
【cs231n】lecture 7 课程笔记
课程7 训练神经网络(part 2)
key: 更好的优化 正则化 迁移学习
Fancier Optimization 更好的优化(如何更新梯度)
1.从SGD(随机梯度下降)出发:
- 问题一:以二维为例(两个都是权重,一个是w1,一个是w2),在w1上前进很慢,在w2上前进很快,导致曲折前进,推广到高维,每个方向的前进情况都不同,会是更复杂的情况
- 问题二:会在局部最小值点和鞍点(非最大非最小,但梯度为零)困住,后者在高纬度中更常见
- 问题三:梯度常用小批量数据估算,会有噪音,造成梯度想全局最小前进更曲折
2.带动量(Momentum)的SGD:加入一个不随时间变化的速度,用这个速度代替原来的梯度,其中包含对梯度的估计,在这个速度的方向上步进,ρ为摩擦系数,用来衰减这个速度

- 实际上就是人为加了一个速度,可以冲过局部最小和鞍点,就像小球下山,可以更快到达底部
3.带Nestreov动量的SGD:中间用了一个换元法将式子简化表达;包含了当前速度与之前速度的误差修正

- 实际上是在速度方向上步进后,再决定此处的梯度
4.AdaGrad:加入梯度的平方项并不断叠加,计算时除一下,加一个很小的常数是为了不会除零
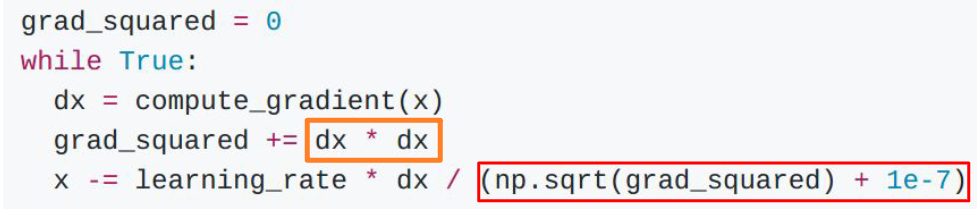
- 效果:以两个维度为例,一个变化很大,平方之后再除,会得到一个小的结果,另一个反之,就是把影响分散平均了
- 时间变长之后步长会越来越小,一般不怎么用
5.RMSProp(AdaGrad的变体,针对步长进行改变):
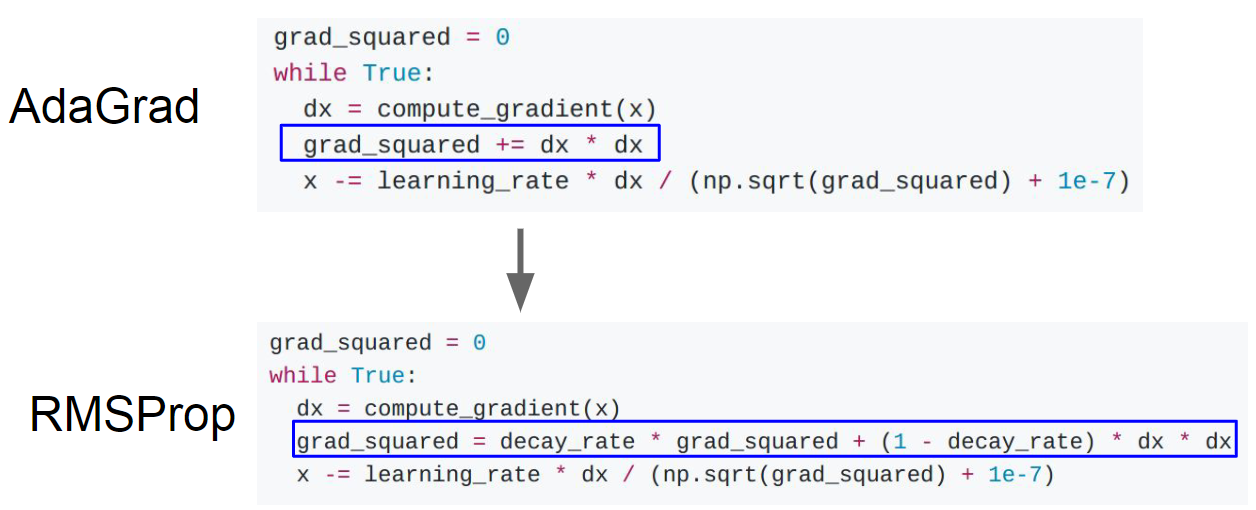
- 实际上就是让梯度平方按照一定比例下降,会产生一种损失函数一直在调整的效果
6.Adam(几乎是最合适的方法):综合了前两个的优点,类似带动量的RMSProp,第一个动量是梯度加权和,第二个动量是梯度平方的动态近似值,但不直接用,用无偏估计项避免初始化在较差的解空间中(因为初始时第二动量会很小,造成很长的步长)

- 一些好用的初始化值:
![image]()

7.对于学习率:不要一直用一个,可以试试衰减之,但这是二阶的超参,不要开始就用;带动量的SGD常用,Adam不常用
8.二阶优化:前面都是求导,也可以用二阶直接求极值,不用超参、不用学习率,但是计算量太大,只能逼近之,用拟牛顿法
小结:Adam是很好的选择;二阶优化需要承受更新全部数据,且随机性不高,因为对随机性处理不够
正则化
1.一个问题:我们真的关心的是训练与验证的gap嘛?并不,我们关心在没见过的data上的表现(测试)
2.模型集成:独立训练好几个模型,测试时平均他们的结果(可以提高2%);
- 高级用法:可以不用全部训练,只是使用单个模型几个snapshot
- Polyak Averaging方法:对不同时刻的不同模型参数求指数衰减平均值,得到平滑的集成模型,再用这些平滑衰减后的参数
3.另一个问题:如恶化提高单一模型的表现? 正则化
4.方法1:加入正则项,即给损失函数加正则项,常用的如下

5.方法2:Dropout方法,随机把一些神经元的激活值置零,一般用在FC层,若是卷积层就把某个特征映射全部置零;
-
设置一个概率p,一般为0.5
-
可能的原理1:防止神经元之间互相拟合,也防止了过拟合
-
可能的原理2:如同训练了一个网络合集,每一种置零方案都对应一个子网络
-
问题:引入了随机性,即p,需要在测试时通过积分边缘化“平均”掉这个随机性,但无法真的做到,只能做逼近;这里以单神经元为例,测试时正常算,训练时乘以p;实际就是对激活值进行放缩,让训练和测试一致
![image]()
![image]()
-
反转dp:训练时除以p,多个操作但是没关系,测试时少个操作
![image]()



6.方法3:(思想:训练时引入随机性,测试时中和掉)Batch Normalization 批量归一化也可以实现这个效果,训练时使用随机小批量数据,测试时使用基于全局的data,区别在于dp有p可以控制,bn没有
7.方法4:数据增强,训练时对图片进行水平翻转、随机裁切等操作,测试时使用固定方法裁切(四个角、中心、反转),注意大小问题,还有各种方式,色彩抖动等
8.方法5:DropConnect,把权重W中的一些值置零
9.方法6:部分最大池化 Fractional Max Pooling(不常用)
10.方法7:随机深度 Stochastic Depth
迁移学习 Transfer Learing (针对数据较少时)
1.思想:自己的数据集很小,可以用大的数据集预训练一下,再用自己的微调
2.方式:
- 数据越少,选择训练的层数越少(一般是FC),微调时使用原学习率的十分之一比较好
- 自己的数据集与大的数据集相似时,可用大的训练上层的线性分类器;自己的数据也不少时,可以用自己的微调
3.使用:很普遍,都会用imagenet预训练一下,如果类别相差太大,做一些修改再用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号