Xpath学习

一:基本操作
1 from lxml import etree 2 text = ''' 3 <div> 4 <ul> 5 <li class="item-0"><a href="link1.html">first item</li> 6 <li class="item-1"><a href="link2.html">second item</a></li> 7 <li class="item-inactive"><a href="link3.html">third item</a></li> 8 <li class="item-1"><a href="link4.html">fourth item</a></li> 9 <li class="item-0"><a href="link5.html">fifth item</a> 10 </ul> 11 </div> 12 ''' 13 # 调用HTML类进行初始化,这样就成功构造了一个Xpath解析对象 14 # 注意:HTML文本中最后一个li节点是没有闭合的,但是etree模块可以自动修正HTML文本 15 html = etree.HTML(text) 16 # 调用tostring()方法即可输出修正后的HTML代码,但是结果是bytes类型 17 result = etree.tostring(html) 18 # 这里利用decode()方法将其转成str类型 19 # 输出结果可以看到经过处理之后,li节点标签被补全,并且还自动添加了body、html节点 20 print(result.decode('utf-8'))
运行结果:
1 "D:\Program Files (x86)\python\python.exe" E:/python/python爬虫/xpath/a1.py 2 <html><body><div> 3 <url> 4 <li class="item-0"><a href="link1.html">first item</a></li> 5 <li class="item-1"><a href="link2.html">second item</a></li> 6 <li class="item-inactive"><a href="link3.html">third item</a></li> 7 <li class="item-1"><a href="link4.html">fourth item</a></li> 8 <li class="item-0"><a href="link5.html">fifth item</a> 9 10 </li></ul></div> 11 </body></html> 12 13 Process finished with exit code 0
读取文本进行解析:
1 from lxml import etree 2 # 直接读取文本进行解析 3 html = etree.parse('./test.html', etree.HTMLParser()) 4 # 调用tostring()方法即可输出修正后的HTML代码,但是结果是bytes类型 5 result = etree.tostring(html) 6 # 输出结果多了一个DOCTYPE声明,不过对解析无任何影响 7 print(result.decode('utf-8'))
运行结果:
"D:\Program Files (x86)\python\python.exe" E:/python/python爬虫/xpath/a2.py <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org/TR/REC-html40/loose.dtd"> <html><body><div> <url> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> </li></url></div> </body></html> Process finished with exit code 0
二、选取节点:-所有节点
1 from lxml import etree 2 # 直接读取文本进行解析 3 html = etree.parse('./test.html', etree.HTMLParser()) 4 # //表示从当前节点选取子孙节点,*表示匹配所有节点,也就是整个HTML文本都会被获取 5 result = html.xpath('//*') 6 # 返回结果是一个列表,每个元素都是Element类型 7 print(result)
运行结果:
1 "D:\Program Files (x86)\python\python.exe" E:/python/python爬虫/xpath/a3.py 2 [<Element html at 0x2786c00>, <Element body at 0x2786cc0>, <Element div at 0x2786d00>, <Element ul at 0x2786d40>, <Element li at 0x2786d80>, <Element a at 0x2786e00>, <Element li at 0x2786e40>, <Element a at 0x2786e80>, <Element li at 0x2786ec0>, <Element a at 0x2786dc0>, <Element li at 0x2786f00>, <Element a at 0x2786f40>, <Element li at 0x2786f80>, <Element a at 0x2786fc0>] 3 4 Process finished with exit code 0
可以看到返回形式是一个列表,每个元素都是Element类型,后面跟了节点的名称,如:html、body、ul、li等,所有节点都包含在列表中了
在匹配时指定节点名称:获取或有li节点
1 from lxml import etree 2 # 直接读取文本进行解析 3 html = etree.parse('./test.html', etree.HTMLParser()) 4 # 这里选取所有li节点,可以使用//,然后直接加上节点名称即可 5 result = html.xpath('//li') 6 # 返回结果是一个列表,每个元素都是Element类型 7 print(result) 8 # 由于返回结果是列表,如果要取出其中一个对象,可以使用索引的方法 9 print(result[0])
运行结果:
1 "D:\Program Files (x86)\python\python.exe" E:/python/python爬虫/xpath/a3.py 2 [<Element li at 0x2766dc0>, <Element li at 0x2766e00>, <Element li at 0x2766e40>, <Element li at 0x2766e80>, <Element li at 0x2766ec0>] 3 <Element li at 0x2766dc0> 4 5 Process finished with exit code 0
三、选取节点:-子节点
获取li节点下所有a节点
1 from lxml import etree 2 # 直接读取文本进行解析 3 html = etree.parse('./test.html', etree.HTMLParser()) 4 # 选择li节点的所有直接a子节点 5 # 这里通过追加/a即选择了所有li节点的所有直接a子节点 6 # 因为//li表示选中所有li节点,/a用于选中li节点的所有直接子节点a, 7 # 二者组合在一起即获取了所有li节点的所有直接a子节点 8 result = html.xpath('//li/a') 9 # 返回结果是一个列表,每个元素都是Element类型 10 print(result)
运行结果:
1 "D:\Program Files (x86)\python\python.exe" E:/python/python爬虫/xpath/a4.py 2 [<Element a at 0x2786f40>, <Element a at 0x2786f80>, <Element a at 0x2786fc0>, <Element a at 0x278a040>, <Element a at 0x278a080>] 3 4 Process finished with exit code 0
另一种写法:
获取ul节点下所有a节点
1 from lxml import etree 2 # 直接读取文本进行解析 3 html = etree.parse('./test.html', etree.HTMLParser()) 4 # 选择ul节点下所有子孙a节点 5 result = html.xpath('//ul//a') 6 print(result)
运行结果:
1 "D:\Program Files (x86)\python\python.exe" E:/python/python爬虫/xpath/a5.py 2 [<Element a at 0x2772fc0>, <Element a at 0x277a040>, <Element a at 0x277a080>, <Element a at 0x277a0c0>, <Element a at 0x277a100>] 3 4 Process finished with exit code 0
但是如果这里用//u/a,就无法获取任何结果了,因为/用于获取直接子节点,而在ul节点下没有直接的a子节点,只有li节点,所以无法匹配到任何结果。
因此,这里要注意//与/的区别,其中/用于获取直接子节点,//用于获取之孙节点
四、选取节点:-父节点
首先选中href为link4.html的a节点,然后再获取其父节点,然后再获取其class属性
1 from lxml import etree 2 text = """ 3 <div> 4 <ul> 5 <li class="item-0"><a href="link1.html">first item</a></li> 6 <li class="item-1"><a href="link2.html">second item</a></li> 7 <li class="item-inactive"><a href="link3.html">third item</a></li> 8 <li class="item-1"><a href="link4.html">fourth item</a></li> 9 <li class="item-0"><a href="link5.html">fifth item</a> 10 </ul> 11 </div> 12 """ 13 # 调用HTML类进行初始化,这样就成功构造了一个Xpath解析对象 14 # 注意:HTML文本中最后一个li节点是没有闭合的,但是etree模块可以自动修正HTML文本 15 html = etree.HTML(text) 16 # 首先选中href为link4.html的a节点,然后再获取其父节点,然后再获取其class属性 17 result = html.xpath('//a[@href = "link4.html"]/../@class') 18 print(result)
运行结果:
1 "D:\Program Files (x86)\python\python.exe" E:/python/python爬虫/xpath/a6.py 2 ['item-1'] 3 4 Process finished with exit code 0
例二:选择class为item-0的两个li节点
1 from lxml import etree 2 text = """ 3 <div> 4 <ul> 5 <li class="item-0"><a href="link1.html">first item</a></li> 6 <li class="item-1"><a href="link2.html">second item</a></li> 7 <li class="item-inactive"><a href="link3.html">third item</a></li> 8 <li class="item-1"><a href="link4.html">fourth item</a></li> 9 <li class="item-0"><a href="link5.html">fifth item</a> 10 </ul> 11 </div> 12 """ 13 # 调用HTML类进行初始化,这样就成功构造了一个Xpath解析对象 14 # 注意:HTML文本中最后一个li节点是没有闭合的,但是etree模块可以自动修正HTML文本 15 html = etree.HTML(text) 16 # 选择class为item-0的两个li节点 17 result = html.xpath('//li[@class = "item-0"]') 18 print(result)
运行结果:
1 "D:\Program Files (x86)\python\python.exe" E:/python/python爬虫/xpath/a7.py 2 [<Element li at 0x2769080>, <Element li at 0x27690c0>] 3 4 Process finished with exit code 0
五、获取文本
方法:利用XPath的text()方法获取节点中的文本
有两种方法
比如要获取li节点的文本,
一是先获取其内部a节点,再获取a节点的文本。/表示从根节点选取
二是使用获取到li节点后使用//来获取文本,//表示从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
方法一:
1 from lxml import etree 2 text = """ 3 <div> 4 <ul> 5 <li class="item-0"><a href="link1.html">first item</a></li> 6 <li class="item-1"><a href="link2.html">second item</a></li> 7 <li class="item-inactive"><a href="link3.html">third item</a></li> 8 <li class="item-1"><a href="link4.html">fourth item</a></li> 9 <li class="item-0"><a href="link5.html">fifth item</a></li> 10 </ul> 11 </div> 12 """ 13 # 调用HTML类进行初始化,这样就成功构造了一个Xpath解析对象 14 # 注意:HTML文本中最后一个li节点是没有闭合的,但是etree模块可以自动修正HTML文本 15 html = etree.HTML(text) 16 # 选择class为item-0的两个li节点,再获取内部的a子节点,再获取文本 17 result = html.xpath('//li[@class = "item-0"]/a/text()') 18 print(result)
运行结果:
1 "D:\Program Files (x86)\python\python.exe" E:/python/python爬虫/xpath/a7.py 2 ['first item', 'fifth item'] 3 4 Process finished with exit code 0
方法二:
1 from lxml import etree 2 text = """ 3 <div> 4 <ul> 5 <li class="item-0"><a href="link1.html">first item</a></li> 6 <li class="item-1"><a href="link2.html">second item</a></li> 7 <li class="item-inactive"><a href="link3.html">third item</a></li> 8 <li class="item-1"><a href="link4.html">fourth item</a></li> 9 <li class="item-0"><a href="link5.html">fifth item</a></li> 10 </ul> 11 </div> 12 """ 13 # 调用HTML类进行初始化,这样就成功构造了一个Xpath解析对象 14 # 注意:HTML文本中最后一个li节点是没有闭合的,但是etree模块可以自动修正HTML文本 15 html = etree.HTML(text) 16 # 选择class为item-0的两个li节点,不考虑位置来获取文本,使用// 17 result = html.xpath('//li[@class = "item-0"]//text()') 18 print(result)
运行结果:
1 "D:\Program Files (x86)\python\python.exe" E:/python/python爬虫/xpath/a7.py 2 ['first item', 'fifth item'] 3 4 Process finished with exit code 0
六、获取属性
例一:
1 from lxml import etree 2 text = """ 3 <div> 4 <ul> 5 <li class="item-0"><a href="link1.html">first item</a></li> 6 <li class="item-1"><a href="link2.html">second item</a></li> 7 <li class="item-inactive"><a href="link3.html">third item</a></li> 8 <li class="item-1"><a href="link4.html">fourth item</a></li> 9 <li class="item-0"><a href="link5.html">fifth item</a></li> 10 </ul> 11 </div> 12 """ 13 html = etree.HTML(text) 14 result = html.xpath('//li/a/@href') 15 print(result)
运行结果:
1 "D:\Program Files (x86)\python\python.exe" E:/python/python爬虫/xpath/a8.py 2 ['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html'] 3 4 Process finished with exit code 0
注意:这里是通过@href来获取节点的href属性,此处和属性匹配的方法不同,属性匹配时中括号加属性名和值来限定某个属性,如[@href="link1.html"],
而此处的@href指的是获取节点的某个属性。
七、属性多值匹配
有时候,某些节点的某个属性可能有多个值,这时候用之前的属性匹配就无法匹配了
例如:
1 from lxml import etree 2 text = """ 3 <li class="li li-first"><a href="link.html">first item</a></li> 4 """ 5 html = etree.HTML(text) 6 result = html.xpath('//li[@class = "li"]/a/text()') 7 print(result)
运行结果:
1 "D:\Program Files (x86)\python\python.exe" E:/python/python爬虫/xpath/a9.py 2 [] 3 4 Process finished with exit code 0
这时候要用contains()方法,代码改写为:
1 from lxml import etree 2 text = """ 3 <li class="li li-first"><a href="link.html">first item</a></li> 4 """ 5 html = etree.HTML(text) 6 result = html.xpath('//li[contains(@class, "li")]/a/text()') 7 print(result)
运行结果:
1 "D:\Program Files (x86)\python\python.exe" E:/python/python爬虫/xpath/a9.py 2 ['first item'] 3 4 Process finished with exit code 0
这样通过contains()方法,第一个参数传入属性名称,第二个参数传入属性值,只要此属性值包含所传入的属性值,就可以匹配成功。
此种方法在某个节点的某个属性有多个值的时候经常用到。
八、多属性同时匹配
根据多个属性确定一个节点,此时就需要同时匹配多个属性。可以使用运算符and来连接
1 from lxml import etree 2 text = """ 3 <li class="li li-first" name = "item"><a href="link.html">first item</a></li> 4 """ 5 html = etree.HTML(text) 6 # 使用and连接选择的两个属性 7 result = html.xpath('//li[contains(@class, "li") and @name ="item"]/a/text()') 8 print(result)
运行结果:
1 "D:\Program Files (x86)\python\python.exe" E:/python/python爬虫/xpath/a10.py 2 ['first item'] 3 4 Process finished with exit code 0
九、按序选择
有时候,我们再选择的时候某些属性可能同时匹配了多个节点,但是我们只想要其中的某个节点,这时候可以利用中括号传入索引的方法来获取特定的次序的节点
1 from lxml import etree 2 text = """ 3 <div> 4 <ul> 5 <li class="item-0"><a href="link1.html">first item</a></li> 6 <li class="item-1"><a href="link2.html">second item</a></li> 7 <li class="item-inactive"><a href="link3.html">third item</a></li> 8 <li class="item-1"><a href="link4.html">fourth item</a></li> 9 <li class="item-0"><a href="link5.html">fifth item</a></li> 10 </ul> 11 </div> 12 """ 13 14 html = etree.HTML(text) 15 # 选择第一个li节点,注意[]中传入的是1,而不是0 16 result = html.xpath('//li[1]/a/text()') 17 print(result) 18 # 选择最后一个li节点,[]中传入last() 19 result = html.xpath('//li[last()]/a/text()') 20 print(result) 21 print('*'*20) 22 # 选择位置小于3的li节点,也就是前两个li节点,[]总传入position()<3 23 result = html.xpath('//li[position()<3]/a/text()') 24 print(result) 25 # 选择倒数第三个li节点,[]中传入last()-2即可。因为last()是最后一个,所以last()-2就是倒数第三个 26 result = html.xpath('//li[last()-2]/a/text()') 27 print(result)
运行结果:
1 "D:\Program Files (x86)\python\python.exe" E:/python/python爬虫/xpath/a11.py 2 ['first item'] 3 ['fifth item'] 4 ******************** 5 ['first item', 'second item'] 6 ['third item'] 7 8 Process finished with exit code 0
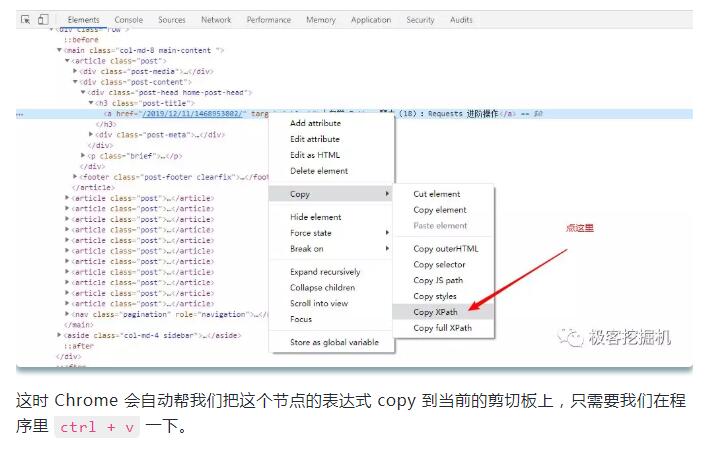
十、选择路径的时候利用浏览器直接复制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号