
主网站链接:
http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2015/index.html
主要jar包:
http://jsoup.org/packages/jsoup-1.8.1.jar
之前一节我们说过java爬虫从网络上利用jsoup获取网页文本,也就是说我们可以有三种方法获取html,一是根据url链接,二是从本地路径获取,三是通过字符串解析成html文档
在这里,我们利用前两种搭配使用:
先看本地是否存在需要的网页,如果不存在就通过url获取并保存在本地(下次就可以不需要重新从网络加载)
访问链接看到我们的网站是这样的:

利用谷歌浏览右键检查元素,我们注意观察黄色标记的部分:
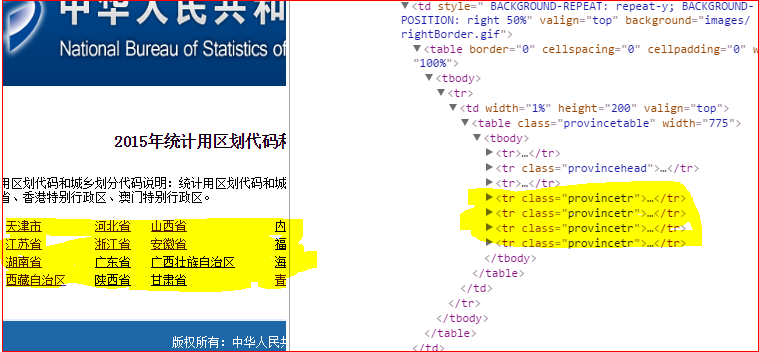

我们新建一个类,具体内容如下:
1 //根据url获取数据 2 public Document getHtmlTextByUrl(String url){ 3 Document document=null; 4 try{ 5 int i=(int)(Math.random()*1000);////做一个随机延时,防止网站屏蔽 6 while (i!=0) { 7 i--; 8 } 9 document=Jsoup.connect(url) 10 .data("query","Java") 11 .userAgent("Mozilla") 12 .cookie("auth", "token") 13 .timeout(300000).post(); 14 }catch(Exception e){ 15 e.printStackTrace(); 16 try{ 17 document=Jsoup.connect(url).timeout(5000000).get(); 18 }catch(Exception e1){ 19 e1.printStackTrace(); 20 } 21 } 22 return document; 23 } 24 25 //根据元素属性获取某个元素内的elements列表 26 public Elements getElementByClass(Document document,String className){ 27 Elements elements=null; 28 elements=document.select(className); 29 return elements; 30 } 31 32 public ArrayList getProvice(String url,String type){ 33 ArrayList result=new ArrayList(); 34 String classtype="."+type; 35 //从网络上获取网页 36 Document document=getHtmlTextByUrl(url); 37 if (document!=null) { 38 Elements elements=getElementByClass(document,classtype);// tr的集合 39 for(Element e:elements){// 依次循环每个元素,也就是一个tr 40 if(e!=null){ 41 for(Element ec:e.children()){// 一个tr的子元素td,td内包含a标签 42 String[] prv = new String[4]; 43 if(ec.children().first()!=null){ 44 prv[0]=url;// 原来的url 45 prv[1]=ec.children().first().ownText(); 46 System.out.println(prv[1]);//身份名称 47 48 String ownurl=ec.children().first().attr("abs:href"); 49 prv[2]=ownurl; 50 System.out.println(prv[2]); 51 52 prv[3]=type; 53 result.add(prv); 54 } 55 } 56 } 57 } 58 } 59 return result; 60 } 61 62 public static void main(String[] args) { 63 String url="http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2015/index.html"; 64 String type="provincetr"; 65 System.out.println(new Html().getProvice(url, type)); 66 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号